






51Testing软件测试网&X?3N:z?j3] @L
本篇也可以叫做”建立索引时那一列应该放到最前面”。51Testing软件测试网/{-x4y'o5wq51Testing软件测试网u:w*tSy3^-oP
通常对于索引列的选择的通常准则都是把最高选择率(译者注:所谓选择率指的是在where子句中作为选择条件使用次数的比例来说的)的列放在最前面,我
接下来并不是要说这个准则不对,因为这个准则本身是正确的。但通常在给出这个准则的同时并没有同时给出为什么要把最高选择率的列作为索引列以及索引列的顺
序。51Testing软件测试网P.DPm)w
1bvE_z)S t`0综上原因,这很有可能导致对索引列选择的误解。比如,在极端情况下,某个人风闻了上述建议后,把所有非聚集索引的的索引键都设置成聚集索引的键(因为这列有很高的选择率),然后开始纠结为什么的性能开始惨不忍睹。51Testing软件测试网)[$e(Lpvm8P51Testing软件测试网6b d^ZY-Wx'y/l
出现上面那种极端情况是因为Server为每一个索引存储统计信息,但这个统计信息仅仅记录索引索引第一列的统计分布,这意味着索引仅仅知道第一列的数据分布,如果第一列不作为谓词使用,可能这个索引依然会被使用,但这并不是全部。^l`$[Y^*z_051Testing软件测试网:m3Kyk*{L Ca
除了统计分布图之外,SQL Server还为索引列的所有子集存储密度。对于3列作为组合索引键,SQL
Server就会存储第一列的密度,第一列和第二列的组合密度以及整个三列的组合密度。密度这个词表示列中所存的数据所不同的概率,公式为1/唯一值。每
个索引上的这个值都可以通过使用DBCC Show_Statistics加上DENSITY_VECTOR选项进行查看。ax
z)Q3}"ViZ6pu0
,a!_M
DdSS#aO0这也同时意味着,虽然SQL Server知道了第一列的数据分布,也同时知道索引列中其它键组合包含数据的平均值。#L$YHMv%q0
iyC8Ql#C0那么,对于索引列的先后顺序该怎么做呢?要把最高选择率的列放在第一个,剩下的列先后顺序就无所谓了。51Testing软件测试网)YKH.K3PHcm51Testing软件测试网d?'^G_INT@HJ
下面通过下表来看这究竟是什么意思。(tc5dy(h/V_0CREATE TABLE ConsideringIndexOrder (
Y,W(f;\H0ID INT IDENTITY,
m:UWuJ0SomeString VARCHAR (100),
xe/[)^Z,W@AUd0SomeDate DATETIME DEFAULT GETDATE()
5V v%w4e/`v OX0);
!J&w6@j;qx9G0假设上面的表有10000行,没有聚集索引所以是基于堆存储的,然后SomeString列包含100个不同的值,SomeDate列包含5000个不同的值,而ID列是自增,所以唯一。a#XJuK i,Dqa)k0
g jB1m0m5ge{m0建立一个非聚集索引包含上述散列,顺序为ID,SomeDate,SomeString.-SQ1z ]e:v"_-iA051Testing软件测试网ZV!?)t5kX m)s/?
上面建立的索引只能在谓词是如下时被使用:51Testing软件测试网,V1q&Gt
s q… WHERE ID = @ID AND SomeDate = @dt AND SomeString = @str51Testing软件测试网VI]eVt1OM
… WHERE ID = @ID AND SomeDate = @dt51Testing软件测试网1ElQ2~@r*R
… WHERE ID = @ID51Testing软件测试网B qK6k}j7r1A b
换句话说,这三列的子集只有按从左到右的顺序包含在谓词中才能被where和join使用。51Testing软件测试网#YOl/s+JY0\"|W0{,[51Testing软件测试网\,}X,PhQa"DB5H
如果你仅仅在where子句之后使用SomeDate列作为过滤条件,则不能使用索引进行查找。这就像是你想通过电话本按照人的名字而不是姓查找电话号码一样,想找到这个人是不能使用目录的,而只能翻遍整个电话版。51Testing软件测试网"MMX)Y9Zi;yL-_
\Pz+gpZ{(]a0j0此外,把具有最高选择率的列放在最左边,但这一列很少在谓词中使用。而大量的where过滤的是其它列的话,只能进行索引扫描,而扫描的代价非常高。51Testing软件测试网t:Q*C U#V9tk8lC
7c"W3}.o6f8Lb0由此得出结论如何选择放在索引第一列的列的标准并不唯一,而是基于数据库中使用最多的查询,如果这几列在where等子句之后使用等于号进行过滤的话,
那么毫无疑问,选择具有最高选择率的列放到第一位,这样SQL
Server就有更多的几率知道这个索引有用,如果不是这样的话,将在where等子句之后使用最多的列放到第一列,这样这个索引就可以适用于更多的查
询。51Testing软件测试网BI/Z0N)L51Testing软件测试网(A&u*D^O$Z
下面基于文章前面创建的表来做一些查询。51Testing软件测试网m"mR-ty:g2op-T51Testing软件测试网1x!R |Y{qe6i2F+y
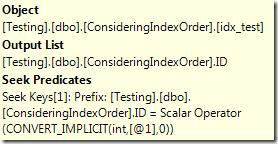
场景1:用ID作为谓词使用等于号进行过滤L3Q+MH:F0
\m&\'~
L,@;`h/J&\0这是最简单的一个场景,因为这个情况直接匹配索引的第一列,索引仅仅使用查找方式找到数据。Nq.mZ+d*MHR0
 ND7iR(Iq0
ND7iR(Iq0
zqw:f'y)?q
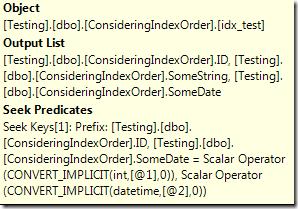
Z0场景2:用ID和SomeDate列作为谓词使用等于号进行过滤51Testing软件测试网] te&DnD
h q8I0Ee-E0这个场景同样非常简单,使用和非聚集索引顺序相同的子集作为过滤条件,因此也使用查找方式找到数据。;OcoC/?2K8?|0
 51Testing软件测试网7^.sTAyf}
51Testing软件测试网7^.sTAyf}
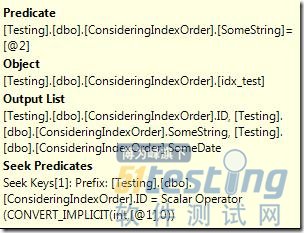
场景3:用ID和SomeString列作为谓词使用等于号进行过滤g
m1R0|5I+q5g0
这个场景就有点意思了。只能使用部分使用ID作为索引查找条件,因为SomeString列并不是索引的第二列。这
个索引的第二列是SomeDate但查询没有按照SomeDate进行过滤。因此这个查询首先使用ID进行过滤,然后过滤后的列进行字符串比较来找到匹配
的行。虽然这个操作是通过查找实现,但SQL Server仅仅使用查找找到ID,然后再将过滤后的行进行字符串比较。51Testing软件测试网9i|"s-TZ&L
 *EsL4B3^_-B0
*EsL4B3^_-B0
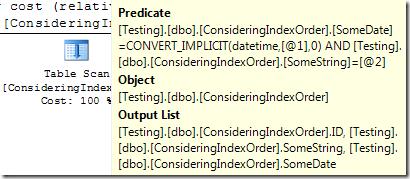
场景4:用SomeDate和SomeString列作为谓词使用等于号进行过滤51Testing软件测试网a;MV.eu:HH5{2^
在这个场景中,SQL Server就不能使用查找了。索引的第一列并不包含在这个查询的谓词之内。只能通过扫描来满足这个查询。实际上,SQL Server需要将表中这两列的每一行都和给定值进行比较来找到所需的行。{)rU/O1\0
 51Testing软件测试网Me ?)rv/~3A:R
51Testing软件测试网Me ?)rv/~3A:R
我觉得上述知识已经基本涵盖了有关索引的等式谓词。或许我这篇文章让你更迷惑了。但是至少我希望你更好的了解索引以及等号匹配。rY2br0kF0














 287
287











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









