







摘要: 原创出处 http://www.iocoder.cn/Sharding-JDBC/result-merger/ 「芋道源码」欢迎转载,保留摘要,谢谢!
本文主要基于 Sharding-JDBC 1.5.0 正式版
- 1. 概述
- 2. MergeEngine
- 3. OrderByStreamResultSetMerger
- 4. GroupByStreamResultSetMerger
- 5. GroupByMemoryResultSetMerger
- 6. IteratorStreamResultSetMerger
- 7. LimitDecoratorResultSetMerger
- 666. 彩蛋
???关注**微信公众号:【芋道源码】**有福利:
- RocketMQ / MyCAT / Sharding-JDBC 所有源码分析文章列表
- RocketMQ / MyCAT / Sharding-JDBC 中文注释源码 GitHub 地址
- 您对于源码的疑问每条留言都将得到认真回复。甚至不知道如何读源码也可以请教噢。
- 新的源码解析文章实时收到通知。每周更新一篇左右。
- 认真的源码交流微信群。
1. 概述
本文分享查询结果归并的源码实现。
正如前文《SQL 执行》提到的**“分表分库,需要执行的 SQL 数量从单条变成了多条”,多个SQL执行**结果必然需要进行合并,例如:
SELECT * FROM t_order ORDER BY create_time
在各分片排序完后,Sharding-JDBC 获取到结果后,仍然需要再进一步排序。目前有 分页、分组、排序、聚合列、迭代 五种场景需要做进一步处理。当然,如果单分片SQL执行结果是无需合并的。在《SQL 执行》不知不觉已经分享了插入、更新、删除操作的结果合并,所以下面我们一起看看查询结果归并的实现。
Sharding-JDBC 正在收集使用公司名单:传送门。
? 你的登记,会让更多人参与和使用 Sharding-JDBC。传送门
Sharding-JDBC 也会因此,能够覆盖更多的业务场景。传送门
登记吧,骚年!传送门
2. MergeEngine
MergeEngine,分片结果集归并引擎。
// MergeEngine.java
/**
* 数据库类型
*/
private final DatabaseType databaseType;
/**
* 结果集集合
*/
private final List<ResultSet> resultSets;
/**
* Select SQL语句对象
*/
private final SelectStatement selectStatement;
/**
* 查询列名与位置映射
*/
private final Map<String, Integer> columnLabelIndexMap;
public MergeEngine(final DatabaseType databaseType, final List<ResultSet> resultSets, final SelectStatement selectStatement) throws SQLException {
this.databaseType = databaseType;
this.resultSets = resultSets;
this.selectStatement = selectStatement;
// 获得 查询列名与位置映射
columnLabelIndexMap = getColumnLabelIndexMap(resultSets.get(0));
}
/**
* 获得 查询列名与位置映射
*
* @param resultSet 结果集
* @return 查询列名与位置映射
* @throws SQLException 当结果集已经关闭
*/
private Map<String, Integer> getColumnLabelIndexMap(final ResultSet resultSet) throws SQLException {
ResultSetMetaData resultSetMetaData = resultSet.getMetaData(); // 元数据(包含查询列信息)
Map<String, Integer> result = new TreeMap<>(String.CASE_INSENSITIVE_ORDER);
for (int i = 1; i <= resultSetMetaData.getColumnCount(); i++) {
result.put(SQLUtil.getExactlyValue(resultSetMetaData.getColumnLabel(i)), i);
}
return result;
}
- 当 MergeEngine 被创建时,会传入
resultSets结果集集合,并根据其获得columnLabelIndexMap查询列名与位置映射。通过columnLabelIndexMap,可以很方便的使用查询列名获得在返回结果记录列( header )的第几列。
MergeEngine 的 #merge() 方法作为入口提供查询结果归并功能。
/**
* 合并结果集.
*
* @return 归并完毕后的结果集
* @throws SQLException SQL异常
*/
public ResultSetMerger merge() throws SQLException {
selectStatement.setIndexForItems(columnLabelIndexMap);
return decorate(build());
}
#merge()主体逻辑就两行代码,设置查询列位置信息,并返回合适的归并结果集接口( ResultSetMerger ) 实现。
2.1 SelectStatement#setIndexForItems()
// SelectStatement.java
/**
* 为选择项设置索引.
*
* @param columnLabelIndexMap 列标签索引字典
*/
public void setIndexForItems(final Map<String, Integer> columnLabelIndexMap) {
setIndexForAggregationItem(columnLabelIndexMap);
setIndexForOrderItem(columnLabelIndexMap, orderByItems);
setIndexForOrderItem(columnLabelIndexMap, groupByItems);
}
-
部分查询列是经过推到出来,在 SQL解析 过程中,未获得到查询列位置,需要通过该方法进行初始化。对这块不了解的同学,回头可以看下《SQL 解析(三)之查询SQL》。? 现在不用回头,皇冠会掉。
-
#setIndexForAggregationItem()处理 AVG聚合计算列 推导出其对应的 SUM/COUNT 聚合计算列的位置:private void setIndexForAggregationItem(final Map<String, Integer> columnLabelIndexMap) { for (AggregationSelectItem each : getAggregationSelectItems()) { Preconditions.checkState(columnLabelIndexMap.containsKey(each.getColumnLabel()), String.format("Can't find index: %s, please add alias for aggregate selections", each)); each.setIndex(columnLabelIndexMap.get(each.getColumnLabel())); for (AggregationSelectItem derived : each.getDerivedAggregationSelectItems()) { Preconditions.checkState(columnLabelIndexMap.containsKey(derived.getColumnLabel()), String.format("Can't find index: %s", derived)); derived.setIndex(columnLabelIndexMap.get(derived.getColumnLabel())); } } } -
#setIndexForOrderItem()处理 ORDER BY / GROUP BY 列不在查询列 推导出的查询列的位置:private void setIndexForOrderItem(final Map<String, Integer> columnLabelIndexMap, final List<OrderItem> orderItems) { for (OrderItem each : orderItems) { if (-1 != each.getIndex()) { continue; } Preconditions.checkState(columnLabelIndexMap.containsKey(each.getColumnLabel()), String.format("Can't find index: %s", each)); if (columnLabelIndexMap.containsKey(each.getColumnLabel())) { each.setIndex(columnLabelIndexMap.get(each.getColumnLabel())); } } }
2.2 ResultSetMerger
ResultSetMerger,归并结果集接口。
我们先来看看整体的类结构关系:

从 功能 上分成四种:
- 分组:GroupByMemoryResultSetMerger、GroupByStreamResultSetMerger;包含聚合列
- 排序:OrderByStreamResultSetMerger
- 迭代:IteratorStreamResultSetMerger
- 分页:LimitDecoratorResultSetMerger
从 实现方式 上分成三种:
- Stream 流式:AbstractStreamResultSetMerger
- Memory 内存:AbstractMemoryResultSetMerger
- Decorator 装饰者:AbstractDecoratorResultSetMerger
什么时候该用什么实现方式?

- Stream 流式:将数据游标与结果集的游标保持一致,顺序的从结果集中一条条的获取正确的数据。看完下文第三节 OrderByStreamResultSetMerger 可以形象的理解。
- Memory 内存:需要将结果集的所有数据都遍历并存储在内存中,再通过内存归并后,将内存中的数据伪装成结果集返回。看完下文第五节 GroupByMemoryResultSetMerger 可以形象的理解。
- Decorator 装饰者:可以和前二者任意组合
// MergeEngine.java
/**
* 合并结果集.
*
* @return 归并完毕后的结果集
* @throws SQLException SQL异常
*/
public ResultSetMerger merge() throws SQLException {
selectStatement.setIndexForItems(columnLabelIndexMap);
return decorate(build());
}
private ResultSetMerger build() throws SQLException {
if (!selectStatement.getGroupByItems().isEmpty() || !selectStatement.getAggregationSelectItems().isEmpty()) { // 分组 或 聚合列
if (selectStatement.isSameGroupByAndOrderByItems()) {
return new GroupByStreamResultSetMerger(columnLabelIndexMap, resultSets, selectStatement, getNullOrderType());
} else {
return new GroupByMemoryResultSetMerger(columnLabelIndexMap, resultSets, selectStatement, getNullOrderType());
}
}
if (!selectStatement.getOrderByItems().isEmpty()) {
return new OrderByStreamResultSetMerger(resultSets, selectStatement.getOrderByItems(), getNullOrderType());
}
return new IteratorStreamResultSetMerger(resultSets);
}
private ResultSetMerger decorate(final ResultSetMerger resultSetMerger) throws SQLException {
ResultSetMerger result = resultSetMerger;
if (null != selectStatement.getLimit()) {
result = new LimitDecoratorResultSetMerger(result, selectStatement.getLimit());
}
return result;
}
2.2.1 AbstractStreamResultSetMerger
AbstractStreamResultSetMerger,流式归并结果集抽象类,提供从当前结果集获得行数据。
public abstract class AbstractStreamResultSetMerger implements ResultSetMerger {
/**
* 当前结果集
*/
private ResultSet currentResultSet;
protected ResultSet getCurrentResultSet() throws SQLException {
if (null == currentResultSet) {
throw new SQLException("Current ResultSet is null, ResultSet perhaps end of next.");
}
return currentResultSet;
}
@Override
public Object getValue(final int columnIndex, final Class<?> type) throws SQLException {
if (Object.class == type) {
return getCurrentResultSet().getObject(columnIndex);
}
if (int.class == type) {
return getCurrentResultSet().getInt(columnIndex);
}
if (String.class == type) {
return getCurrentResultSet().getString(columnIndex);
}
// .... 省略其他数据类型读取类似代码
return getCurrentResultSet().getObject(columnIndex);
}
}
2.2.2 AbstractMemoryResultSetMerger
AbstractMemoryResultSetMerger,内存归并结果集抽象类,提供从内存数据行对象( MemoryResultSetRow ) 获得行数据。
public abstract class AbstractMemoryResultSetMerger implements ResultSetMerger {
private final Map<String, Integer> labelAndIndexMap;
/**
* 内存数据行对象
*/
@Setter
private MemoryResultSetRow currentResultSetRow;
@Override
public Object getValue(final int columnIndex, final Class<?> type) throws SQLException {
if (Blob.class == type || Clob.class == type || Reader.class == type || InputStream.class == type || SQLXML.class == type) {
throw new SQLFeatureNotSupportedException();
}
return currentResultSetRow.getCell(columnIndex);
}
}
- 和 AbstractStreamResultSetMerger 对比,貌似区别不大?!确实,从抽象父类上看,两种实现方式差不多。抽象父类提供给实现子类的是数据读取的功能,真正的流式归并、内存归并是在子类实现上体现。
public class MemoryResultSetRow {
/**
* 行数据
*/
private final Object[] data;
public MemoryResultSetRow(final ResultSet resultSet) throws SQLException {
data = load(resultSet);
}
/**
* 加载 ResultSet 当前行数据到内存
* @param resultSet 结果集
* @return 行数据
* @throws SQLException 当结果集关闭
*/
private Object[] load(final ResultSet resultSet) throws SQLException {
int columnCount = resultSet.getMetaData().getColumnCount();
Object[] result = new Object[columnCount];
for (int i = 0; i < columnCount; i++) {
result[i] = resultSet.getObject(i + 1);
}
return result;
}
/**
* 获取数据.
*
* @param columnIndex 列索引
* @return 数据
*/
public Object getCell(final int columnIndex) {
Preconditions.checkArgument(columnIndex > 0 && columnIndex < data.length + 1);
return data[columnIndex - 1];
}
/**
* 设置数据.
*
* @param columnIndex 列索引
* @param value 值
*/
public void setCell(final int columnIndex, final Object value) {
Preconditions.checkArgument(columnIndex > 0 && columnIndex < data.length + 1);
data[columnIndex - 1] = value;
}
}
- 调用
#load()方法,将当前结果集的一条行数据加载到内存。
2.2.3 AbstractDecoratorResultSetMerger
AbstractDecoratorResultSetMerger,装饰结果集归并抽象类,通过调用其装饰的归并对象 #getValue() 方法获得行数据。
public abstract class AbstractDecoratorResultSetMerger implements ResultSetMerger {
/**
* 装饰的归并对象
*/
private final ResultSetMerger resultSetMerger;
@Override
public Object getValue(final int columnIndex, final Class<?> type) throws SQLException {
return resultSetMerger.getValue(columnIndex, type);
}
}
3. OrderByStreamResultSetMerger
OrderByStreamResultSetMerger,基于 Stream 方式排序归并结果集实现。
3.1 归并算法
因为各个分片结果集已经排序完成,使用**《归并算法》**能够充分利用这个优势。
归并操作(merge),也叫归并算法,指的是将两个已经排序的序列合并成一个序列的操作。归并排序算法依赖归并操作。
【迭代法】
- 申请空间,使其大小为两个已经排序序列之和,该空间用来存放合并后的序列
- 设定两个指针,最初位置分别为两个已经排序序列的起始位置
- 比较两个指针所指向的元素,选择相对小的元素放入到合并空间,并移动指针到下一位置
- 重复步骤3直到某一指针到达序列尾
- 将另一序列剩下的所有元素直接复制到合并序列尾
从定义上看,是不是超级符合我们这个场景。? 此时此刻,你是不是捂着胸口,感叹:“大学怎么没好好学数据结构与算法呢”?反正我是捂着了,都是眼泪。

public class OrderByStreamResultSetMerger extends AbstractStreamResultSetMerger {
/**
* 排序列
*/
@Getter(AccessLevel.NONE)
private final List<OrderItem> orderByItems;
/**
* 排序值对象队列
*/
private final Queue<OrderByValue> orderByValuesQueue;
/**
* 默认排序类型
*/
private final OrderType nullOrderType;
/**
* 是否第一个 ResultSet 已经调用 #next()
*/
private boolean isFirstNext;
public OrderByStreamResultSetMerger(final List<ResultSet> resultSets, final List<OrderItem> orderByItems, final OrderType nullOrderType) throws SQLException {
this.orderByItems = orderByItems;
this.orderByValuesQueue = new PriorityQueue<>(resultSets.size());
this.nullOrderType = nullOrderType;
orderResultSetsToQueue(resultSets);
isFirstNext = true;
}
private void orderResultSetsToQueue(final List<ResultSet> resultSets) throws SQLException {
for (ResultSet each : resultSets) {
OrderByValue orderByValue = new OrderByValue(each, orderByItems, nullOrderType);
if (orderByValue.next()) {
orderByValuesQueue.offer(orderByValue);
}
}
// 设置当前 ResultSet,这样 #getValue() 能拿到记录
setCurrentResultSet(orderByValuesQueue.isEmpty() ? resultSets.get(0) : orderByValuesQueue.peek().getResultSet());
}
-
属性
orderByValuesQueue使用的队列实现是优先级队列( PriorityQueue )。有兴趣的同学可以看看《JDK源码研究PriorityQueue》,本文不展开讲,不是主角戏份不多。我们记住几个方法的用途:#offer():增加元素。增加时,会将该元素和已有元素们按照优先级进行排序#peek():获得优先级第一的元素#pool():获得优先级第一的元素并移除
-
一个 ResultSet 构建一个 OrderByValue 用于排序,即上文归并算法提到的**“空间”**。
public final class OrderByValue implements Comparable<OrderByValue> { /** * 已排序结果集 */ @Getter private final ResultSet resultSet; /** * 排序列 */ private final List<OrderItem> orderByItems; /** * 默认排序类型 */ private final OrderType nullOrderType; /** * 排序列对应的值数组 * 因为一条记录可能有多个排序列,所以是数组 */ private List<Comparable<?>> orderValues; /** * 遍历下一个结果集游标. * * @return 是否有下一个结果集 * @throws SQLException SQL异常 */ public boolean next() throws SQLException { boolean result = resultSet.next(); orderValues = result ? getOrderValues() : Collections.<Comparable<?>>emptyList(); return result; } /** * 获得 排序列对应的值数组 * * @return 排序列对应的值数组 * @throws SQLException 当结果集关闭时 */ private List<Comparable<?>> getOrderValues() throws SQLException { List<Comparable<?>> result = new ArrayList<>(orderByItems.size()); for (OrderItem each : orderByItems) { Object value = resultSet.getObject(each.getIndex()); Preconditions.checkState(null == value || value instanceof Comparable, "Order by value must implements Comparable"); result.add((Comparable<?>) value); } return result; } /** * 对比 {@link #orderValues},即两者的第一条记录 * * @param o 对比 OrderByValue * @return -1 0 1 */ @Override public int compareTo(final OrderByValue o) { for (int i = 0; i < orderByItems.size(); i++) { OrderItem thisOrderBy = orderByItems.get(i); int result = ResultSetUtil.compareTo(orderValues.get(i), o.orderValues.get(i), thisOrderBy.getType(), nullOrderType); if (0 != result) { return result; } } return 0; } }- 调用
OrderByValue#next()方法时,获得其对应结果集排在第一条的记录,通过#getOrderValues()计算该记录的排序字段值。这样两个OrderByValue 通过#compareTo()方法可以比较两个结果集的第一条记录。
- 调用
-
if (orderByValue.next()) {处,调用OrderByValue#next()后,添加到 PriorityQueue。因此,orderByValuesQueue.peek().getResultSet()能够获得多个 ResultSet 中排在第一的。
3.2 #next()
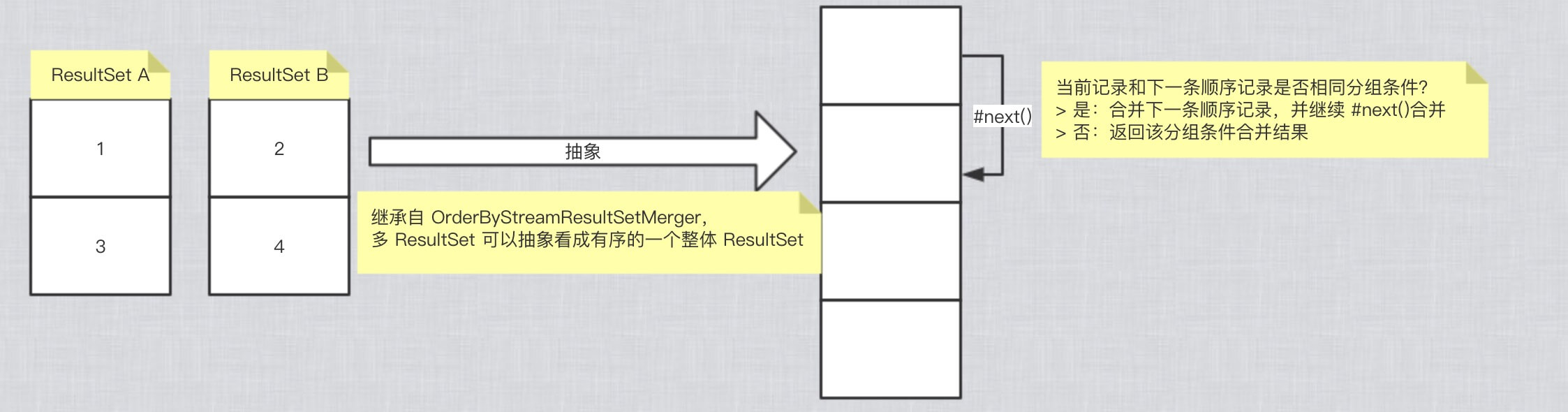
通过调用 OrderByStreamResultSetMerger#next() 不断获得当前排在第一的记录。#next() 每次调用后,实际做的是当前 ResultSet 的替换,以及当前的 ResultSet 的记录指向下一条。这样说起来可能比较绕,我们来看一张图:

- 白色向下箭头:OrderByStreamResultSetMerger 对 ResultSet 的指向。
- 黑色箭头:ResultSet 对当前记录的指向。
- ps:这块如果分享的不清晰让您费劲,十分抱歉。欢迎加我微信(wangwenbin-server)交流下,这样我也可以优化表述。
// OrderByStreamResultSetMerger.java
@Override
public boolean next() throws SQLException {
if (orderByValuesQueue.isEmpty()) {
return false;
}
if (isFirstNext) {
isFirstNext = false;
return true;
}
// 移除上一次获得的 ResultSet
OrderByValue firstOrderByValue = orderByValuesQueue.poll();
// 如果上一次获得的 ResultSet还有下一条记录,继续添加到 排序值对象队列
if (firstOrderByValue.next()) {
orderByValuesQueue.offer(firstOrderByValue);
}
if (orderByValuesQueue.isEmpty()) {
return false;
}
// 设置当前 ResultSet
setCurrentResultSet(orderByValuesQueue.peek().getResultSet());
return true;
}
-
orderByValuesQueue.poll()移除上一次获得的 ResultSet。为什么不能#setCurrentResultSet()就移除呢?如果该 ResultSet 里面还存在下一条记录,需要继续参加排序。而判断是否有下一条,需要调用ResultSet#next()方法,这会导致 ResultSet 指向了下一条记录。因而orderByValuesQueue.poll()调用是后置的。 -
isFirstNext变量那的判断看着是不是很“灵异”?因为#orderResultSetsToQueue()处设置了第一次的 ResultSet。如果不加这个标记,会导致第一条记录“不见”了。 -
通过不断的
Queue#poll()、Queue#offset()实现排序。巧妙!仿佛 Get 新技能了:// 移除上一次获得的 ResultSet OrderByValue firstOrderByValue = orderByValuesQueue.poll(); // 如果上一次获得的 ResultSet还有下一条记录,继续添加到 排序值对象队列 if (firstOrderByValue.next()) { orderByValuesQueue.offer(firstOrderByValue); }
在看下,我们上文 Stream 方式归并的定义:**将数据游标与结果集的游标保持一致,顺序的从结果集中一条条的获取正确的数据。**是不是能够清晰的对上了?!?
4. GroupByStreamResultSetMerger
GroupByStreamResultSetMerger,基于 Stream 方式分组归并结果集实现。 它继承自 OrderByStreamResultSetMerger,在排序的逻辑上,实现分组功能。实现原理也较为简单:
public final class GroupByStreamResultSetMerger extends OrderByStreamResultSetMerger {
/**
* 查询列名与位置映射
*/
private final Map<String, Integer> labelAndIndexMap;
/**
* Select SQL语句对象
*/
private final SelectStatement selectStatement;
/**
* 当前结果记录
*/
private final List<Object> currentRow;
/**
* 下一条结果记录 GROUP BY 条件
*/
private List<?> currentGroupByValues;
public GroupByStreamResultSetMerger(
final Map<String, Integer> labelAndIndexMap, final List<ResultSet> resultSets, final SelectStatement selectStatement, final OrderType nullOrderType) throws SQLException {
super(resultSets, selectStatement.getOrderByItems(), nullOrderType);
this.labelAndIndexMap = labelAndIndexMap;
this.selectStatement = selectStatement;
currentRow = new ArrayList<>(labelAndIndexMap.size());
// 初始化下一条结果记录 GROUP BY 条件
currentGroupByValues = getOrderByValuesQueue().isEmpty() ? Collections.emptyList() : new GroupByValue(getCurrentResultSet(), selectStatement.getGroupByItems()).getGroupValues();
}
@Override
public Object getValue(final int columnIndex, final Class<?> type) throws SQLException {
return currentRow.get(columnIndex - 1);
}
@Override
public Object getValue(final String columnLabel, final Class<?> type) throws SQLException {
Preconditions.checkState(labelAndIndexMap.containsKey(columnLabel), String.format("Can't find columnLabel: %s", columnLabel));
return currentRow.get(labelAndIndexMap.get(columnLabel) - 1);
}
}
-
currentRow为当前结果记录,使用#getValue()、#getCalendarValue()方法获得当前结果记录的查询列值。 -
currentGroupByValues为下一条结果记录 GROUP BY 条件,通过 GroupByValue 生成:public final class GroupByValue { /** * 分组条件值数组 */ private final List<?> groupValues; public GroupByValue(final ResultSet resultSet, final List<OrderItem> groupByItems) throws SQLException { groupValues = getGroupByValues(resultSet, groupByItems); } /** * 获得分组条件值数组 * 例如,`GROUP BY user_id, order_status` 返回的某条记录结果为 `userId = 1, order_status = 3`,对应的 `groupValues = [1, 3]` * @param resultSet 结果集(单分片) * @param groupByItems 分组列 * @return 分组条件值数组 * @throws SQLException 当结果集关闭 */ private List<?> getGroupByValues(final ResultSet resultSet, final List<OrderItem> groupByItems) throws SQLException { List<Object> result = new ArrayList<>(groupByItems.size()); for (OrderItem each : groupByItems) { result.add(resultSet.getObject(each.getIndex())); // 从结果集获得每个分组条件的值 } return result; } } -
GroupByStreamResultSetMerger 在创建时,当前结果记录实际未合并,需要先调用
#next(),在使用#getValue()等方法获取值,这个和 OrderByStreamResultSetMerger 不同,可能是个 BUG。
4.1 AggregationUnit
AggregationUnit,归并计算单元接口,有两个接口方法:
#merge():归并聚合值#getResult():获取计算结果
一共有三个实现类:
- AccumulationAggregationUnit:累加聚合单元,解决 COUNT、SUM 聚合列
- ComparableAggregationUnit:比较聚合单元,解决 MAX、MIN 聚合列
- AverageAggregationUnit:平均值聚合单元,解决 AVG 聚合列
实现都比较易懂,直接点击链接查看源码,我们就不浪费篇幅贴代码啦。
4.2 #next()
我们先看看大体的调用流程:

? 看起来代码比较多,逻辑其实比较清晰,对照着顺序图顺序往下读即可。
// GroupByStreamResultSetMerger.java
@Override
public boolean next() throws SQLException {
// 清除当前结果记录
currentRow.clear();
if (getOrderByValuesQueue().isEmpty()) {
return false;
}
//
if (isFirstNext()) {
super.next();
}
// 顺序合并下面相同分组条件的记录
if (aggregateCurrentGroupByRowAndNext()) {
// 生成下一条结果记录 GROUP BY 条件
currentGroupByValues = new GroupByValue(getCurrentResultSet(), selectStatement.getGroupByItems()).getGroupValues();
}
return true;
}
private boolean aggregateCurrentGroupByRowAndNext() throws SQLException {
boolean result = false;
// 生成计算单元
Map<AggregationSelectItem, AggregationUnit> aggregationUnitMap = Maps.toMap(selectStatement.getAggregationSelectItems(), new Function<AggregationSelectItem, AggregationUnit>() {
@Override
public AggregationUnit apply(final AggregationSelectItem input) {
return AggregationUnitFactory.create(input.getType());
}
});
// 循环顺序合并下面相同分组条件的记录
while (currentGroupByValues.equals(new GroupByValue(getCurrentResultSet(), selectStatement.getGroupByItems()).getGroupValues())) {
// 归并聚合值
aggregate(aggregationUnitMap);
// 缓存当前记录到结果记录
cacheCurrentRow();
// 获取下一条记录
result = super.next();
if (!result) {
break;
}
}
// 设置当前记录的聚合字段结果
setAggregationValueToCurrentRow(aggregationUnitMap);
return result;
}
private void aggregate(final Map<AggregationSelectItem, AggregationUnit> aggregationUnitMap) throws SQLException {
for (Entry<AggregationSelectItem, AggregationUnit> entry : aggregationUnitMap.entrySet()) {
List<Comparable<?>> values = new ArrayList<>(2);
if (entry.getKey().getDerivedAggregationSelectItems().isEmpty()) { // SUM/COUNT/MAX/MIN 聚合列
values.add(getAggregationValue(entry.getKey()));
} else {
for (AggregationSelectItem each : entry.getKey().getDerivedAggregationSelectItems()) { // AVG 聚合列
values.add(getAggregationValue(each));
}
}
entry.getValue().merge(values);
}
}
private void cacheCurrentRow() throws SQLException {
for (int i = 0; i < getCurrentResultSet().getMetaData().getColumnCount(); i++) {
currentRow.add(getCurrentResultSet().getObject(i + 1));
}
}
private Comparable<?> getAggregationValue(final AggregationSelectItem aggregationSelectItem) throws SQLException {
Object result = getCurrentResultSet().getObject(aggregationSelectItem.getIndex());
Preconditions.checkState(null == result || result instanceof Comparable, "Aggregation value must implements Comparable");
return (Comparable<?>) result;
}
private void setAggregationValueToCurrentRow(final Map<AggregationSelectItem, AggregationUnit> aggregationUnitMap) {
for (Entry<AggregationSelectItem, AggregationUnit> entry : aggregationUnitMap.entrySet()) {
currentRow.set(entry.getKey().getIndex() - 1, entry.getValue().getResult()); // 获取计算结果
}
}
5. GroupByMemoryResultSetMerger
GroupByMemoryResultSetMerger,基于 内存 分组归并结果集实现。
区别于 GroupByStreamResultSetMerger,其无法使用每个分片结果集的有序的特点,只能在内存中合并后,进行整个重新排序。因而,性能和内存都较 GroupByStreamResultSetMerger 会差。
主流程如下:

public final class GroupByMemoryResultSetMerger extends AbstractMemoryResultSetMerger {
/**
* Select SQL语句对象
*/
private final SelectStatement selectStatement;
/**
* 默认排序类型
*/
private final OrderType nullOrderType;
/**
* 内存结果集
*/
private final Iterator<MemoryResultSetRow> memoryResultSetRows;
public GroupByMemoryResultSetMerger(
final Map<String, Integer> labelAndIndexMap, final List<ResultSet> resultSets, final SelectStatement selectStatement, final OrderType nullOrderType) throws SQLException {
super(labelAndIndexMap);
this.selectStatement = selectStatement;
this.nullOrderType = nullOrderType;
memoryResultSetRows = init(resultSets);
}
private Iterator<MemoryResultSetRow> init(final List<ResultSet> resultSets) throws SQLException {
Map<GroupByValue, MemoryResultSetRow> dataMap = new HashMap<>(1024); // 分组条件值与内存记录映射
Map<GroupByValue, Map<AggregationSelectItem, AggregationUnit>> aggregationMap = new HashMap<>(1024); // 分组条件值与聚合列映射
// 遍历结果集
for (ResultSet each : resultSets) {
while (each.next()) {
// 生成分组条件
GroupByValue groupByValue = new GroupByValue(each, selectStatement.getGroupByItems());
// 初始化分组条件到 dataMap、aggregationMap 映射
initForFirstGroupByValue(each, groupByValue, dataMap, aggregationMap);
// 归并聚合值
aggregate(each, groupByValue, aggregationMap);
}
}
// 设置聚合列结果到内存记录
setAggregationValueToMemoryRow(dataMap, aggregationMap);
// 内存排序
List<MemoryResultSetRow> result = getMemoryResultSetRows(dataMap);
// 设置当前 ResultSet,这样 #getValue() 能拿到记录
if (!result.isEmpty()) {
setCurrentResultSetRow(result.get(0));
}
return result.iterator();
}
}
-
#initForFirstGroupByValue()初始化分组条件到dataMap,aggregationMap映射中,这样可以调用#aggregate()将聚合值归并到aggregationMap里的该分组条件。private void initForFirstGroupByValue(final ResultSet resultSet, final GroupByValue groupByValue, final Map<GroupByValue, MemoryResultSetRow> dataMap, final Map<GroupByValue, Map<AggregationSelectItem, AggregationUnit>> aggregationMap) throws SQLException { // 初始化分组条件到 dataMap if (!dataMap.containsKey(groupByValue)) { dataMap.put(groupByValue, new MemoryResultSetRow(resultSet)); } // 初始化分组条件到 aggregationMap if (!aggregationMap.containsKey(groupByValue)) { Map<AggregationSelectItem, AggregationUnit> map = Maps.toMap(selectStatement.getAggregationSelectItems(), new Function<AggregationSelectItem, AggregationUnit>() { @Override public AggregationUnit apply(final AggregationSelectItem input) { return AggregationUnitFactory.create(input.getType()); } }); aggregationMap.put(groupByValue, map); } } -
聚合完每个分组条件后,将聚合列结果
aggregationMap合并到dataMap。private void setAggregationValueToMemoryRow(final Map<GroupByValue, MemoryResultSetRow> dataMap, final Map<GroupByValue, Map<AggregationSelectItem, AggregationUnit>> aggregationMap) { for (Entry<GroupByValue, MemoryResultSetRow> entry : dataMap.entrySet()) { // 遍 历内存记录 for (AggregationSelectItem each : selectStatement.getAggregationSelectItems()) { // 遍历 每个聚合列 entry.getValue().setCell(each.getIndex(), aggregationMap.get(entry.getKey()).get(each).getResult()); } } } -
调用
#getMemoryResultSetRows()方法对内存记录进行内存排序。
// GroupByMemoryResultSetMerger.java
private List<MemoryResultSetRow> getMemoryResultSetRows(final Map<GroupByValue, MemoryResultSetRow> dataMap) {
List<MemoryResultSetRow> result = new ArrayList<>(dataMap.values());
Collections.sort(result, new GroupByRowComparator(selectStatement, nullOrderType)); // 内存排序
return result;
}
// GroupByRowComparator.java
private int compare(final MemoryResultSetRow o1, final MemoryResultSetRow o2, final List<OrderItem> orderItems) {
for (OrderItem each : orderItems) {
Object orderValue1 = o1.getCell(each.getIndex());
Preconditions.checkState(null == orderValue1 || orderValue1 instanceof Comparable, "Order by value must implements Comparable");
Object orderValue2 = o2.getCell(each.getIndex());
Preconditions.checkState(null == orderValue2 || orderValue2 instanceof Comparable, "Order by value must implements Comparable");
int result = ResultSetUtil.compareTo((Comparable) orderValue1, (Comparable) orderValue2, each.getType(), nullOrderType);
if (0 != result) {
return result;
}
}
return 0;
}
- 总的来说,GROUP BY 内存归并和我们日常使用 Map 计算用户订单数是比较相似的。
5.1 #next()
@Override
public boolean next() throws SQLException {
if (memoryResultSetRows.hasNext()) {
setCurrentResultSetRow(memoryResultSetRows.next());
return true;
}
return false;
}
- 内存归并完成后,使用
memoryResultSetRows不断获得下一条记录。
6. IteratorStreamResultSetMerger
IteratorStreamResultSetMerger,基于 Stream 迭代归并结果集实现。
public final class IteratorStreamResultSetMerger extends AbstractStreamResultSetMerger {
/**
* ResultSet 数组迭代器
*/
private final Iterator<ResultSet> resultSets;
public IteratorStreamResultSetMerger(final List<ResultSet> resultSets) {
this.resultSets = resultSets.iterator();
// 设置当前 ResultSet,这样 #getValue() 能拿到记录
setCurrentResultSet(this.resultSets.next());
}
@Override
public boolean next() throws SQLException {
// 当前 ResultSet 迭代下一条记录
if (getCurrentResultSet().next()) {
return true;
}
if (!resultSets.hasNext()) {
return false;
}
// 获得下一个ResultSet, 设置当前 ResultSet
setCurrentResultSet(resultSets.next());
boolean hasNext = getCurrentResultSet().next();
if (hasNext) {
return true;
}
while (!hasNext && resultSets.hasNext()) {
setCurrentResultSet(resultSets.next());
hasNext = getCurrentResultSet().next();
}
return hasNext;
}
}
7. LimitDecoratorResultSetMerger
LimitDecoratorResultSetMerger,基于 Decorator 分页结果集归并实现。
public final class LimitDecoratorResultSetMerger extends AbstractDecoratorResultSetMerger {
/**
* 分页条件
*/
private final Limit limit;
/**
* 是否全部记录都跳过了,即无符合条件记录
*/
private final boolean skipAll;
/**
* 当前已返回行数
*/
private int rowNumber;
public LimitDecoratorResultSetMerger(final ResultSetMerger resultSetMerger, final Limit limit) throws SQLException {
super(resultSetMerger);
this.limit = limit;
skipAll = skipOffset();
}
private boolean skipOffset() throws SQLException {
// 跳过 skip 记录
for (int i = 0; i < limit.getOffsetValue(); i++) {
if (!getResultSetMerger().next()) {
return true;
}
}
// 行数
rowNumber = limit.isRowCountRewriteFlag() ? 0 : limit.getOffsetValue();
return false;
}
@Override
public boolean next() throws SQLException {
if (skipAll) {
return false;
}
// 获得下一条记录
if (limit.getRowCountValue() > -1) {
return ++rowNumber <= limit.getRowCountValue() && getResultSetMerger().next();
}
// 部分db 可以直 offset,不写 limit 行数,例如 oracle
return getResultSetMerger().next();
}
}
- LimitDecoratorResultSetMerger 可以对其他 ResultSetMerger 进行装饰,调用其他 ResultSetMerger 的
#next()不断获得下一条记录。
666. 彩蛋
诶?应该是有蛮多地方解释的不是很清晰,如果让您阅读误解或是阻塞,非常抱歉。代码读起来比较易懂,使用文字来解释,对表述能力较差的自己,可能就绞尽脑汁,一脸懵逼。
恩,如果可以,还烦请把读起来不太爽的地方告诉我,谢谢。
厚着脸皮,道友,分享一波朋友圈可好?
如下是小礼包,嘿嘿
| 归并结果集接口 | SQL |
|---|---|
| OrderByStreamResultSetMerger | SELECT * FROM t_order ORDER BY id |
| GroupByStreamResultSetMerger | SELECT uid, AVG(id) FROM t_order GROUP BY uid |
| GroupByMemoryResultSetMerger | SELECT uid FROM t_order GROUP BY id ORDER BY id DESC |
| IteratorStreamResultSetMerger | SELECT * FROM t_order |
| LimitDecoratorResultSetMerger | SELECT * FROM t_order ORDER BY id LIMIT 10 |
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









