







很多时候,我们会把一些重要的信息保存在结构化的数据库中进行归档。例如,重要的安全审计信息,关键的系统故障信息。日积月累,数据库当中就堆积了海量的重要信息,而这些重要的信息却很难被有效利用起来。
我们能否利用Splunk把所有日后有可能用到的数据表内容事先保存下来,做好索引,在关键时刻通过简单的方法搜索出来,派上用场呢?答案是肯定的!
下面就以Linux系统为例,看看我们如何通过简单的方法,定时、定量将数据表里的内容交给Splunk打理。
我们需要一些系统准备,我们需要确定获取数据表内容的方式,需要确定Splunk获取内容的位置,测试Splunk是否能很好地识别获取到的内容。
获取数据表内容需要借助脚本工具,脚本语言Python是一个非常好的选择,因此第一步我们需要在系统上准备好Python环境,一般Linux系统都会自带Python程序,但仍需要安装gcc、glib和glibc库来支持Python的扩展功能,这些库都可以使用yum进行快速安装。
完成后需要安装Python的几个扩展模块:C语言扩展模块Cython、连接数据库的功能模块pymssql或pymysql、以及setuptools功能模块,这些功能模块都可以在http://code.google.com/hosting/找到安装包后下载,解压后使用python install setup.py安装,最后,使用yum工具安装Linux系统连接数据库的小程序freetds,好让Python脚本进行调用。
准备就绪后,下面就开始进入实质性阶段吧。
首先我们查看一下希望进行监控的数据表内容:
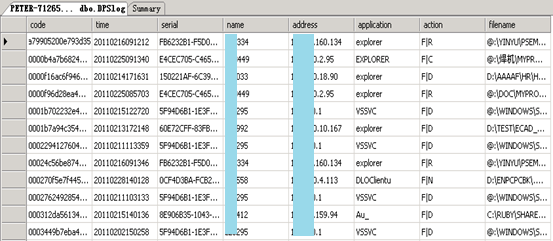
可以看到数据表中的内容包含几个重要字段,包括时间、用户名、IP地址、程序、操作、文件名,这是一个用户登录后使用相关程序对文件进行操作的记录,管理员把这些记录信息存放在了MSSQL数据库中。显然,这样的数据每天都会大量产生,但是如果遇到类似机密文件被篡改的事件时,这些记录就会起到关键作用,因此保存信息并存档就非常重要。只是如果在使用时能更方便一些,那就太完美了。
下面新建一个test.py脚本文件来开始我们脚本的编写吧!脚本的开始当然需要告诉系统这是一个Python脚本,同时还需要导入之前我们已经安装完成的一些功能模块:
#!/bin/python
import pymssql
import csv
import os
其中pymssql是之前下载安装的功能模块,让Python可以与MSSQL进行通信,csv模块主要是为了利用它的csv.writer函数来将临时信息写入一个文件中,而os模块则是为了使Python可以对文件进行读写。
首先我们先让程序读取上一次获取数据表信息时的最后一条记录,最后一条记录的时间戳已经记录在/root/sqltest/data/record文件当中:
input = open(‘/root/sqltest/data/record’,'r’)
readrecord = input.read()
#从文件中读取最后一条日志记录的日期
下面开始通过pymssql模块中的connect函数对数据库建立连接,其中host字段表示数据库服务器的IP地址,database字段表示数据库名称,user字段表示数据库用户名,password字段表示密码:
conn = pymssql.connect(
host =”10.0.0.152″,database=”testdb”,user=”sqltest”,password=”123456″)
cur = conn.cursor()
#连接数据库并建立指针
执行数据库搜索语句,把我们需要的条目取出来,在此案例中我们本次查询把time字段值大于上次查询最后一条记录time字段值的记录都select出来,这样做的目的是避免我们每一次获取一次数据表内容时,都把整张数据表遍历一遍,否则这就弄巧成拙了:
cur.execute(“select * from dbo.DPSlog WHERE time >” + readrecord)
row = cur.fetchall()
#执行查询数据库语句
利用一条for循环语句把查询出来的结果一条条都进行输出,但是在这里因为我们没有指定输出的具体目的,所以默认会把这些信息输出到屏幕上,我们可以利用这个输出结果直接把信息导入到Splunk中进行索引:
for i in row:
print i
#输出数据库查询结果
结果输出完成后,我们需要为下一次查询数据表做准备了,我们尝试查询本次获取的数据条目中时间最晚的一条记录,并将这条记录的时间戳写入/root/sqltest/data/record文件中记录下来,这时我们就需要用到csv模块中的writer函数了:
cur.execute(“select max(time) as record_time from DPSlog”)
recordtime = cur.fetchone()
#定义本次查询最后一条记录的日期
openfile = ‘/root/sqltest/data/record’
spamWriter = csv.writer(open(
openfile, ‘w’), delimiter=’,',quotechar=’,', quoting=csv.QUOTE_MINIMAL)
spamWriter.writerow(recordtime)
#将日期记录写入record文件
最后,我们做事情要有头有尾,跟数据库建立的连接释放掉:
conn.commit()
conn.close()
既然有了脚本,就要让它定时运行,这样才能实现我们根本目的:利用Splunk把所有日后有可能用到的数据表内容事先保存下来,做好索引,好在关键时刻通过简单的方法搜索出来。
Linux的crond是个不错的选择,但是Splunk的脚本导入数据更容易配置一些,进入Splunk后台管理界面,点击数据导入-》脚本进入脚本管理界面,再点击“新建”按钮新建一个脚本任务:

在“命令”一栏里填写好脚本的位置及文件名,这里注意Splunk只能运行在其相关bin文件夹内的脚本,也就是说只能运行/opt/splunk/bin/,或是/opt/splunk/etc/apps/应用名/bin/这一类文件夹下面的脚本。“执行间隔”一栏里可以指定脚本自动运行的时间间隔,单位是秒;除此之外,填写好数据来源名称、来源类型及使用索引名称等相关信息后,点击“保存”按钮进行保存。
现在Splunk就已经开始按照我们的要求定时地运行脚本并获取得到的数据条目了,我们看看获取的情况如何:

成功了,信息条目保持了正常的格式,时间戳可以正确识别,也没有出现什么乱码的现象,后面的工作就交给Splunk了。
根据我们的数据来源,可以利用Splunk制作出各式各样的报表,例如,如果希望了解在一段时间内哪些用户进行操作的次数最多,我们可以制作出一个并行图来进行观察分析。
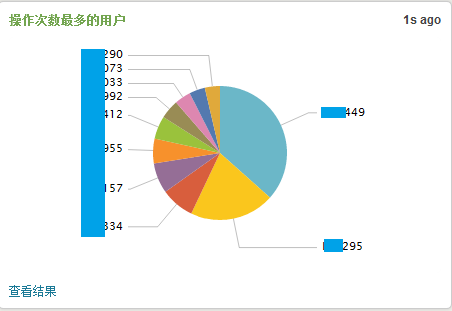
如果我们觉得某一个用户很可疑,希望了解他一段时间内所进行过的操作明细,我们也可以制作一个根据用户名来查看其进行各类操作的时序图。
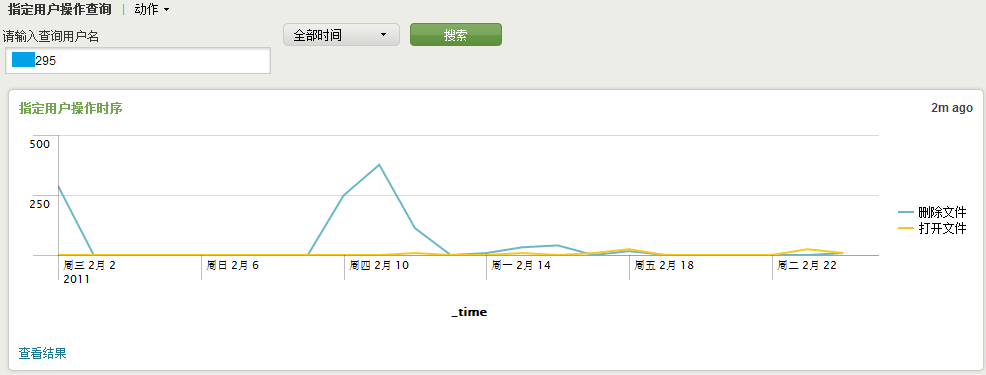
可以看出,他在2月10日左右进行了许多删除文件的操作,那到底删除了哪些文件呢?我们在通过操作的明细列表做进一步分析。

看来是删除了Windows系统补丁的临时文件,那么可以解除戒备了。
至此,我们通过脚本让Splunk可以获取到数据库表内容进而进行分析监控的目的达成了。如何有效发挥Splunk功能,从海量数据中获得更多更有价值的信息,也是我们需要继续努力的目标。其实如果有了一个出色的数据分析工具,数据挖掘工作也会变得轻松许多并且充满乐趣!
Peter















 419
419

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









