






思考:
一个程序,如果要实现“统计文章中的前十位高频单词”的功能,首先、要有输入或者读入所要统计的文章;其次、就是如何对文章文本进行分析,断词(即提取出一个个单词)、计数、排序;最后要求有输出部分。难点在于如何断词与排序。
实现:
- 读入文章文本
利用StreamReader类(具体请查阅http://msdn.microsoft.com/zh-cn/library/system.io.streamreader(v=vs.110).aspx)从特定路径一特定编码的形式读入;
字符串textstring变量存文本,为后续文本分析做准备。
StreamReader sr = new StreamReader(@path, Text.Encoding.GetEncoding("GB2312")); textstring = sr.ReadToEnd();
这样,我就可以自定义路径来读入所需要查询的文本了。
2.断词
最初,我想的是利用数组操作进行对单词的提取,例如:利用if和switch语句配合字符串数组与整形数组进行操作,进行对每个单词的提取。(o(╯□╰)o但这样很明显工作量很大);通过查询资料发现Regex类刚好实现这个功能(http://msdn.microsoft.com/zh-cn/library/system.text.regularexpressions.regex(v=vs.110).aspx)。
Regex regex = new Regex(Pattern); //针对指定的正则表达式初始化 Regex 类的新实例
其中的Pattern就是我们所需要定义的正则表达式了(空格,逗号等用来区分单词的标点符号与特殊字符);那如何利用regex实例来分割出单词呢?这里要用到它的split()方法了。
string[] words = regex.Split(textstring);//在由 Regex 构造函数指定的正则表达式模式所定义的位置,将输入字符串拆分为子字符串数组。
3. 计数
利用HashTable(http://msdn.microsoft.com/zh-cn/library/system.collections.hashtable(VS.80).aspx)来进行对单词的统计,充分利用其键和值得特性(键 存word,值 存次数);
foreach (string word in words) { try { if (hash.Contains(word))//排除重复 { int j = Convert.ToInt32(hash[word]) + 1; hash.Remove(word); hash.Add(word, j); } else { hash.Add(word, 1);//如果不含有word则加入word还有对应value值 } } catch { MessageBox.Show ("出现null和空"); } }
注意:这就出现了一个Contain()方法引发隐含的问题,那就是对于AAA与A这两个单词就会默认键相等,值+1,操作。产生错误(这个错误易引发后面排序混乱)。
4.排序
首先由于没有注意到上面错误,第一次排序,我使用的是冒泡法排序。
for (int a = 0; a < akeys.Count; a++) { for (int b = a + 1; b < akeys.Count; b++) { if (valuearray[a] > valuearray[b]) { int temp = valuearray[a]; valuearray[a] = valuearray[b]; valuearray[b] = temp; valuearray[a] = valuearray[b]; string tempstr = keyarray[a]; keyarray[a] = keyarray[b]; keyarray[b] = tempstr; } } }
但是,输出结果明显不对,返回到Contain()方法引发隐含的问题中分析,发现问题在于如何在排序的过程中纠正AAA中值(计数)的错误
/*int temp = valuearray[a]; valuearray[a] = valuearray[b]; valuearray[b] = temp; valuearray[a] = valuearray[b];*/ //分析AAA与A的特点,利用位操作来纠正AAA中的值 即 AAA的值域A的值进行位操作 valuearray[a] ^= valuearray[b]; //排除AAA 与A这样的情况 valuearray[b] ^= valuearray[a]; valuearray[a] ^= valuearray[b];
优化及界面设计:
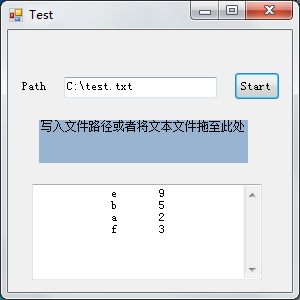
这里值的注意的就是拖拽功能的实现~同时要获取与同步Path。
private void label2_DragDrop(object sender, DragEventArgs e) { //其中label1.Text显示的就是拖进文件的文件名; string filePath = ((System.Array)e.Data.GetData(DataFormats.FileDrop)).GetValue(0).ToString(); if (!string.IsNullOrEmpty(filePath)) { path = filePath; textBox1.Text = filePath; } } private void label2_DragEnter(object sender, DragEventArgs e) { if (e.Data.GetDataPresent(DataFormats.FileDrop)) e.Effect = DragDropEffects.Link; else e.Effect = DragDropEffects.None; }
错误记录:
HashTable的hash.Remove(word);hash.Add(word, j);与hash.[word]=j在计数时候的应用。
数据之间的强制转换,例如:int.Parse是转换String为int; Convert.ToInt32是转换继承自Object的对象为int的. 你得到一个object对象,你想把它转换为int,用int.Parse就 不可以,要用Convert.ToInt32.
排序过程。
如何实现拖拽功能。
时间记录日志:
20140225确定程序大体框架(20M)
20140226实现初步功能,并查找相关资料,改良。(3H)
20140227完善功能,制作界面。(1H)














 6581
6581











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









