






MATLAB实现K-means算法
MATLAB实现K-means算法
关于K-means算法的原理:Kmeans聚类算法
main.m
clc;
clear;
% 第一类数据
% 均值
mu1 = [-2 -2];
% 协方差
S1 = [0.5 0; 0 0.5];
% 产生高斯分布数据
data1 = mvnrnd(mu1, S1, 100);
% 第二类数据
mu2 = [2 -2];
S2 = [0.5 0; 0 0.5];
data2 = mvnrnd(mu2, S2, 100);
% 第三类数据
mu3 = [-2 2];
S3 = [0.5 0; 0 0.5];
data3 = mvnrnd(mu3, S3, 100);
% 第四类数据
mu4 = [2 2];
S4 = [0.5 0; 0 0.5];
data4 = mvnrnd(mu4, S4, 100);
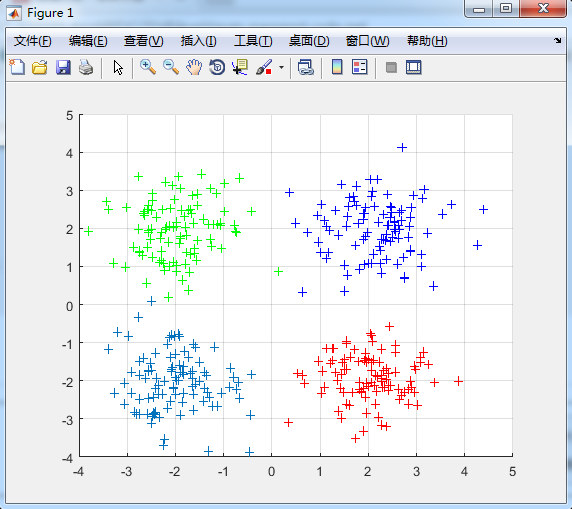
% 显示数据
figure();
hold on;
plot(data1(:,1), data1(:,2), '+');
plot(data2(:,1), data2(:,2), 'r+');
plot(data3(:,1), data3(:,2), 'g+');
plot(data4(:,1), data4(:,2), 'b+');
grid on;
data = [data1; data2; data3; data4];
% 数据聚类
[idx, ctr] = k_means(data, 4, 1000);
[m, n] = size(idx);
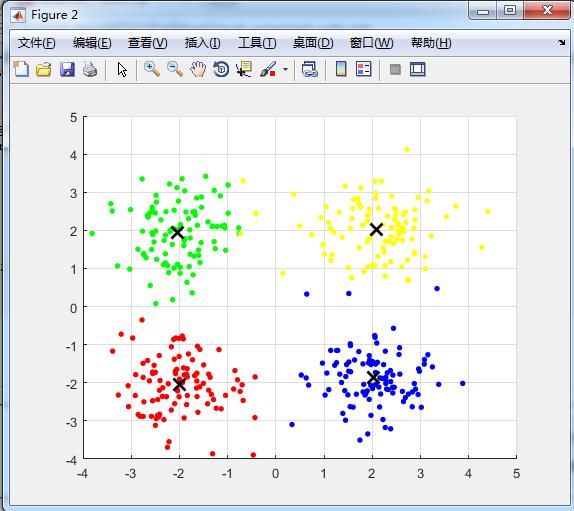
% 显示聚类后的结果
figure();
hold on;
for i=1:m
if idx(i, 3) == 1
plot(idx(i, 1), idx(i, 2), 'r.', 'MarkerSize', 12);
elseif idx(i, 3) == 2
plot(idx(i, 1), idx(i, 2), 'b.', 'MarkerSize', 12);
elseif idx(i, 3) == 3
plot(idx(i, 1), idx(i, 2), 'g.', 'MarkerSize', 12);
else
plot(idx(i, 1), idx(i, 2), 'y.', 'MarkerSize', 12);
end
end
grid on;
% 绘出聚类中心点,kx表示是交叉符
plot(ctr(:,1), ctr(:,2), 'kx', 'MarkerSize', 12, 'LineWidth', 2);
k_means.m
function [ idx, ctr ] = k_means( data, k, iterations )
%{
函数功能:
对数据实现k-means聚类
参数说明:
data:待聚类的数据,没有类别信息
k:期望聚类的类别数目
iterations:期望的算法的迭代次数(可不给)
算法停止的两个条件满足一个即可:达到预定迭代次数,聚类的质心不再改变或者改变很小。
函数返回:
idx:数据及其类别标号
ctr:存储k个聚类中的位置
%}
% m表示数据的规模,n表示数据的维度
[m, n] = size(data);
if k > m
disp('你需要聚类的数目已经大于数据的数目,无法聚类!');
return;
end
idx = zeros(m, 1);
ctr = zeros(k, n);
% nargin是用来判断输入变量个数的函数,这样就可以针对不同的情况执行不同的功能。
if nargin == 2
iterations = 0;
end
% 保存上一次的聚类中心
u = zeros(k, n);
% 保存更新后的聚类中心
c = zeros(k, n);
% 选定初始质心
t = 1;
for i=1:k
% 初始质心的选取方式为:从第一个数据开始,每隔m/k间隔选取一个数据点,直至得到k个类别中心
u(i, :) = data(t, :);
t = t + m/k;
end
iteration = 1;
while true
% 计算每个数据点到类别中心的距离,把数据点归入到与之最近的类别中
for i=1:m
% dis保存每个数据点到k个类别中心的距离
dis = zeros(k, 1);
for j=1:k
% 这里的数据可以是任意维度的,距离度量使用欧式距离
sum_dis = 0;
for t=1:n
sum_dis = sum_dis + (u(j, t) - data(i, t))^2;
end
dis(j) = sqrt(sum_dis);
end
% 找出数据点与k个类别中心中,距离最小的一个,该数据点归入到这一类中
[~, index] = sort(dis);
idx(i, 1:2) = data(i, :);
idx(i, 3) = index(1);
end
% 每一次聚类之后应该重新计算类别中心
for i=1:k
total_dis = zeros(1, n);
num_i = 0;
for j=1:m
if idx(j, 3) == i
for t=1:n
total_dis(1, t) = total_dis(1, t) + data(j, t);
end
num_i = num_i + 1;
end
end
c(i, :) = total_dis(1, :)/num_i;
end
% 算法结束
% 给定了迭代次数并且已经迭代了iterations次,退出算法
if iterations ~= 0 && iteration == iterations
ctr = c;
break;
elseif iterations == 0 && norm(c-u) < 0.01
ctr = c;
break;
end
iteration = iteration + 1; u = c;
end
end
仿真结果:
MATLAB实现K-means算法相关教程















 1762
1762











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









