






IO
磁盘通常是计算机最慢的子系统,也是最容易出现性能瓶颈的地方,因为磁盘离 CPU 距离最远而且 CPU 访问磁盘要涉及到机械操作,比如转轴、寻轨等。访问硬盘和访问内存之间的速度差别是以数量级来计算的,就像1天和1分钟的差别一样。要监测 IO 性能,有必要了解一下基本原理和 Linux 是如何处理硬盘和内存之间的 IO 的。
Memory 提到了内存和硬盘之间的 IO 是以页为单位来进行的,在 Linux 系统上1页的大小为 4K。可以用以下命令查看系统默认的页面大小:
$ /usr/bin/time -v date
...
Page size (bytes): 4096
...缺页中断
Linux 利用虚拟内存极大的扩展了程序地址空间,使得原来物理内存不能容下的程序也可以通过内存和硬盘之间的不断交换(把暂时不用的内存页交换到硬盘,把需要的内 存页从硬盘读到内存)来赢得更多的内存,看起来就像物理内存被扩大了一样。事实上这个过程对程序是完全透明的,程序完全不用理会自己哪一部分、什么时候被 交换进内存,一切都有内核的虚拟内存管理来完成。当程序启动的时候,Linux 内核首先检查 CPU 的缓存和物理内存,如果数据已经在内存里就忽略,如果数据不在内存里就引起一个缺页中断(Page Fault),然后从硬盘读取缺页,并把缺页缓存到物理内存里。缺页中断可分为主缺页中断(Major Page Fault)和次缺页中断(Minor Page Fault),要从磁盘读取数据而产生的中断是主缺页中断;数据已经被读入内存并被缓存起来,从内存缓存区中而不是直接从硬盘中读取数据而产生的中断是次 缺页中断.
上面的内存缓存区起到了预读硬盘的作用,内核先在物理内存里寻找缺页,没有的话产生次缺页中断从内存缓存里找,如果还没有发现的话就从硬盘读取.很 显然,把多余的内存拿出来做成内存缓存区提高了访问速度,这里还有一个命中率的问题,运气好的话如果每次缺页都能从内存缓存区读取的话将会极大提高性能。 要提高命中率的一个简单方法就是增大内存缓存区面积,缓存区越大预存的页面就越多,命中率也会越高。下面的 time 命令可以用来查看某程序第一次启动的时候产生了多少主缺页中断和次缺页中断:
$ /usr/bin/time -v date
...
Major (requiring I/O) page faults: 1
Minor (reclaiming a frame) page faults: 260
...File Buffer Cache
从上面的内存缓存区(也叫文件缓存区 File Buffer Cache)读取页比从硬盘读取页要快得多,所以 Linux 内核希望能尽可能产生次缺页中断(从文件缓存区读),并且能尽可能避免主缺页中断(从硬盘读),这样随着次缺页中断的增多,文件缓存区也逐步增大,直到系 统只有少量可用物理内存的时候 Linux 才开始释放一些不用的页。我们运行 Linux 一段时间后会发现虽然系统上运行的程序不多,但是可用内存总是很少,这样给大家造成了 Linux 对内存管理很低效的假象,事实上 Linux 把那些暂时不用的物理内存高效的利用起来做预存(内存缓存区)呢。下面打印的是的一台 Sun 服务器上的物理内存和文件缓存区的情况:
$ cat /proc/meminfo
MemTotal: 8182776 kB
MemFree: 3053808 kB
Buffers: 342704 kB
Cached: 3972748 kB这台服务器总共有 8GB 物理内存(MemTotal),3GB 左右可用内存(MemFree),343MB 左右用来做磁盘缓存(Buffers),4GB 左右用来做文件缓存区(Cached),可见 Linux 真的用了很多物理内存做 Cache,而且这个缓存区还可以不断增长。
Linux 中内存页面有三种类型:
- Read pages只读页(或代码页)
- 那些通过主缺页中断从硬盘读取的页面,包括不能修改的静态文件、可执行文件、库文件等。当内核需要它们的时候把它们读到 内存中,当内存不足的时候,内核就释放它们到空闲列表,当程序再次需要它们的时候需要通过缺页中断再次读到内存。
- Dirty pages,脏页
- 指那些在内存中被修改过的数据页,比如文本文件等。这些文件由 pdflush 负责同步到硬盘,内存不足的时候由 kswapd 和 pdflush 把数据写回硬盘并释放内存。
- Anonymous pages,匿名页
- 那些属于某个进程但是又和任何文件无关联,不能被同步到硬盘上,内存不足的时候由 kswapd 负责将它们写到交换分区并释放内存。
IO’s Per Second(IOPS)
每次磁盘IO请求都需要一定的时间,和访问内存比起来这个等待时间简直难以忍受。在一台 2001 年的典型 1GHz PC 上,磁盘随机访问一个 word 需要 8,000,000 nanosec = 8 millisec,顺序访问一个 word 需要 200 nanosec;而从内存访问一个 word 只需要 10 nanosec.(数据来自:Teach Yourself Programming in Ten Years)这个硬盘可以提供 125 次 IOPS(1000 ms / 8 ms)。
顺序 IO 和 随机 IO
IO 可分为 顺序IO 和 随机IO 两种,性能监测前需要弄清楚系统偏向顺序 IO 的应用还是随机 IO 应用。顺序 IO 是指同时顺序请求大量数据,比如数据库执行大量的查询、流媒体服务等,顺序 IO 可以同时很快的移动大量数据。可以这样来评估 IOPS 的性能,用每秒读写 IO 字节数除以每秒读写 IOPS 数,rkB/s 除以 r/s,wkB/s 除以 w/s. 下面显示的是连续2秒的 IO 情况,可见每次 IO 写的数据是增加的(45060.00 / 99.00 = 455.15 KB per IO,54272.00 / 112.00 = 484.57 KB per IO)。相对随机 IO 而言,顺序 IO 更应该重视每次 IO 的吞吐能力(KB per IO):
$ iostat -kx 1
avg-cpu: %user %nice %system %iowait %steal %idle
0.00 0.00 2.50 25.25 0.00 72.25
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await svctm %util
sdb 24.00 19995.00 29.00 99.00 4228.00 45060.00 770.12 45.01 539.65 7.80 99.80
avg-cpu: %user %nice %system %iowait %steal %idle
0.00 0.00 1.00 30.67 0.00 68.33
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await svctm %util
sdb 3.00 12235.00 3.00 112.00 768.00 54272.00 957.22 144.85 576.44 8.70 100.10随机 IO 是指随机请求数据,其 IO 速度不依赖于数据的大小和排列,依赖于磁盘的每秒能 IO 的次数,比如 Web 服务、Mail 服务等每次请求的数据都很小,随机 IO 每秒同时会有更多的请求数产生,所以磁盘的每秒能 IO 多少次是关键。
$ iostat -kx 1
avg-cpu: %user %nice %system %iowait %steal %idle
1.75 0.00 0.75 0.25 0.00 97.26
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await svctm %util
sdb 0.00 52.00 0.00 57.00 0.00 436.00 15.30 0.03 0.54 0.23 1.30
avg-cpu: %user %nice %system %iowait %steal %idle
1.75 0.00 0.75 0.25 0.00 97.24
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await svctm %util
sdb 0.00 56.44 0.00 66.34 0.00 491.09 14.81 0.04 0.54 0.19 1.29按照上面的公式得出:436.00 / 57.00 = 7.65 KB per IO,491.09 / 66.34 = 7.40 KB per IO. 与顺序 IO 比较发现,随机 IO 的 KB per IO 小到可以忽略不计,可见对于随机 IO 而言重要的是每秒能 IOPS 的次数,而不是每次 IO 的吞吐能力(KB per IO)。
各种IO监视工具在Linux IO 体系结构中的位置
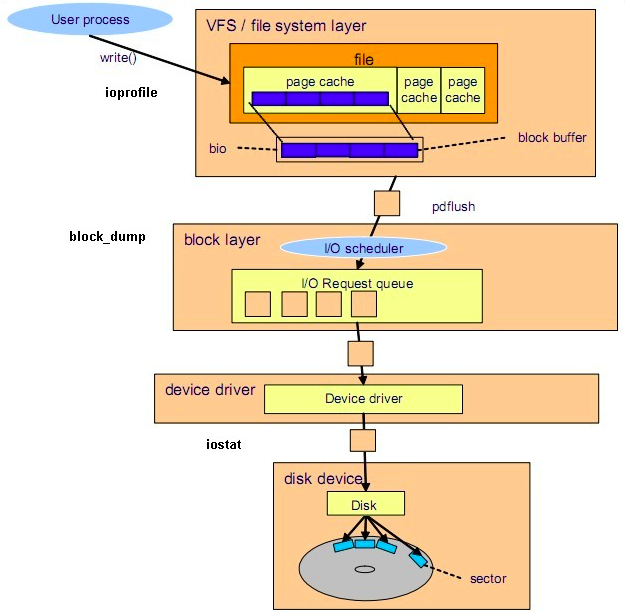
系统级IO监控
iostat
[root@jiangyi01.sqa.zmf /data]
#dd if=/dev/zero of=./bigfile bs=1K count=100000000
^C8588301+0 records in
8588301+0 records out
8794420224 bytes (8.8 GB) copied, 30.9121 s, 284 MB/s[root@jiangyi01.sqa.zmf /home/ahao.mah]
#iostat -dxm 1
Device: rrqm/s wrqm/s r/s w/s rMB/s wMB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
sdb 271.00 6749.00 170.00 901.00 1.75 30.04 60.79 7.49 6.89 9.40 6.42 0.46 49.00
sda 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
sdk 253.00 6749.00 178.00 903.00 1.70 30.05 60.16 12.65 11.61 10.19 11.89 0.67 72.00
sdj 264.00 6737.00 174.00 915.00 1.73 29.92 59.52 11.11 9.99 10.03 9.98 0.57 62.00
sde 406.00 6862.00 185.00 899.00 2.32 30.46 61.93 11.02 10.12 7.45 10.67 0.55 59.60
sdl 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
sdg 284.00 6731.00 180.00 904.00 1.74 29.77 59.52 10.03 9.06 8.00 9.27 0.53 57.30
sdd 366.00 6749.00 179.00 887.00 2.15 29.79 61.36 11.93 11.05 12.45 10.77 0.60 64.00
sdi 143.00 6757.00 174.00 891.00 1.18 29.87 59.70 12.27 11.26 17.69 10.01 0.62 66.20
sdc 448.00 6893.00 167.00 850.00 2.29 30.36 65.75 18.87 16.65 30.11 14.00 0.79 80.40
sdf 256.00 6773.00 169.00 838.00 1.67 29.77 63.94 12.69 12.33 16.56 11.47 0.64 64.60
sdh 169.00 6790.00 188.00 843.00 1.33 29.96 62.16 18.25 17.36 26.18 15.39 0.74 76.70
md0 0.00 0.00 3.00 46195.00 0.01 269.77 11.96 0.00 0.00 0.00 0.00 0.00 0.00- %util
- 代表磁盘繁忙程度。100% 表示磁盘繁忙, 0%表示磁盘空闲。但是注意,磁盘繁忙不代表磁盘(带宽)利用率高
- 代表磁盘繁忙程度。100% 表示磁盘繁忙, 0%表示磁盘空闲。但是注意,磁盘繁忙不代表磁盘(带宽)利用率高
- argrq-sz
- 提交给驱动层的IO请求大小,一般不小于4K,不大于max(readahead_kb, max_sectors_kb),可用于判断当前的IO模式,一般情况下,尤其是磁盘繁忙时, 越大代表顺序,越小代表随机
- svctm
- 一次IO请求的服务时间,对于单块盘,完全随机读时,基本在7ms左右,既寻道+旋转延迟时间
注: 各统计量之间关系
%util = ( r/s + w/s) * svctm / 1000 # 队列长度 = 到达率 * 平均服务时间
avgrq-sz = ( rMB/s + wMB/s) * 2048 / (r/s + w/s) # 2048 为 1M / 512进程级IO监控
iotop
这两个命令,都可以按进程统计IO状况,因此可以回答你以下二个问题
- 当前系统哪些进程在占用IO,百分比是多少?
- 占用IO的进程是在读?还是在写?读写量是多少?
[root@jiangyi01.sqa.zmf /var/log/journal]
#iotop
Total DISK READ : 14.92 K/s | Total DISK WRITE : 276.12 M/s
Actual DISK READ: 14.92 K/s | Actual DISK WRITE: 0.00 B/s
TID PRIO USER DISK READ DISK WRITE SWAPIN IO> COMMAND
4438 be/4 root 7.46 K/s 3.73 K/s 0.00 % 0.94 % DragoonAgent
22210 be/4 root 7.46 K/s 276.11 M/s 0.00 % 0.03 % dd if=/dev/zero of=./bigfile bs=1K count=100000000
1 be/4 root 0.00 B/s 0.00 B/s 0.00 % 0.00 % systemd --switched-root --system --deserialize 21
2 be/4 root 0.00 B/s 0.00 B/s 0.00 % 0.00 % [kthreadd]
3 be/4 root 0.00 B/s 0.00 B/s 0.00 % 0.00 % [ksoftirqd/0]
5 be/0 root 0.00 B/s 0.00 B/s 0.00 % 0.00 % [kworker/0:0H]
7 rt/4 root 0.00 B/s 0.00 B/s 0.00 % 0.00 % [migration/0]
8 be/4 root 0.00 B/s 0.00 B/s 0.00 % 0.00 % [rcu_bh][root@jiangyi01.sqa.zmf /data]
#dd if=/dev/zero of=./bigfile bs=1K count=100000000
^C2329821+0 records in
2329821+0 records out
2385736704 bytes (2.4 GB) copied, 9.17054 s, 260 MB/spidstat
[root@jiangyi01.sqa.zmf /var/log/journal]
#pidstat -d 1
10:30:15 AM UID PID kB_rd/s kB_wr/s kB_ccwr/s Command
10:30:16 AM 0 22847 12.00 283240.00 0.00 dd
10:30:16 AM 0 25240 0.00 4.00 0.00 staragent-ppfpidstat -u -r -d -t 1
# -d IO 信息,
# -r 缺页及内存信息
# -u CPU使用率
# -t 以线程为统计单位
# 1 1秒统计一次block_dump, iodump
iotop和 pidstat 用着很爽,但两者都依赖于/proc/pid/io文件导出的统计信息, 这个对于老一些的内核是没有的,比如rhel5u2
[root@jiangyi01.sqa.zmf /var/log/journal]
#cat /proc/24092/io
rchar: 319688167
wchar: 433
syscr: 1836114
syscw: 12
read_bytes: 0
write_bytes: 28479488
cancelled_write_bytes: 0因此只好用以上2个穷人版命令来替代:
echo 1 > /proc/sys/vm/block_dump # 开启block_dump,此时会把io信息输入到dmesg中
watch -n 1 "dmesg -c | grep -oP \"\w+\(\d+\): (WRITE|READ)\" | sort | uniq -c"
echo 0 > /proc/sys/vm/block_dump # 不用时关闭业务级IO监控
ioprofile
ioprofile 命令本质上是 lsof + strace, 具体下载可见 http://code.google.com/p/maatkit/
ioprofile 可以回答你以下三个问题:
- 当前进程某时间内,在业务层面读写了哪些文件(read, write)?
- 读写次数是多少?(read, write的调用次数)
- 读写数据量多少?(read, write的byte数)
假设某个行为会触发程序一次IO动作,例如: "一个页面点击,导致后台读取A,B,C文件"
./io_event # 假设模拟一次IO行为,读取A文件一次, B文件500次, C文件500次
ioprofile -p `pidof io_event` -c count # 读写次数
ioprofile -p `pidof io_event` -c times # 读写耗时
ioprofile -p `pidof io_event` -c sizes # 读写大小总结:
iostat 统计的是通用块层经过合并(rrqm/s, wrqm/s)后,直接向设备提交的IO数据,可以反映系统整体的IO状况,但是有以下2个缺点:
- 距离业务层比较遥远,跟代码中的write,read不对应(由于系统预读 + pagecache + IO调度算法等因素, 也很难对应)
- 是系统级,没办法精确到进程,比如只能告诉你现在磁盘很忙,但是没办法告诉你是谁在忙,在忙什么?
SWAP
当系统没有足够物理内存来应付所有请求的时候就会用到 swap 设备,swap 设备可以是一个文件,也可以是一个磁盘分区。不过要小心的是,使用 swap 的代价非常大。如果系统没有物理内存可用,就会频繁 swapping,如果 swap 设备和程序正要访问的数据在同一个文件系统上,那会碰到严重的 IO 问题,最终导致整个系统迟缓,甚至崩溃。swap 设备和内存之间的 swapping 状况是判断 Linux 系统性能的重要参考,我们已经有很多工具可以用来监测 swap 和 swapping 情况,比如:top、cat /proc/meminfo、vmstat 等:
当前正在使用的swap有哪些?
[root@jiangyi01.sqa.zmf /home/ahao.mah]
#swapon -s
Filename Type Size Used Priority
/dev/sda3 partition 2097148 924 -1$ cat /proc/meminfo
MemTotal: 8182776 kB
MemFree: 2125476 kB
Buffers: 347952 kB
Cached: 4892024 kB
SwapCached: 112 kB
...
SwapTotal: 4096564 kB
SwapFree: 4096424 kB
...














 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









