






先说下CPU的缓存吧,都知道CPU的缓存是分为L1,L2和L3的,L1又分为数据缓存和指令缓存,每颗CPU核心都有自己的L1和L2,但L3是各核心共享的,一但涉及共享的东西,当然就有竞争咯。
SMP(SymmetricalMulti-Processing,对称多处理器)架构:
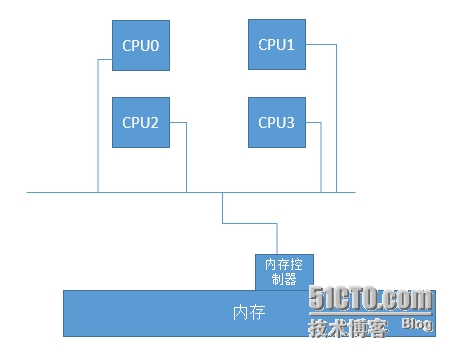
在一个主板上,能放置多颗CPU,例如4颗,如果每颗4核,那么一共就是16个核心,这种架构存在什么问题呢?我们设想一下,CPU有多个,但我的内存只有一个,同样的,内存控制器也是只有一个的,那么当我其中的一个CPU去与内存控制器进行交互的时候,其它CPU此时此刻能不能同时与我们的内存控制器交互呢?很显然,不能了,所以,CPU的颗数越多,那么资源竞争的越激烈,同样,性能可能会不容乐观,所以这种架构一般会随着CPU的增多,性能可能会逐渐下降。
架构图类似下图:

NUMA(Non-Uniform Memory Access Architecture,非一致性内存访问)架构:
由于SMP架构下,多颗CPU之间抢占资源较为激烈,所以NUMA通常有一组CPU(一般为2颗,可能会更多)和本地内存组成,每一颗CPU都有自己独有的内存,这样,就大大避免了多颗CPU之间内存争用和总线争用的问题,并且本地CPU和内存间距离较短,传输速度及快,但是如果我们要访问的数据在对方的内存上,这样,性能就会有所下降,可能会很疑惑,我的本地CPU要访问的数据怎么会在对方的CPU上呢?默认情况下,如果我们运行了100个进程,CPU0和CPU1各运行50个进程,当然,进程所占用的数据还在内存上,过了一会,CPU0结束了10个进程,还运行40个进程,CPU1结束了40个进程,还运行10个进程,此时,CPU根据默认策略,会自动平衡,使两边CPU各运行的进程尽可能的一样多,那么原来在CPU0上运行的进程就会跑到CPU1上去,那么当我们再次访问进程数据时,就会出现交叉内存访问了。等到下一篇在说如何绑定吧。先看下架构图吧:

NUMA内存交叉访问为什么速度会慢?
正常情况下CPU访问一次内存,最快需要3个时钟周期:
向内存控制器传输一个寻址的指令,内存控制器在返回一个值----->CPU确认内存地址,并施加访问的机制,类似锁机制----〉进行读写操作
在正常情况下访问如上过程,但出现交叉访问是如下过程:
向内存控制器传输一个寻址指令----〉访问对方的内存控制器,并施加访问机制----〉对数据进行读写操作
此过程中 由本地内存控制器访问对方内存控制器需要3个时钟周期,所以,出现交叉内存访问会最快会使用6个时钟周期。
转载于:https://blog.51cto.com/hl914/1557231














 5427
5427











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}