







1.写入性能
测试用户表在无索引、全局索引、本地索引三种情况下,插入数据的效率。无索引情况下数据插入最快,有索引情况下本地索引写入优于全局索引。
TABLE TESTA:
#建表
CREATE TABLE testa
(
hrid varchar not null primary key,
parentid bigint,
departmentid varchar
);
#插入数据
upsert into testa select hrid,parentid,departmentid from tmp_staff;
TABLE TESTB:
#建表
CREATE TABLE testb
(
hrid varchar not null primary key,
parentid bigint,
departmentid varchar
);
#建全局索引
CREATE INDEX IDX_TESTB_DEPARTMENTID ON TESTB(departmentid);
#插入数据
upsert into testb select hrid,parentid,departmentid from tmp_staff;
TABLE TESTC:
#建表
CREATE TABLE testc
(
hrid varchar not null primary key,
parentid bigint,
departmentid varchar
);
#建本地索引
CREATE LOCAL INDEX IDX_TESTC_LOCAL_DEPARTMENTID ON TESTC(departmentid);
#插入数据
upsert into testc select hrid,parentid,departmentid from tmp_staff;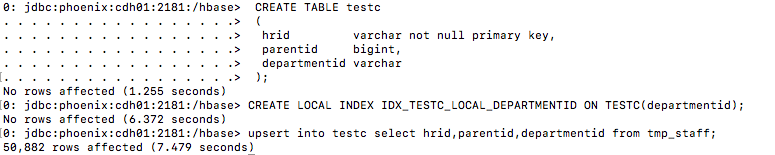
写入性能对比:
| testa | testb | testsc | |
| index config | without index | global index | local index |
| upsert 50086 rows | 5.06s | 9.573s | 7.479s |
2.执行计划
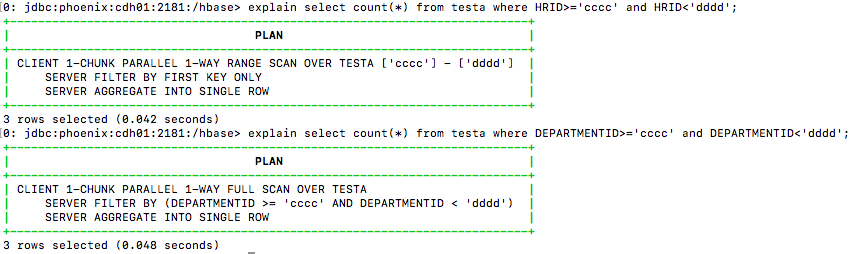
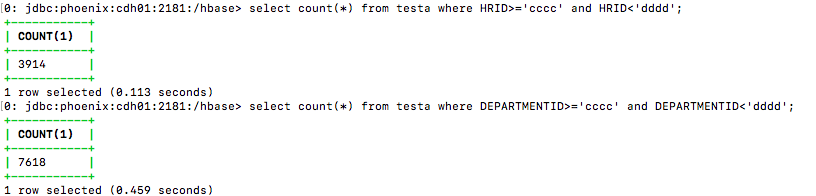
Rowkey与normalCol:
比较表在通过Rowkey筛选、通过Column筛选两种情况的执行计划。对Rowkey进行筛选表自动选择了表范围扫描、对Column进行筛选表选择了全表扫描。Rowkey性能数倍于普通Column。
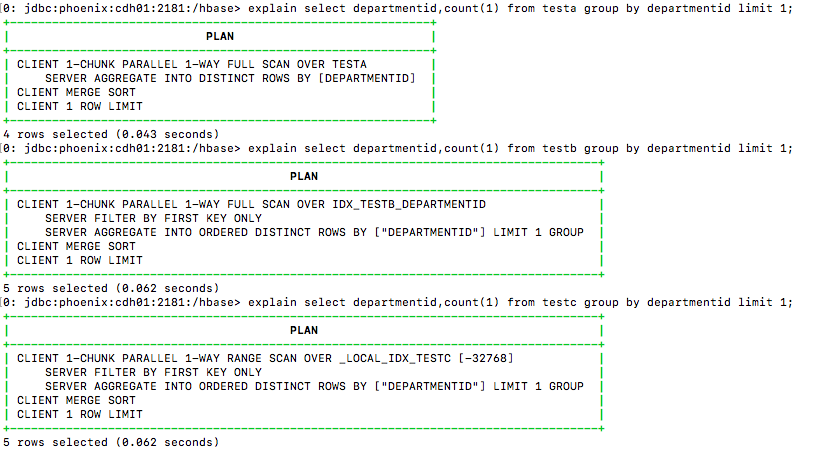
withIndex与withoutIndex:
比较表在无索引、全局索引、本地索引三种情况下,对表的indexCol进行聚合操作的执行计划。TESTA对表进行全扫描、TESTB对索引进行全扫描、TESTC对本地索引进行范围扫描。
3.查询性能
比较表在无索引、全局索引、本地索引三种情况下,不同的查询语句性能。
无索引表:对比无法用到索引的索引表时性能更优
全局索引表:在走索引的情况下性能明显优于本地索引和无索引表,不走索引情况下性能尚可
本地索引表:在走索引的情况下性能优于无索引表,不走索引情况下性能较差,其优势更多是在写入速度
A:count
select count(1) from table_name;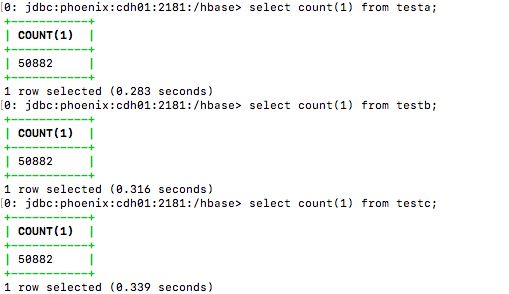
B:count/filter indexCol
select count(1) from table_name where departmentid='air';
C:count/group by indexCol
select departmentid,count(1) from table_name group by departmentid limit 1;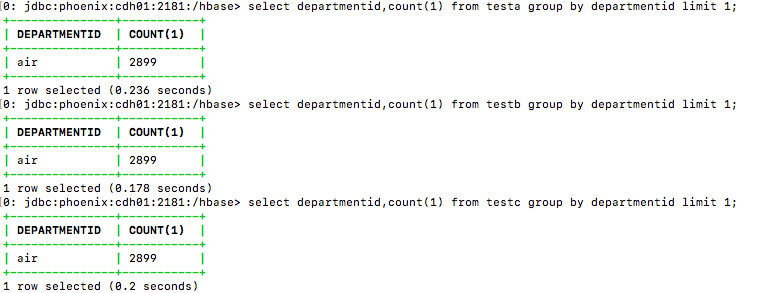
D:count/group by normalCol
select parentid,count(1) from table_name group by parentid limit 1;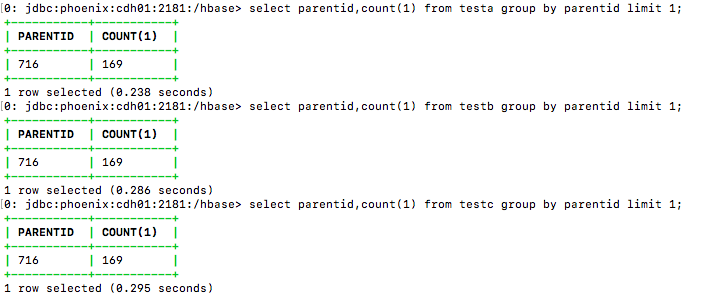
E:count/filter indexCol/group by normalCol
select parentid,count(1) from table_name where departmentid='air' group by parentid limit 1;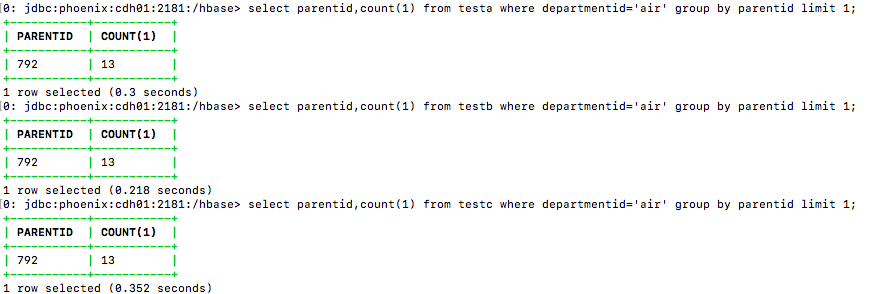
F:count/join indexCol
select count(*) from department m join table_name n on m.departmentid=n.departmentid;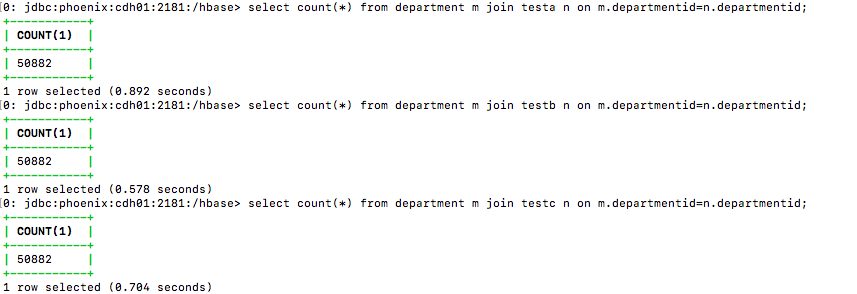
查询性能对比:
| select | testa | testb | 0.testc |
| index config | without index | global index | local index |
| A:count | 0.283 | 0.316 | 0.339 |
| B:count/filter indexCol | 0.191 | 0.095 | 0.096 |
| C:count/group by indexCol | 0.236 | 0.178 | 0.2 |
| D:count/group by normalCol | 0.238 | 0.286 | 0.295 |
| E:count/filter indexCol/group by normalCol | 0.3 | 0.218 | 0.352 |
| F:count/join indexCol | 0.892 | 0.578 | 0.704 |
4.SALT_BUCKETS
加盐的原理是在原始的rowkey前加上一个byte,并填充由rowkey计算得出的hash值,使得原本连续的rowkeys被均匀打散到多个region中,有效地解决了读写热点问题。Phoenix会将一个聚合查询分成多个Scan,然后将这些Scan分配给phoenix自定义的hbase协处理器,这些协处理器可以在服务器端并行执行来提高查询性能。
TESTM:
#建表、加盐预分区一个region
CREATE TABLE testm
(
hrid varchar not null primary key,
parentid bigint,
departmentid varchar
)SALT_BUCKETS=1;
#建立索引、加盐预分区一个region
CREATE INDEX IDX_TESTM_DEPARTMENTID ON TESTM(departmentid) SALT_BUCKETS=1;
#插入数据
upsert into testm select hrid,parentid,departmentid from tmp_staff;
TESTN:
#建表、加盐预分区四个region
CREATE TABLE testn
(
hrid varchar not null primary key,
parentid bigint,
departmentid varchar
)SALT_BUCKETS=4;
#建索引、加盐预分区两个region
CREATE INDEX IDX_TESTN_DEPARTMENTID ON TESTN(departmentid) SALT_BUCKETS=2;
#插入数据
upsert into testn select hrid,parentid,departmentid from tmp_staff;
写入性能对比(不同bucket):
| testm(global index) | testn(global index) | |
| buckets config | table buckets=1, index buckets=1 | table buckets=4, index buckets=2 |
| upsert 50086 rows | 7.265s | 6.943s |















 3702
3702











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









