







Heartbeat 官方介绍
Heartbeat is a daemon that provides cluster infrastructure (communication and membership) services to its clients. This allows clients to know about the presence (or disappearance!) of peer processes on other machines and to easily exchange messages with them.
In order to be useful to users, the Heartbeat daemon needs to be combined with a cluster resource manager (CRM) which has the task of starting and stopping the services (IP addresses, web servers, etc.) that cluster will make highly available. Pacemaker is the preferred cluster resource manager for clusters based on Heartbeat.
Heartbeat 是什么
Heartbeat是Linux-HA项目中的一个组件,也是目前开源HA项目中最成功的一个例子,它提供了所有 HA 软件所需要的基本功能,比如心跳检测和资源接管、监测群集中的系统服务、在群集中的节点间转移共享 IP 地址的所有者等,自1999年开始到现在,Heartbeat在行业内得到了广泛的应用。heartbeat最核心的功能包括两个部分,心跳监测和资源接管。心跳监测可以通过网络链路和串口进行,而且支持冗 余链路,它们之间相互发送报文来告诉对方自己当前的状态,如果在指定的时间内未收到对方发送的报文,那么就认为对方失效,这时需启动资源接管模块来接管运行在对方主机上的资源或者服务。
HA集群中的相关术语
.节点(node)
运行heartbeat进程的一个独立主机,称为节点,节点是HA的核心组成部分,每个节点上运行着操作系统和heartbeat软件服务,在heartbeat集群中,节点有主次之分,分别称为主节点和备用/备份节点,每个节点拥有唯一的主机名,并且拥有属于自己的一组资源,例如,磁盘、文件系统、网络地址和应用服务等。主节点上一般运行着一个或多个应用服务。而备用节点一般处于监控状态。
.资源(resource)
资源是一个节点可以控制的实体,并且当节点发生故障时,这些资源能够被其它节点接管,heartbeat中,可以当做资源的实体有:
- 磁盘分区、文件系统
- IP地址
- 应用程序服务
- NFS文件系统
.事件(event)
也就是集群中可能发生的事情,例如节点系统故障、网络连通故障、网卡故障、应用程序故障等。这些事件都会导致节点的资源发生转移,HA的测试也是基于这些事件来进行的。
.动作(action)
事件发生时HA的响应方式,动作是由shell脚步控制的,例如,当某个节点发生故障后,备份节点将通过事先设定好的执行脚本进行服务的关闭或启动。进而接管故障节点的资源。
Heartbeat的组成与原理
.Heartbeat的组成
Heartbeat提供了高可用集群最基本的功能,例如,节点间的内部通信方式、集群合作管理机制、监控工具和失效切换功能等等,目前的最新版本是Heartbeat2.x,这里的讲述也是以Heartbeat2.x为主,下面介绍Heartbeat2.0的内部组成,主要分为以下几大部分:
- heartbeat: 节点间通信检测模块
- ha-logd: 集群事件日志服务
- CCM(Consensus Cluster Membership):集群成员一致性管理模块
- LRM (Local Resource Manager):本地资源管理模块
- Stonith Daemon: 使出现问题的节点从集群环境中脱离
- CRM(Cluster resource management):集群资源管理模块
- Cluster policy engine: 集群策略引擎
- Cluster transition engine:集群转移引擎
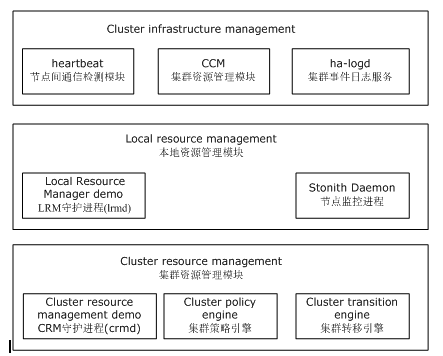
如图显示了Heartbeat2.0内部结构组成
Heartbeat仅仅是个HA软件,它仅能完成心跳监控和资源接管,不会监视它控制的资源或应用程序,要监控资源和应用程序是否运行正常,必须使用第三方的插件,例如ipfail、Mon、Ldirector等。Heartbeat自身包含了几个插件,分别是ipfail、Stonith和Ldirectord,介绍如下:
ipfail的功能直接包含在Heartbeat里面,主要用于检测网络故障,并作出合理的反应,为了实现这个功能,ipfail使用ping节点或者ping节点组来检测网络连接是否出现故障,从而及时的做出转移措施。
Stonith插件可以在一个没有响应的节点恢复后,合理接管集群服务资源,防止数据冲突,当一个节点失效后,会从集群中删除,如果不使用Stonith插件,那么失效的节点可能会导致集群服务在多于一个节点运行,从而造成数据冲突甚至是系统崩溃。因此,使用Stonith插件可以保证共享存储环境中的数据完整性。
Ldirector是一个监控集群服务节点运行状态的插件。Ldirector如果监控到集群节点中某个服务出现故障,就屏蔽此节点的对外连接功能,同时将后续请求转移到正常的节点提供服务,这个插件经常用在LVS负载均衡集群中,关于Ldirector插件的使用,将在后面详细讲述。
同样,对于操作系统自身出现的问题,Heartbeat也无法监控,如果主节点操作系统挂起,一方面可能导致服务中断,另一方面由于主节点资源无法释放,而备份节点却接管了主节点的资源,此时就发生了两个节点同时争用一个资源的状况。
针对这个问题,就需要在linux内核中启用一个叫watchdog的模块,watchdog是一个Linux内核模块,它通过定时向/dev/watchdog设备文件执行写操作,从而确定系统是否正常运行,如果watchdog认为内核挂起,就会重新启动系统,进而释放节点资源。
在linux中完成watchdog功能的软件叫softdog,softdog维护一个内部计时器,此计时器在一个进程写入/dev/watchdog设备文件时更新,如果softdog没有看到进程写入/dev/watchdog文件,就认为内核可能出了故障。watchdog超时周期默认是一分钟,可以通过将watchdog集成到Heartbeat中,从而通过Heartbeat来监控系统是否正常运行。
.Heartbeat的工作原理
heartbeat内部结构有三大部分组成。
集群成员一致性管理模块(CCM)用于管理集群节点成员,同时管理成员之间的关系和节点间资源的分配,heartbeat模块负责检测主次节点的运行状态,以决定节点是否失效。ha-logd模块用于记录集群中所有模块和服务的运行信息。
本地资源管理器(LRM)负责本地资源的启动,停止和监控,一般由LRM守护进程lrmd和节点监控进程(Stonith Daemon)组成,lrmd守护进程负责节点间的通信,Stonith Daemon通常是一个Fence设备,主要用于监控节点状态,当一个节点出现问题时处于正常状态的节点会通过Fence设备将其重启或关机以释放IP、磁盘等资源,始终保持资源被一个节点拥有,防止资源争用的发生。
集群资源管理模块(CRM)用于处理节点和资源之间的依赖关系,同时,管理节点对资源的使用,一般由CRM守护进程crmd、集群策略引擎和集群转移引擎三个部分组成,集群策略引擎(Cluster policy engine)具体实施这些管理和依赖,集群转移引擎(Cluster transition engine)监控CRM模块的状态,当一个节点出现故障时,负责协调另一个节点上的进程进行合理的资源接管。
在Heartbeat集群中,最核心的是heartbeat模块的心跳监测部分和集群资源管理模块的资源接管部分,心跳监测一般由串行接口通过串口线来实现,两个节点之间通过串口线相互发送报文来告诉对方自己当前的状态,如果在指定的时间内未受到对方发送的报文,那么就认为对方失效,这时资源接管模块将启动,用来接管运行在对方主机上的资源或者服务。
环境说明
| 主节点 | 从节点 | |
|---|---|---|
| 主机名 | s1 | s2 |
| IP | 192.168.1.201 | 92.168.1.202 |
| VIP | 192.168.1.100 | |
| 运行的服务 | Haproxy |
准备工作
设置主机名设置
[root@s1 ha.d]# hostname s1
[root@s1 ha.d]#vim /etc/sysconfig/network
HOSTNAME=s1
[root@s2 ha.d]# hostname s2
[root@s2 ha.d]#vim /etc/sysconfig/network
HOSTNAME=s2关闭防火墙和selinux
s1,s2:
service iptables stop
setenforce 0
sed -i 's/SELINUX=enforcing/SELINUX=disabled/' /etc/selinux/config
host设置
s1,s2:
cat /etc/hosts
192.168.1.202 s1
192.168.1.203 s2安装
s1,s2:
yum install -y epel-release
yum install -y heartbeat* libnet主节点配置
cd /usr/share/doc/heartbeat-3.0.4/
cp authkeys ha.cf haresources /etc/ha.d/
cd /etc/ha.d 配置authkeys
vim authkeys
auth 3
3 md5 Hello!
chmod 600 authkeys配置ha.cf
vim ha.cf
debugfile /var/log/ha-debug
logfile /var/log/ha-log
logfacility local0
keepalive 2
deadtime 30
warntime 10
initdead 60
udpport 694
ucast eth0 192.168.1.203
auto_failback on
node s1
node s2
ping 192.168.1.2 192.168.1.203
respawn hacluster /usr/lib64/heartbeat/ipfail配置haresources文件
vim /etc/ha.d/haresources
192.168.1.100/24/eth0:0 haproxy
从节点配置
传输配置文件
cd /etc/ha.d
scp authkeys ha.cf haresources slave:/etc/ha.d注:
要将 /etc/ha.d/ha.cf 的 ucast改成 ucast eth0 192.168.1.202。
服务启动
[root@s1 ha.d]# service heartbeat start
[root@s1 ha.d]# service haproxy start
[root@s2 ha.d]# service heartbeat start查看VIP
[root@s1 ha.d]# ifconfig |grep 192.168.1.100
inet addr:192.168.1.100 Bcast:192.168.1.255 Mask:255.255.255.0
[root@s2 ~]# ifconfig |grep 192.168.1.100此时VIP在主节点这边。
模拟故障
停掉s1的 heartbeat
[root@s1 ha.d]# service heartbeat stop
Stopping High-Availability services: Done.
[root@s1 ha.d]# service haproxy status
haproxy 已停当主节点 heartbeat 停止服务之后,haproxy也停止工作了。 去从节点看看,
[root@s2 ~]# ifconfig |grep 192.168.1.100
inet addr:192.168.1.100 Bcast:192.168.1.255 Mask:255.255.255.0
[root@s2 ~]# service haproxy status
haproxy (pid 10045 10044 10043 10042 10041 10040 10039 10038) is running...VIP已经漂移到s2,并且s2上的haproxy已经开始工作。















 858
858











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









