







一、top
linux 的 top 命令主要用来监控系统实时负载率、进程的资源占用率及其它各项系统状态属性是否正常。
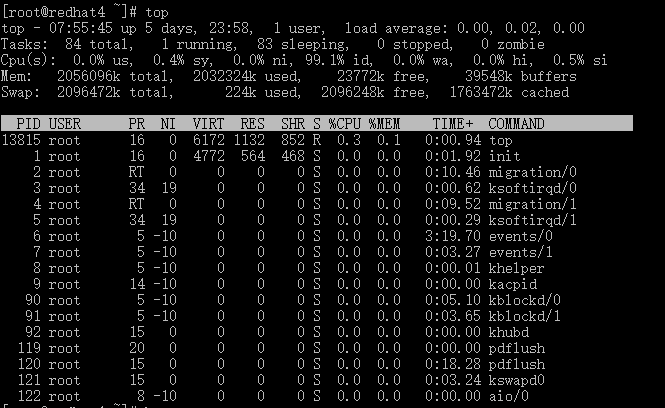
- 系统、任务统计信息:
前 8 行是系统整体的统计信息。第 1 行是任务队列信息,同 uptime 命令的执行结果
| 07:55:45 | 当前时间 |
| 5 days, 23:58 | 系统运行时间,格式为时:分 |
| 1 user | 当前登录用户数 |
| load average: 0.00, 0.02, 0.00 | 系统负载,即任务队列的平均长度。 三个数值分别为 1分钟、5分钟、15分钟前到现在的平均值。 注意:这三个值可以用来判定系统是否负载过高——如果值 持续大于系统 cpu 个数,就需要优化你的程序或者架构了。 |
- 进程、 cpu 统计信息:
第 2~6 行为进程和CPU的信息。当有多个CPU时,这些内容可能会超过两行。内容如下:
| Tasks: 84 total | 进程总数 |
| 1 running | 正在运行的进程数 |
| 83 sleeping | 睡眠的进程数 |
| 0 stopped | 停止的进程数 |
| 0 zombie | 僵尸进程数 |
| 0.0% us | 用户空间占用CPU百分比 |
| 0.4% sy | 内核空间占用CPU百分比 |
| 0.0% ni | 用户进程空间内改变过优先级的进程占用CPU百分比 |
| 99.1% id | 空闲CPU百分比 |
| 0.0% wa | 等待输入输出的CPU时间百分比 |
| 0.0% hi | Hardware IRQ 中断请求 |
| 0.5% si | Software IRQ 中断请求 |
- 最后两行为内存信息:
| 2056096k total | 物理内存总量 |
| 2032324k used | 使用的物理内存总量 |
| 23772k free | 空闲内存总量 |
| 39548k buffers | 用作内核缓存的内存量 |
| 2096472k total | 交换区总量 |
| 224k used | 使用的交换区总量 |
| 2096248k free | 空闲交换区总量 |
| 1763472k cached | 缓冲的交换区总量。 内存中的内容被换出到交换区,而后又被换入到内存,但使用过的交换区尚未被覆盖, 该数值即为这些内容已存在于内存中的交换区的大小。 相应的内存再次被换出时可不必再对交换区写入。 |
PS:如何计算可用内存和已用内存?
除了 free -m 之外,也可以看 top:
Mem: 255592k total, 167568k used, 88024k free, 25068k buffers
Swap: 524280k total, 0k used, 524280k free, 85724k cached
3.1 实际的程序可用内存数怎么算呢?
The answer is: free + (buffers + cached)
88024k + (25068k + 85724k) = 198816k
3.2 程序已用内存数又怎么算呢?
The answer is: used – (buffers + cached)
167568k – (25068k + 85724k) = 56776k
3.3 怎么判断系统是否内存不足呢?
如果你的 swap used 数值大于 0 ,基本可以判断已经遇到内存瓶颈了,要么优化你的代码,要么加内存。
- 进程信息区:
统计信息区域的下方显示了各个进程的详细信息。
| 序号 | 列名 | 含义 |
| a | PID | 进程id |
| b | PPID | 父进程id |
| c | RUSER | Real user name |
| d | UID | 进程所有者的用户id |
| e | USER | 进程所有者的用户名 |
| f | GROUP | 进程所有者的组名 |
| g | TTY | 启动进程的终端名。不是从终端启动的进程则显示为 ? |
| h | PR | 优先级 |
| i | NI | nice值。负值表示高优先级,正值表示低优先级 |
| j | P | 最后使用的CPU,仅在多CPU环境下有意义 |
| k | %CPU | 上次更新到现在的CPU时间占用百分比 |
| l | TIME | 进程使用的CPU时间总计,单位秒 |
| m | TIME+ | 进程使用的CPU时间总计,单位1/100秒 |
| n | %MEM | 进程使用的物理内存百分比 |
| o | VIRT | 进程使用的虚拟内存总量,单位kb。VIRT=SWAP+RES |
| p | SWAP | 进程使用的虚拟内存中,被换出的大小,单位kb。 |
| q | RES | 进程使用的、未被换出的物理内存大小,单位kb。RES=CODE+DATA |
| r | CODE | 可执行代码占用的物理内存大小,单位kb |
| s | DATA | 可执行代码以外的部分(数据段+栈)占用的物理内存大小,单位kb |
| t | SHR | 共享内存大小,单位kb |
| u | nFLT | 页面错误次数 |
| v | nDRT | 最后一次写入到现在,被修改过的页面数。 |
| w | S | 进程状态。 |
| D=不可中断的睡眠状态 | ||
| R=运行 | ||
| S=睡眠 | ||
| T=跟踪/停止 | ||
| Z=僵尸进程 | ||
| x | COMMAND | 命令名/命令行 |
| y | WCHAN | 若该进程在睡眠,则显示睡眠中的系统函数名 |
| z | Flags | 任务标志,参考 sched.h |
- 查看指定列
默认情况下仅显示比较重要的 PID、USER、PR、NI、VIRT、RES、SHR、S、%CPU、%MEM、TIME+、COMMAND 列。
可以通过下面的快捷键来更改显示内容:
5.1 f 键选择显示内容
通过 f 键可以选择显示的内容。按 f 键之后会显示列的列表,按 a-z 即可显示或隐藏对应的列,最后按回车键确定。
5.2 o 键改变显示顺序
按 o 键可以改变列的显示顺序。按小写的 a-z 可以将相应的列向右移动,而大写的 A-Z 可以将相应的列向左移动。最后按回车键确定。
5.3 F/O 键将进程按列排序
按大写的 F 或 O 键,然后按 a-z 可以将进程按照相应的列进行排序。而大写的 R 键可以将当前的排序倒转
- 常用交互命令
从使用角度来看,熟练的掌握这些命令比掌握选项还重要一些。这些命令都是单字母的,如果在命令行选项中使用了s选项,则可能其中一些命令会被屏蔽掉。
Ctrl+L 擦除并且重写屏幕。
h或者? 显示帮助画面,给出一些简短的命令总结说明。
k终止一个进程。系统将提示用户输入需要终止的进程PID,以及需要发送给该进程什么样的信号。一般的终止进程可以使用15信号;如果不能正常结束那就使用信号9强制结束该进程。默认值是信号15。在安全模式中此命令被屏蔽。
i 忽略闲置和僵死进程。这是一个开关式命令。
q 退出程序。
r重新安排一个进程的优先级别。系统提示用户输入需要改变的进程PID以及需要设置的进程优先级值。输入一个正值将使优先级降低,反之则可以使该进程拥有更高的优先权。默认值是10。
S 切换到累计模式。
s 改变两次刷新之间的延迟时间。系统将提示用户输入新的时间,单位为s。如果有小数,就换算成m s。输入0值则系统将不断刷新,默认值是5 s。需要注意的是如果设置太小的时间,很可能会引起不断刷新,从而根本来不及看清显示的情况,而且系统负载也会大大增加。
f或者F 从当前显示中添加或者删除项目。
o或者O 改变显示项目的顺序。
l 切换显示平均负载和启动时间信息。
m 切换显示内存信息。
t 切换显示进程和CPU状态信息。
c 切换显示命令名称和完整命令行。
M 根据驻留内存大小进行排序。
P 根据CPU使用百分比大小进行排序。
T 根据时间/累计时间进行排序。
W 将当前设置写入~/.toprc文件中。这是写top配置文件的推荐方法。
- 最后的技能:top 命令小技巧
1、输入大写P,则结果按CPU占用降序排序。
2、输入大写M,结果按内存占用降序排序。
3、按数字 1 则可以显示所有CPU核心的负载情况。
4、top -d 5 每隔 5 秒刷新一次,默认 1 秒
5、top -p 4360,4358 监控指定进程
6、top -U johndoe ‘U’为 真实/有效/保存/文件系统用户名。
7、top -u 500 ‘u’为有效用户标识
8、top -bn 1 显示所有进程信息,top -n 1 只显示一屏信息,供管道调用
9、top -M #show memory summary in megabytes not kilobytes
10、top -p 25097 -n 1 -b # -b 避免输出控制字符,管道调用出现乱码
11、top翻页:top -bn1 | less
12、增强版的 top:htop ,一个更加强大的交互式进程管理器:
二、iostat
Linux系统出现了性能问题,一般我们可以通过top、iostat、free、vmstat等命令来查看初步定位问题。其中iostat可以给我们提供丰富的IO状态数据。
1. 基本使用
# iostat -d -k 2 5 #查看TPS和吞吐量信息
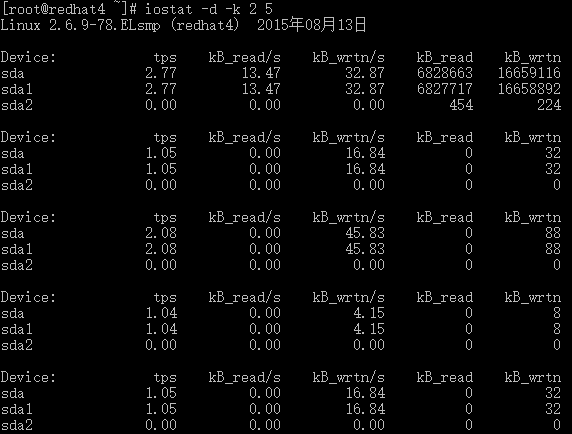
参数 -d 表示,显示设备(磁盘)使用状态;-k某些使用block为单位的列强制使用Kilobytes为单位;2 5表示,数据显示每隔2秒刷新一次,共显示5次。
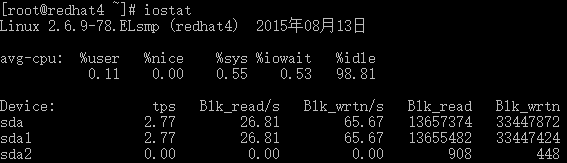
tps:该设备每秒的传输次数(Indicate the number of transfers per second that were issued to the device.)。“一次传输”意思是“一次I/O请求”。多个逻辑请求可能会被合并为“一次I/O请求”。“一次传输”请求的大小是未知的。
kB_read/s:每秒从设备(drive expressed)读取的数据量;kB_wrtn/s:每秒向设备(drive expressed)写入的数据量;kB_read:读取的总数据量;kB_wrtn:写入的总数量数据量;这些单位都为Kilobytes。
2. -x 参数
使用-x参数我们可以获得更多统计信息
# iostat –d –x –k 2 3 #查看设备使用率(%util)、响应时间(await)
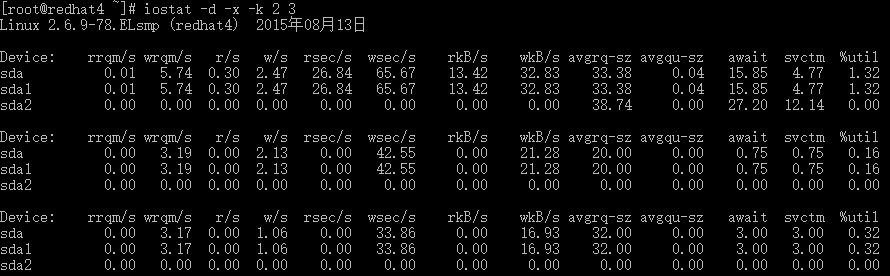
await:每一个IO请求的处理的平均时间(单位是微秒毫秒)。这里可以理解为IO的响应时间,一般地系统IO响应时间应该低于5ms,如果大于10ms就比较大了。
%util:在统计时间内所有处理IO时间,除以总共统计时间。例如,如果统计间隔1秒,该设备有0.8秒在处理IO,而0.2秒闲置,那么该设备的%util = 0.8/1 = 80%,所以该参数暗示了设备的繁忙程度。一般地,如果该参数是100%表示设备已经接近满负荷运行了(当然如果是多磁盘,即使%util是100%,因为磁盘的并发能力,所以磁盘使用未必就到了瓶颈)。
3. -c 参数
# iostat –c 1 3 #查看cpu状态
iostat还可以用来获取cpu部分状态值:
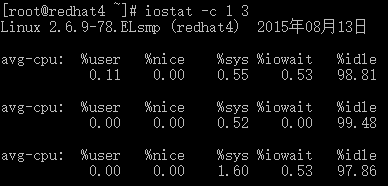
%user: 在用户级别运行所使用的CPU的百分比.
%nice: nice操作所使用的CPU的百分比.
%sys: 在系统级别(kernel)运行所使用CPU的百分比.
%iowait: CPU等待硬件I/O时,所占用CPU百分比.
%idle: CPU空闲时间的百分比.
4.iostat直接使用
# iostat
会直接输出cup段和磁盘段的IO信息
三、vmstat
vmstat命令用于展现给定时间间隔的服务器的状态值,包括服务器的CPU使用率,内存使用,虚拟内存交换情况,IO读写情况。
- 基本使用
# vmstat 2 5 #第一个参数是采样的时间间隔数,单位是秒,第二个参数是采样的次数
#vmstat 2 #一直采集,直到我结束程序
Ctrl+c
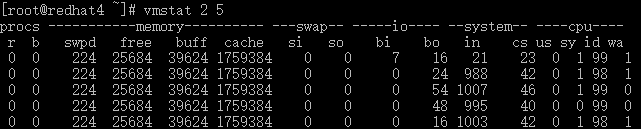
r表示运行队列(就是说多少个进程真的分配到CPU),当这个值超过了CPU数目,就会出现CPU瓶颈了。一般负载超过了3就比较高,超过了5就高,超过了10就不正常了,服务器的状态很危险。top的负载类似每秒的运行队列。如果运行队列过大,表示你的CPU很繁忙,一般会造成CPU使用率很高。
b表示阻塞的进程。
swpd虚拟内存已使用的大小,如果大于0,表示你的机器物理内存不足了。
free空闲的物理内存的大小。
Buff 内核缓存,缓存系统权限等信息。
cache直接用来记忆我们打开的文件,给文件做缓冲, (这里是Linux/Unix的聪明之处,把空闲的物理内存的一部分拿来做文件和目录的缓存,是为了提高 程序执行的性能,当程序使用内存时,buffer/cached会很快地被使用。)
si每秒从磁盘读入虚拟内存的大小,如果这个值大于0,表示物理内存不够用或者内存泄露了,要查找耗内存进程解决掉。
so每秒虚拟内存写入磁盘的大小,如果这个值大于0标示内存不足。
bi块设备每秒接收的块数量,这里的块设备是指系统上所有的磁盘和其他块设备,默认块大小是1024byte
bo块设备每秒发送的块数量, bi和bo一般都要接近0,不然就是IO过于频繁,需要调整。
in每秒CPU的中断次数,包括时间中断
cs每秒上下文切换次数,这个值要越小越好,太大了,要考虑调低线程或者进程的数目,例如在apache和nginx这种web服务器中,我们一般做性能测试时会进行几千并发甚至几万并发的测试,选择web服务器的进程可以由进程或者线程的峰值一直下调,压测,直到cs到一个比较小的值,这个进程和线程数就是比较合适的值了。系统调用也是,每次调用系统函数,我们的代码就会进入内核空间,导致上下文切换,这个是很耗资源,也要尽量避免频繁调用系统函数。上下文切换次数过多表示你的CPU大部分浪费在上下文切换,导致CPU干正经事的时间少了,CPU没有充分利用,是不可取的。
us 用户CPU时间。
sy 系统CPU时间,如果太高,表示系统调用时间长。
id 空闲 CPU时间,一般来说,id + us + sy = 100,一般我认为id是空闲CPU使用率,us是用户CPU使用率,sy是系统CPU使用率。
wt 等待IO CPU时间。
备注: 如果 r经常大于 4 ,且id经常少于40,表示cpu的负荷很重。如果si,so 长期不等于0,表示内存不足。如果bi,bo 经常不等于0, 且在 b中的队列 大于3, 表示 io性能不好。
# vmstat -a 2 3 #显示活跃和非活跃内存
# vmstat –f #查看系统已经fork了多少次,调用
# vmstat –s #查看内存使用的详细信息
# vmstat –d #查看磁盘的读/写
四.Ps
ps命令是Process Status的缩写。ps命令用来列出系统中当前运行的那些进程快照。
ps -ef | grep ora #列出含有ora的进程。
参考资料:
http://www.cnblogs.com/peida/archive/2012/12/19/2824418.html
五.Ipcs
ipcs确定共享内存的使用情况,该命令用于输出系统中处于active状态的消息队列,共享内存段以及信号量的有关消息。
通常最好让整个SGA处于一个单一的共享内存段,因为跟踪一个以上的段将需要额外的开销,在这些段来回切换也需要时间。可以增加/etc/sysctl.conf文件kernel.shmmax参数值,以增加一个单一的共享内存段的最大尺寸。
# Controls the maximum shared segment size, in bytes
kernel.shmmax = 4294967295
六、free 查看系统内存使用情况
Free –m 以M为单位显示内存大小
七、mpstat
mpstat是Multiprocessor Statistics的缩写,是实时系统监控工具。其报告与CPU的一些统计信息,mpstat最大的特点是:可以查看多核心cpu中每个计算核心的统计数据
字段的含义如下
%user #在internal时间段里,用户态的CPU时间(%),不包含nice值为负进程 (usr/total)*100
%nice #在internal时间段里,nice值为负进程的CPU时间(%) (nice/total)*100
%sys #在internal时间段里,内核时间(%) (system/total)*100
%iowait #在internal时间段里,硬盘IO等待时间(%) (iowait/total)*100
%irq #在internal时间段里,硬中断时间(%) (irq/total)*100
%soft #在internal时间段里,软中断时间(%) (softirq/total)*100
%idle #在internal时间段里,CPU除去等待磁盘IO操作外的因为任何原因而空闲的时间闲置时间(%) (idle/total)*100
http://www.cnblogs.com/ggjucheng/archive/2013/01/13/2858775.html
四.Sar
sar(System Activity Reporter系统活动情况报告)可以从多方面对系统的活动进行报告,包括:文件的读写情况、系统调用的使用情况、磁盘I/O、CPU效率、内存使用状况、进程活动及IPC有关的活动等
1.基本命令格式
sar [options] [-A] [-o file] t [n]
t为采样间隔,n为采样次数,默认值是1;
-o file表示将命令结果以二进制格式存放在文件中,file 是文件名。
options 为命令行选项,sar命令常用选项如下:
-A:所有报告的总和
-u:输出CPU使用情况的统计信息
-v:输出inode、文件和其他内核表的统计信息
-d:输出每一个块设备的活动信息
-r:输出内存和交换空间的统计信息
-b:显示I/O和传送速率的统计信息
-a:文件读写情况
-c:输出进程统计信息,每秒创建的进程数
-R:输出内存页面的统计信息
-y:终端设备活动情况
-w:输出系统交换活动信息
2.CPU资源监控
# sar -u 2 3
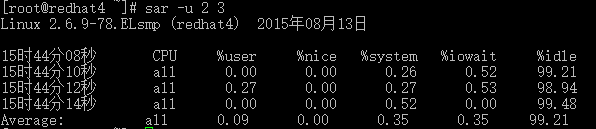
CPU:all 表示统计信息为所有 CPU 的平均值。
%user:显示在用户级别(application)运行使用 CPU 总时间的百分比。
%nice:显示在用户级别,用于nice操作,所占用 CPU 总时间的百分比。
%system:在核心级别(kernel)运行所使用 CPU 总时间的百分比。
%iowait:显示用于等待I/O操作占用 CPU 总时间的百分比。
%steal:管理程序(hypervisor)为另一个虚拟进程提供服务而等待虚拟 CPU 的百分比。
%idle:显示 CPU 空闲时间占用 CPU 总时间的百分比。
若 %iowait 的值过高,表示硬盘存在I/O瓶颈
若 %idle 的值高但系统响应慢时,有可能是 CPU 等待分配内存,此时应加大内存容量
若 %idle 的值持续低于1,则系统的 CPU 处理能力相对较低,表明系统中最需要解决的资源是 CPU 。
3.inode、文件和其他内核表监控
# sar -v 1 4

dentunusd:目录高速缓存中未被使用的条目数量
file-nr:文件句柄(file handle)的使用数量
inode-nr:索引节点句柄(inode handle)的使用数量
pty-nr:使用的pty数量
4. 内存和交换空间监控
# sar -r 1 4

kbmemfree:这个值和free命令中的free值基本一致,所以它不包括buffer和cache的空间.
kbmemused:这个值和free命令中的used值基本一致,所以它包括buffer和cache的空间.
%memused:这个值是kbmemused和内存总量(不包括swap)的一个百分比.
kbbuffers和kbcached:这两个值就是free命令中的buffer和cache.
kbcommit:保证当前系统所需要的内存,即为了确保不溢出而需要的内存(RAM+swap).
%commit:这个值是kbcommit与内存总量(包括swap)的一个百分比.
5. 内存分页监控
# sar -B 1 4
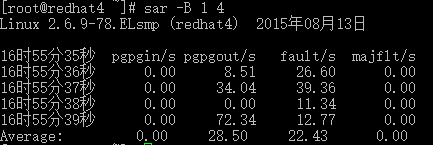
pgpgin/s:表示每秒从磁盘或SWAP置换到内存的字节数(KB)
pgpgout/s:表示每秒从内存置换到磁盘或SWAP的字节数(KB)
fault/s:每秒钟系统产生的缺页数,即主缺页与次缺页之和(major + minor)
majflt/s:每秒钟产生的主缺页数.
pgfree/s:每秒被放入空闲队列中的页个数
pgscank/s:每秒被kswapd扫描的页个数
pgscand/s:每秒直接被扫描的页个数
pgsteal/s:每秒钟从cache中被清除来满足内存需要的页个数
%vmeff:每秒清除的页(pgsteal)占总扫描页(pgscank+pgscand)的百分比
6. I/O和传送速率监控
# sar -b 1 4
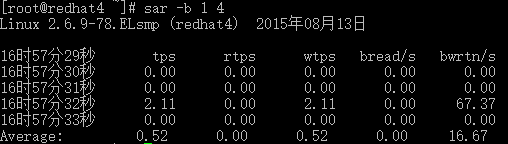
tps:每秒钟物理设备的 I/O 传输总量
rtps:每秒钟从物理设备读入的数据总量
wtps:每秒钟向物理设备写入的数据总量
bread/s:每秒钟从物理设备读入的数据量,单位为 块/s
bwrtn/s:每秒钟向物理设备写入的数据量,单位为 块/s
7. 进程队列长度和平均负载状态监控
# sar -q 1 4
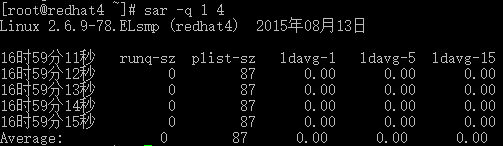
runq-sz:运行队列的长度(等待运行的进程数)
plist-sz:进程列表中进程(processes)和线程(threads)的数量
ldavg-1:最后1分钟的系统平均负载(System load average)
ldavg-5:过去5分钟的系统平均负载
ldavg-15:过去15分钟的系统平均负载
8. 系统交换活动信息监控
# sar -W 1 4
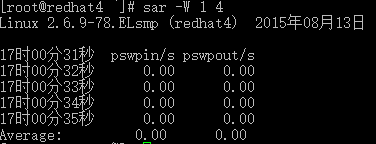
pswpin/s:每秒系统换入的交换页面(swap page)数量
pswpout/s:每秒系统换出的交换页面(swap page)数量
9. 设备使用情况监控
# sar -d 1 4 -p
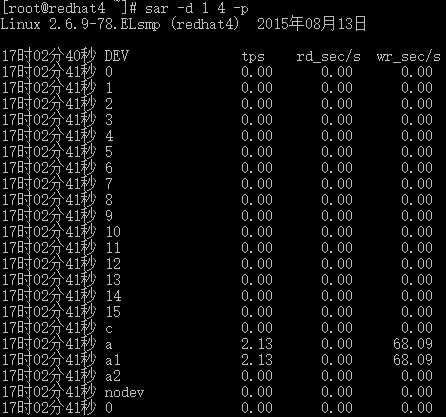
-p可以打印出sda,hdc等磁盘设备名称,如果不用参数-p,设备节点则有可能是dev8-0,dev22-0
tps:每秒从物理磁盘I/O的次数.多个逻辑请求会被合并为一个I/O磁盘请求,一次传输的大小是不确定的.
rd_sec/s:每秒读扇区的次数.
wr_sec/s:每秒写扇区的次数.
avgrq-sz:平均每次设备I/O操作的数据大小(扇区).
avgqu-sz:磁盘请求队列的平均长度.
await:从请求磁盘操作到系统完成处理,每次请求的平均消耗时间,包括请求队列等待时间,单位是毫秒(1秒=1000毫秒).
svctm:系统处理每次请求的平均时间,不包括在请求队列中消耗的时间.
%util:I/O请求占CPU的百分比,比率越大,说明越饱和.
10.使用建议
avgqu-sz 的值较低时,设备的利用率较高。
当%util的值接近 1% 时,表示设备带宽已经占满。
要判断系统瓶颈问题,有时需几个 sar 命令选项结合起来
怀疑CPU存在瓶颈,可用 sar -u 和 sar -q 等来查看
怀疑内存存在瓶颈,可用 sar -B、sar -r 和 sar -W 等来查看
怀疑I/O存在瓶颈,可用 sar -b、sar -u 和 sar -d 等来查看
五、pmap
用于显示一个或多个进程的内存状态。其报告进程的地址空间和内存状态信息,进程号可以通过top和ps命令获取
用法
pmap [ -x | -d ] [ -q ] pids...
pmap -V
选项含义
-x extended Show the extended format. 显示扩展格式
-d device Show the device format. 显示设备格式
-q quiet Do not display some header/footer lines. 不显示头尾行
-V show version Displays version of program. 显示版本
Address: start address of map 映像起始地址
Kbytes: size of map in kilobytes 映像大小
RSS: resident set size in kilobytes 驻留集大小
Dirty: dirty pages (both shared and private) in kilobytes 脏页大小
Mode: permissions on map 映像权限: r=read, w=write, x=execute, s=shared, p=private (copy on write)
Mapping: file backing the map , or '[ anon ]' for allocated memory, or '[ stack ]' for the program stack. 映像支持文件,[anon]为已分配内存 [stack]为程序堆栈
Offset: offset into the file 文件偏移
Device: device name (major:minor) 设备名
# pmap -d 1 #查看进程1的设备格式
最后一行的值
mapped 表示该进程映射的虚拟地址空间大小,也就是该进程预先分配的虚拟内存大小,即ps出的vsz
writeable/private 表示进程所占用的私有地址空间大小,也就是该进程实际使用的内存大小
shared 表示进程和其他进程共享的内存大小
# pmap -x 1 #查看进程1的扩展格式
# pmap -d -q 1 #查看进程1的设备格式,不显示头尾行
# while true; do pmap -d 512 | tail -1; sleep 2 ;done#循环显示进程512的设备格式的最后1行,间隔2秒
# pmap 8101
我们可以检查多进程内存通过插入多个PID。加入多个PID中间使用空格分隔。
六.Prstat
Solaris 中最重要、使用最广的实用工具,用于查询
*系统占用了多少 CPU 和内存
*系统效用了哪些进程(或用户、 zone 、项目、任务)
*系统怎样使用进程/线程(用户绑定,I/O 绑定)
命令执行结果列解释
*PID:进程的进程 ID。
*USERNAME:真实用户(登录)名称或真实用户 ID。
*SIZE:进程的总虚拟内存大小,以 K、M 或 G 为单位。
*RSS:进程的驻留集大小 (RSS),以 K、M 或 G 为单位。
*STATE:进程的状态 (cpuN/sleep/wait/run/zombie/stop)。
*PRI:进程的优先级。数字更大表示优先级更高。
*NICE:优先级计算中使用的 nice 值。只有特定调度类中的进程才有 nice 值。
*TIME:进程的累计执行时间。
*CPU:进程使用的当前 CPU 时间的百分比。如果在非全局域中执行并且池设备是活动的,百分比将是 zone 绑定的池所使用的处理器集合中处理器的百分比。
*PROCESS:进程的名称(执行文件的名称)。
*NLWP:进程中 lwps 的数量。
参考资料:http://www.360doc.com/content/09/0905/06/222683_5597972.shtml
七.Filemon
filemon 命令跟踪设备来获取一段时间间隔内的 I/O 活动的详细图像,该时间间隔产生于文件系统应用的不同层面,包括本地文件系统、虚拟内存段、LVM 和物理磁盘层。
参考资料:http://blog.chinaunix.net/uid-20274021-id-1969394.html
八.Nmon
Nmon 工具是 IBM 提供的免费的在AIX与各种Linux操作系统上广泛使用的监控与分析工具。该工具可将服务器的系统资源耗用情况收集起来并输出一个特定的文件,并可利用 excel 分析工具nmonanalyser进行数据的统计分析。并且,nmon运行不会占用过多的系统资源,通常情况下CPU利用率不会超过2%
参考资料:http://bbs.chinaunix.net/thread-3670590-1-1.html
九.Svmon
svmon 命令提供了一个更加深入的内存使用情况的分析。比起 vmstat 和 ps 命令,它带有更多信息量,并且更具有强制性。svmon 命令捕获一个当前内存状态的快照。然而,这并不是一个真正的快照,因为它运行在用户级别,即中断允许状态。
参考资料:http://blog.itpub.net/7199859/viewspace-666329/















 3600
3600











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









