







 本文介绍了如何使用Python3爬取网易云音乐中周杰伦的所有专辑、歌曲及评论。通过分析网页、抓包工具,利用requests、re、lxml等模块实现数据抓取。详细讲解了获取专辑信息、歌曲信息的过程,以及数据的清洗与可视化,包括歌词情感分析和词云图的生成。文章适合Python初学者,旨在帮助读者理解网络爬虫的基本原理和实践操作。
本文介绍了如何使用Python3爬取网易云音乐中周杰伦的所有专辑、歌曲及评论。通过分析网页、抓包工具,利用requests、re、lxml等模块实现数据抓取。详细讲解了获取专辑信息、歌曲信息的过程,以及数据的清洗与可视化,包括歌词情感分析和词云图的生成。文章适合Python初学者,旨在帮助读者理解网络爬虫的基本原理和实践操作。

这篇文章适合于python纯小白,因为本人也是python刚刚入门,里面可能很多语句是冗长的,甚至可能有一些尚未发现的BUG,这个伴随着我们继续学习来慢慢消解吧。接下来 我把里面会用到的东西在这里做一个简单总结吧:本文用到了两门解释性编程语言python3 + bash(shell),为什么用shell,我会在后面具体分析。用到的模块requests,re,os,jieba,glob,json,lxml,pyecharts,heapq,collections.看到这么多模块,大家一定很头痛,其实最开始我也没想到会用到这么多。不过随着程序的进行,这些模块自然的就出现在程序里,初学者对每一个模块没必要去特别了解。但是用法需要掌握。 话不多说,接下来就进入我们的正题吧。
一.找到需要爬取的内容,分析网页,抓包查看交互内容
首先我们先进入到我们需要抓取的内容的地址。http://music.163.com/# 这是网易云音乐的首页,我们的目的是抓取周杰伦的所有歌曲,歌词,已经评论,那我们在搜索处输入周杰伦
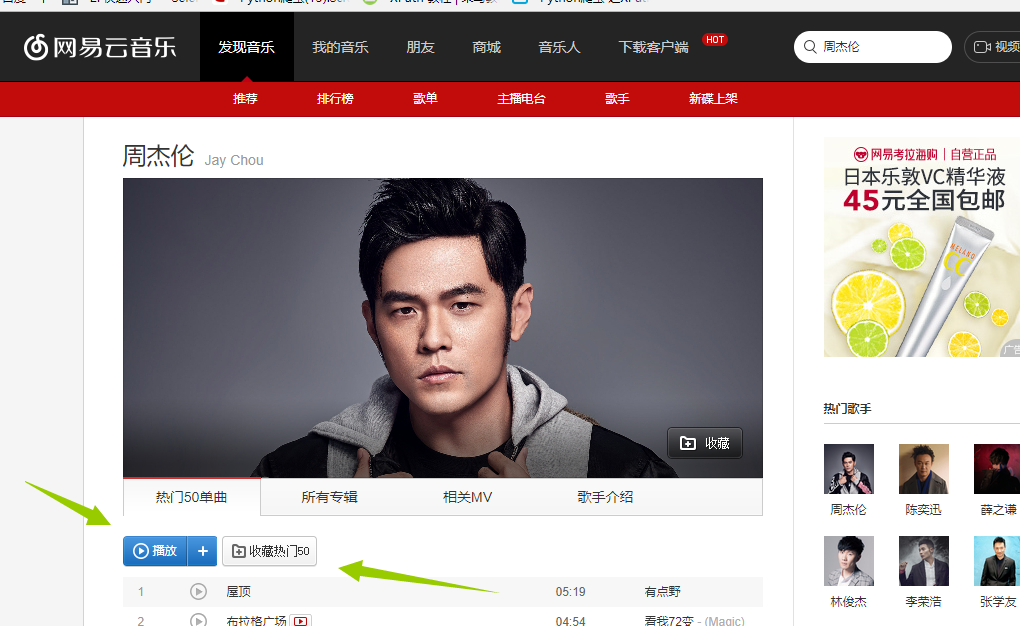 得到这张图,我们发现这里面只有最多50首歌(很多人分析网易云的歌曲就只选取TOP50),我们想要的是全部,所以这个URL不符合要求,我们继续寻找其他的URL地址。我在这里花了不少时间,最后找到了一个间接的方法,首先抓取周杰伦的全部专辑信息,然后通过专辑信息再去寻找全部歌曲(目前在网易云上我还没发现什么方法可以直接获取全部歌曲名字)。好了确定好了方针,我们第一步抓取所有专辑 进入http://music.163.com/#/artist/album?id=6452如下图所示!
得到这张图,我们发现这里面只有最多50首歌(很多人分析网易云的歌曲就只选取TOP50),我们想要的是全部,所以这个URL不符合要求,我们继续寻找其他的URL地址。我在这里花了不少时间,最后找到了一个间接的方法,首先抓取周杰伦的全部专辑信息,然后通过专辑信息再去寻找全部歌曲(目前在网易云上我还没发现什么方法可以直接获取全部歌曲名字)。好了确定好了方针,我们第一步抓取所有专辑 进入http://music.163.com/#/artist/album?id=6452如下图所示!
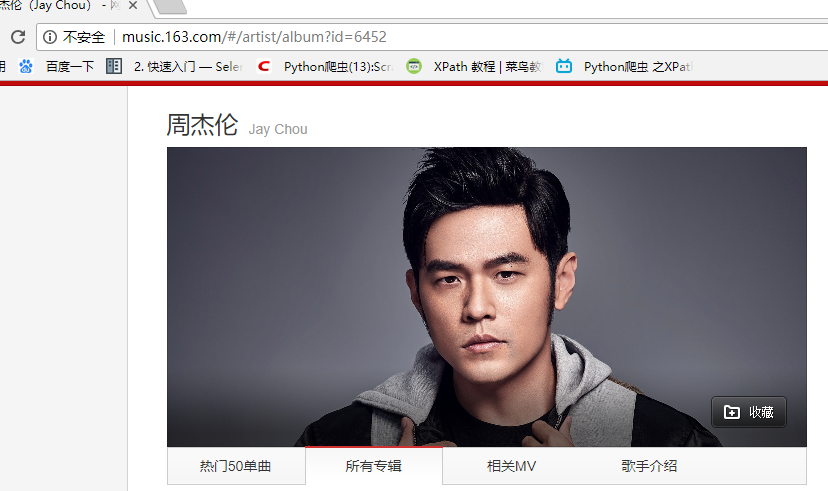 在这里面我们可以看到周杰伦所有专辑信息点击下一页 观察url发现变成了 http://music.163.com/#/artist/album?id=6452&limit=12&offset=12 这样!!!所以有点html基础的人都知道这里的limit=12是每页显示专辑的数量。OK,接下来我们就来获取专辑吧!我们在页面输入http://music.163.com/#/artist/album?id=6452&limit=100&offset=12(改成100 避免多次抓取,一次抓去完),在谷歌的抓包工具(F12)里面查看交互信息发现如下:
在这里面我们可以看到周杰伦所有专辑信息点击下一页 观察url发现变成了 http://music.163.com/#/artist/album?id=6452&limit=12&offset=12 这样!!!所以有点html基础的人都知道这里的limit=12是每页显示专辑的数量。OK,接下来我们就来获取专辑吧!我们在页面输入http://music.163.com/#/artist/album?id=6452&limit=100&offset=12(改成100 避免多次抓取,一次抓去完),在谷歌的抓包工具(F12)里面查看交互信息发现如下:
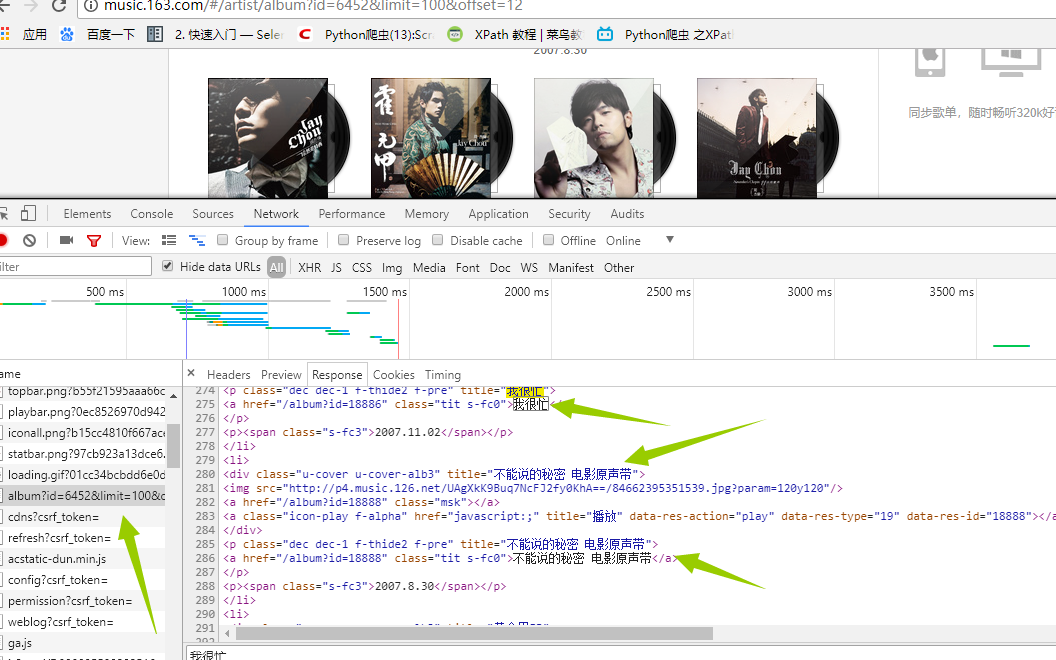 是的你没看错,这就是我们想要的信息,那事情就变得简单的,我们没必要用复杂的工具比如(selenium)去加载整个页面,(事实上,如果还没想到抓取歌曲的方法,我估计就得用它了),我们再看header里面有什么
是的你没看错,这就是我们想要的信息,那事情就变得简单的,我们没必要用复杂的工具比如(selenium)去加载整个页面,(事实上,如果还没想到抓取歌曲的方法,我估计就得用它了),我们再看header里面有什么
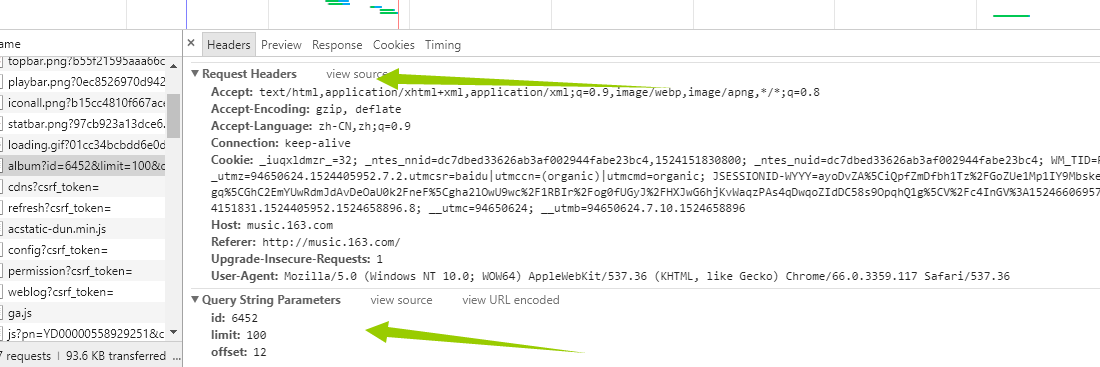 这里面的string我们不用管了,因为它已经在我们的url里面了,我们只需要看request headers 这个就是我们给服务器发送的东西,发送之后,服务器返回给我们的就是network里面的信息。好,接下来我们伪造浏览器发送请求。具体代码如下:
这里面的string我们不用管了,因为它已经在我们的url里面了,我们只需要看request headers 这个就是我们给服务器发送的东西,发送之后,服务器返回给我们的就是network里面的信息。好,接下来我们伪造浏览器发送请求。具体代码如下:
defGetAlbum(self):
urls="http://music.163.com/artist/album?id=6452&limit=100&offset=0"headers={'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8','Accept-Encoding':'gzip, deflate, br','Accept-Language':'zh-CN,zh;q=0.9','Connection':'keep-alive','Cookie':'_iuqxldmzr_=32; _ntes_nnid=dc7dbed33626ab3af002944fabe23bc4,1524151830800; _ntes_nuid=dc7dbed33626ab3af002944fabe23bc4; __utmc=94650624; __utmz=94650624.1524151831.1.1.utmcsr=(direct)|utmccn=(direct)|utmcmd=(none); __utma=94650624.1505452853.1524151831.1524151831.1524176140.2; WM_TID=RpKJQQ90pzUSYfuSWgFDY6QEK1Gb4Ulg; JSESSIONID-WYYY=ZBmSOShrk4UKH5K%5CVasEPuc0b%2Fq6m5eAE91jWCmD6UpdB2y4vbeazO%2FpQK%5CgiBW0MUDDWfB1EuNaV5c4wIJZ08hYQKDhpsHnDeMAgoz98dt%2B%2BFfhdiiNJw9Y9vRR5S4GU%2FziFp%2BliFX1QTJj%2BbaIGD3YxVzgumklAwJ0uBe%2FcGT6VeQW%3A1524179765762; __utmb=94650624.24.10.1524176140','Host':'music.163.com','Referer':'https://music.163.com/','Upgrade-Insecure-Requests':'1','User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'}
html= requests.get(urls,headers=headers)
html1=etree.HTML(html.text)
html_data=html1.xpath('//div[@class="u-cover u-cover-alb3"]')[0]
pattern= re.compile(r'
items=re.findall(pattern, html.text)
cal=0#首先删除这个文件,要不然每次都是追加
if(os.path.exists("专辑信息.txt")):
os.remove("专辑信息.txt")#删除文件避免每次都要重复写入
if (os.path.exists("专辑歌曲信息.txt")):
os.remove("专辑歌曲信息.txt")for i initems:
cal+=1
#这里需要注意i是有双引号的,所以需要注意转换下
p=i.replace('"','')#这里在匹配里面使用了字符串,注意下
pattern1=re.compile(r'%s'%(p))
id1=re.findall(pattern1,html.text)#print("专辑的名字是:%s!!专辑的ID是%s:"%(i,items1))
with open("专辑信息.txt",'a') as f:
f.write("专辑的名字是:%s!!专辑的ID是%s \n:"%(i,id1))
f.close()
self.GetLyric1(i,id1)#print("总数是%d"%(cal))
print("获取专辑以及专辑ID成功!!!!!")
这里面用到了xpath来找到对应标签里面数据,然后把数据放在文件里面。代码不重要,思想懂了就行(代码单独执行可行)
执行结果如下
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









