







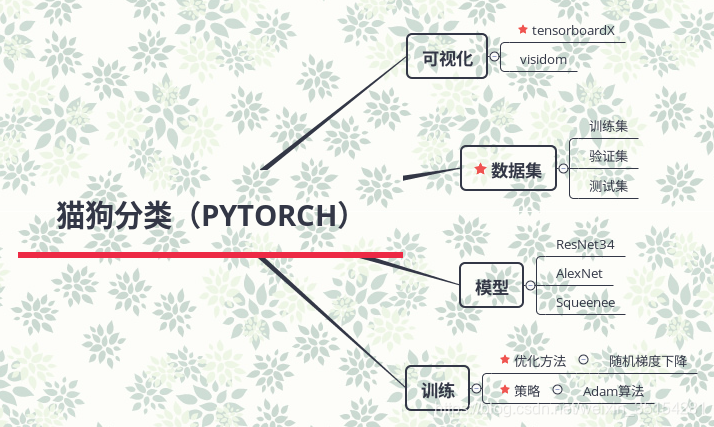
猫狗分类问题
0.参考
1.总体框架梳理
1.1 数据集
数据集为Kaggle中Cat&Dog数据集
具体如下:

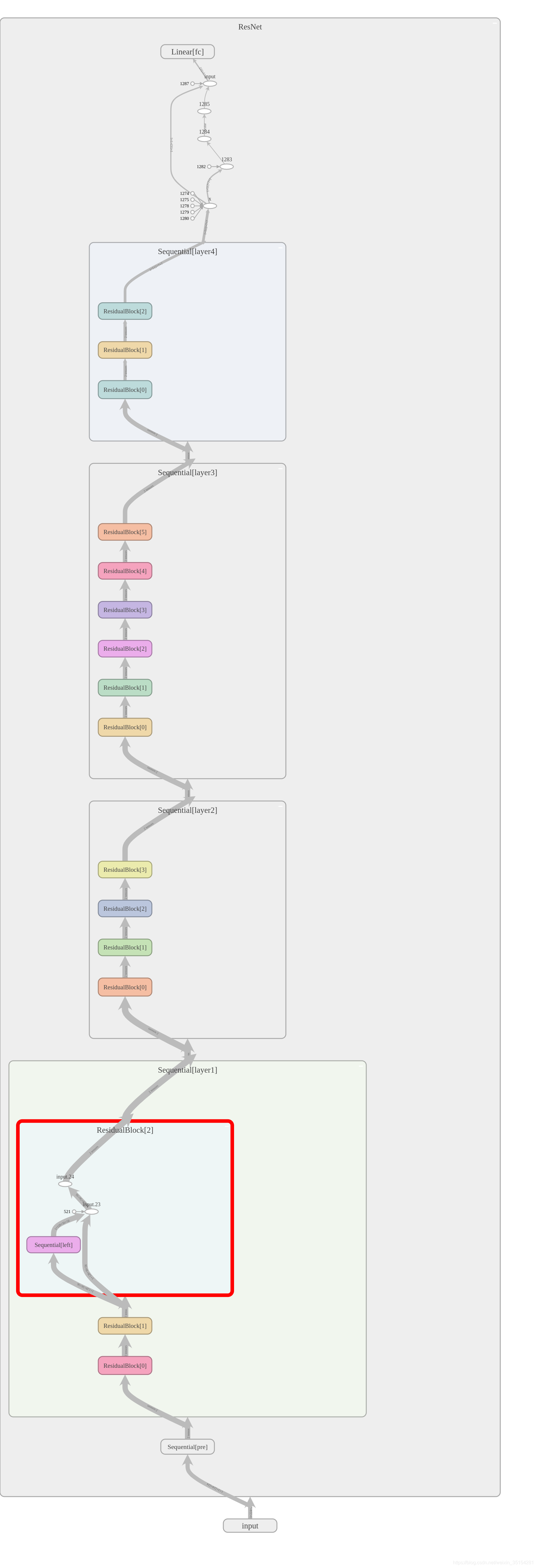
1.2 模型
ResNet34
问题:
(1)为什么网络的深度很重要?
答:因为CNN能够提取Low/mid/high-level的特征,网络的层数越多,意味着提取到的不同等级的特征越丰富。并且,越深的网络提取的特征越抽象,越具有语义信息。
(2)为什么不能简单的增加网络的层数?
答:梯度消失和弥散
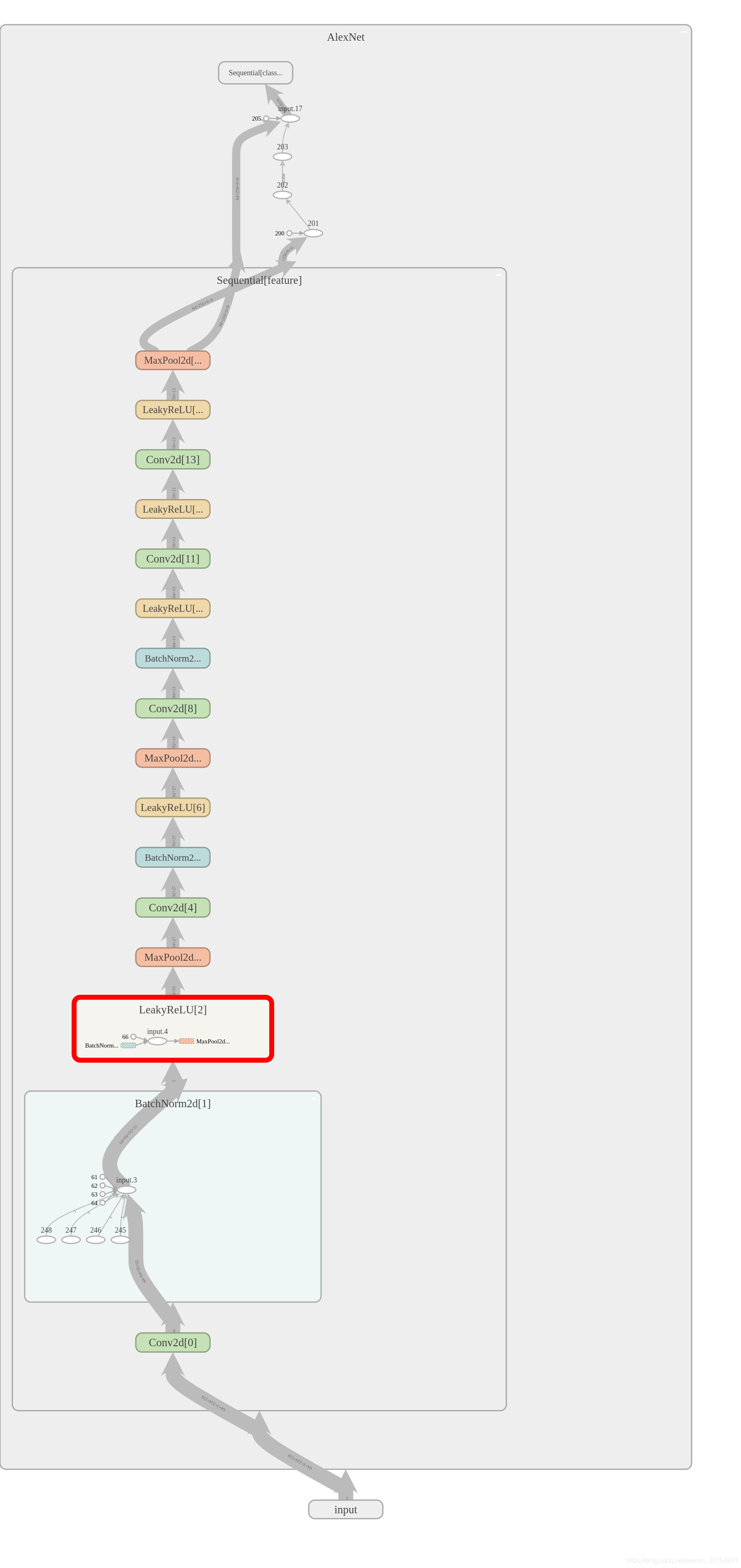
AlexNet变体:
说明:AlexNet变体模型在原有的AlexNet模型的基础上,增加了BN层,并且消除了全连接层中的Dropout层,因为BN会带有一点正则化的效果,在使用激活函数时替换Relu为Leaky_Relu.
模型图:
1.3 训练模型
def train():
# 1.选择合适的model
model = getattr(models, opt.model)()
model.cuda()
# 2.得到批量化的数据
train_data = DogCat(root=opt.train_root, train=True)
val_data = DogCat(root=opt.train_root, train=False)
train_dataloader = DataLoader(train_data, batch_size=opt.batch_size, shuffle=True, num_workers=opt.num_works)
val_dataloader = DataLoader(val_data, batch_size=opt.batch_size, shuffle=False, num_workers=opt.num_works)
# 3.设置参数
loss_meter = meter.AverageValueMeter() # 计算平均值和标准差
confuse_metrix = meter.ConfusionMeter(2) # 计算混肴矩阵
criterion = nn.CrossEntropyLoss()
optimizer = t.optim.SGD(model.parameters(), lr=opt.lr, momentum=0.9)
writer = SummaryWriter()
for epoch in range(opt.epoch_nums): # 设置迭代次数
# 4 执行批量化的数据
print("Epoch :", epoch)
loss_meter.reset()
confuse_metrix.reset()
for ii, (data, label) in tqdm(enumerate(train_dataloader)):
input1 = data.to(opt.device)
target = label.to(opt.device)
optimizer.zero_grad()
score = model(input1)
loss = criterion(score, target)
loss.backward()
optimizer.step()
# 记录数据
confuse_metrix.add(score.detach(), target.detach())
loss_meter.add(loss.item())
if (ii + 1) % 20 == 0:
print("loss_meter", loss_meter.value()[0])
writer.add_scalar("Loss", loss_meter.value()[0])
# 改变学习策略,逐渐取向最优解
if epoch == 50:
opt.lr = 0.001
# 5. 保存网络数据
writer.close()
t.save(model.state_dict(), opt.model_path)
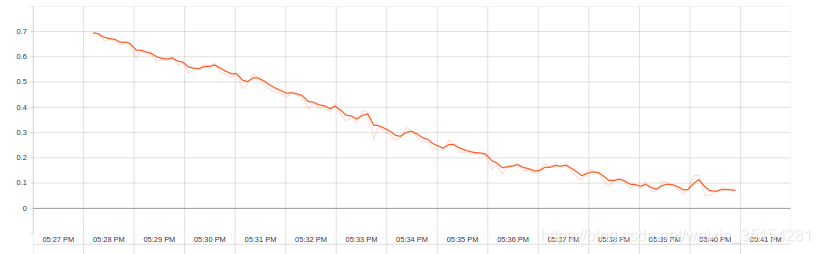
1.4 可视化
此时的training loss处于下降的趋势,说明此时的网络正在学习参数,由于此次迭代只限制在60次,训练的训练集数据集为2000张照片,可以从图中看出此时的还未达到收敛点,但此时应该使用测试集来判断此时是否过拟合。
Training loss:
1.5评估
测试1:


测试2:


2.出现的问题
-
AssertionError: number of predictions does not match size of confusion matrix
解决方法:confusion matrix的种类树木与评测参数不一致
-
loss不下降,一直维持在0.69左右
3.知识点
3.1Python用法
-
python中文件打包
-
python eval()函数
-
ipdb(debug)包的使用
-
time.strtime
time.strftime()https://www.runoob.com/python/att-time-strftime.html
-
torchnet.meter的学习
import torchnet
tnt.Meter
Meters provide a standardized way to measure a range of different measures, which makes it easy to measure a wide range of properties of your models.
有三个基础的方法:
- add() which adds an observation to the meter.
- value() which returns the value of the meter, taking into account all observations.
- reset() which removes all previously added observations, resetting the meter.
tnt.AverageValueMeter(self)
The tnt.AverageValueMeter measures and returns the average value and the standard deviation of any collection of numbers that are added to it. It is useful, for instance, to measure the average loss over a collection of examples.
tnt.AUCMeter(self)
The tnt.AUCMeter measures the area under the receiver-operating characteristic (ROC) curve for binary classification problems. The area under the curve (AUC) can be interpreted as the probability that, given a randomly selected positive example and a randomly selected negative example, the positive example is assigned a higher score by the classification model than the negative example.
tnt.ConfusionMeter(self, k[, normalized])
The tnt.ConfusionMeter constructs a confusion matrix for a multi-class classification problems.
import torchnet.meter as meter m = meter.AverageValueMeter() for i in range(10): m.add(i) print(m.value()[0]) m.reset()#重置数据 for i in range(10, 20): m.add(i) print(m.value())4.5
(14.5, 3.0276503540974917)import torch mtr = meter.ConfusionMeter(k=3) output = torch.Tensor([[.01, 0.01, 0.1], [10, 11, 10], [0.2, 0.2, .3]]) if hasattr(torch, "arange"): target = torch.arange(0, 3) else: target = torch.range(0, 2) print(target) print(output) mtr.add(output, target)tensor([0, 1, 2])
tensor([[1.0000e-02, 1.0000e-02, 1.0000e-01],
[1.0000e+01, 1.1000e+01, 1.0000e+01],
[2.0000e-01, 2.0000e-01, 3.0000e-01]])mtr.value() #生成一个onehat向量array([[0, 0, 1],
[0, 1, 0],
[0, 0, 1]], dtype=int32)meter.confusionmeter??














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









