






1.折半查找(代码来自我做题亲测,没问题,比较简单就不粘完整代码了)
说白了就是借助二分思想对有序序列进行二分查找
非递归实现:比较慢,用非递归实现交了一发题,超时,递归就A了
while(l<r) { if(aim==ans[mid]){ printf("%d\n",mid); return 0; }else if(aim<ans[mid]){ r=mid; mid=(l+r)/2; }else{ l=mid; mid=(l+r)/2; } }
递归实现:
int Search(int a[],int L,int R,int K) { if(R<L) return 0; else { int mid=(L+R)/2; if(K<a[mid]) Search(a,L,mid-1,K); else if(K>a[mid]) Search(a,mid+1,R,K); else return mid; } }
2.二叉排序树
一棵若根如左子树非空小于根节点,右子树非空大于根节点的树。也可以是空树。
类的声明:
class BiSortTree{ public: BiSortTree(int a[ ], int n); ~ BiSortTree( ); void InsertBST(BiNode<int> * &root , BiNode<int> *s); void DeleteBST(BiNode<int> *p, BiNode<int> *f ); BiNode<int> *SearchBST(BiNode<int> *root, int k); private: BiNode<int> *root; };
构造一棵二叉排序树:
BiSortTree::BiSortTree(int r[ ], int n) { for (i=0; i<n; i++) { s=new BiNode<int>; s->data=r[i]; s->lchild=s->rchild=NULL; InsertBST(root, s); } }
插入操作:
void BiSortTree::InsertBST(BiNode<int> * &root, BiNode<int> *s) { if (root==NULL) root=s; else if (s->data<root->data) InsertBST(root->lchild, s); else InsertBST(root->rchild, s); }
删除:课件代码此处有误,书上的仅分析了左子树的情况,此代码为课件代码修改后的。
void BiSortTree::DeleteBST(BiNode<int> *p, BiNode<int> *f ) { if (!p->lchild && !p->rchild) { //节点P为叶子节点,直接删除 if(f->lchild==p) f->lchild= NULL; else f->rchild= NULL; delete p; } else if (!p->rchild) { //p只有左子树,p的右子树为空 if(f->lchild==p) f->lchild=p->lchild; else f->rchild=p->lchild; delete p; } else if (!p->lchild) { //p只有右子树 if(f->lchild==p) f->lchild=p->rchild; else f->rchild=p->rchild; delete p; } else { //左右子树均不空 par=p; s=p->rchild; while (s->lchild!=NULL) //查找最左下结点(特殊情况时此循环不执行) { par=s; s=s->lchild; } p->data=s->data; if (par==p) p->rchild=s->rchild; //处理特殊情况 else par->lchild=s->rchild; //一般情况 delete s; } //左右子树均不空的情况处理完毕 }
解释:特殊情况,p的右子树无左子树时,此时的p的右子树即为s,将s的数据域赋值给p后,s节点是需要删除的,因此可将s的右子树赋值给p的右子树代替原来s的位置,然后在=再释放s的空间。

一般情况:(较为简单,理解不难)
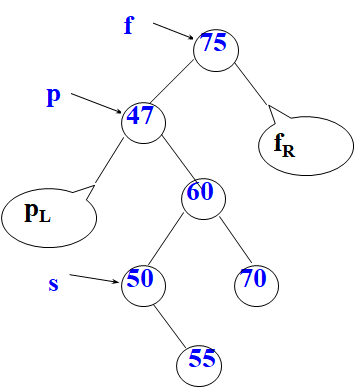
二叉排序树的查找:
BiNode *BiSortTree::SearchBST(BiNode<int> *root, int k) { if (root==NULL) return NULL; else if (root->data==k) return root; else if (k<root->data) return SearchBST(root->lchild, k); else return SearchBST(root->rchild, k); }
3.平衡二叉树
一棵根节点的左右子树深度最多相差1的树,且左右子树也是平衡二叉树的树。包括空树。
最小不平衡子树:在平衡数树的构造过程中,以距离插入节点最近、且平衡因子的绝对值大于1的节点为根的子树。
转化方法:略(仔细模拟一遍就OK了)
4.散列(hash)表的查找技术
基本思想:在记录的存储位置和它的关键码之间建立一个确定的对应关系,一次就读取到所查元素的查找方法。
散列表:采取散列技术将记录存储在一块连续的存储空间中,这块连续的存储空间称为散列表。
散列函数:将关键码映射为散列表中适当存储位置的函数。
散列地址:由散列函数所得的存储位置的地址。
散列函数:1.直接定址法
2.除留余数法
3.数字分析法
4.平方取中法
5.折叠法
解决冲突:线性探测法
int HashSearch1(int ht[ ], int m, int k) { j=H(k); //根据散列函数查找关键码地址 if (ht[j]==k) return j; //没有发生冲突,比较一次查找成功 i=(j+1) % m; while (ht[i]!=Empty && i!=j) { if (ht[i]==k) return i; //发生冲突,比较若干次查找成功 i=(i+1) % m; //向后探测一个位置 } if (i==j) throw "溢出"; else ht[i]=k; //查找不成功时插入 }
二次探测:当发生冲突时,寻找 下一个散列地址公式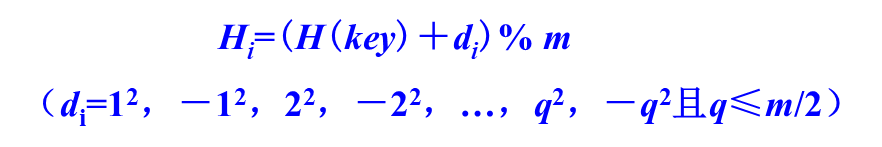
随机探测法:当发生冲突时,下一个散列地址的位移量是一个随机数列,寻找下一个散列地址的公式:

拉链法:
Node<int> *HashSearch2(Node<int> *ht[ ], int m, int k) { j=H(k); p=ht[j]; while (p && p->data!=k) p=p->next; if (p->data= =k) return p; else { q=new Node<int>; q->data=k; q->next= ht[j]; ht[j]=q; } }














 801
801











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









