






问题场景
最近在用httpClient做网络爬虫的时候,遇到了一个不大不小的问题,当使用HttpGet向指定网址发送请求后,接收到的Response无法正常解析,出现 口口??这样的乱码,编码也考虑到了中文编码,具体代码如下:
//处理逻辑
HttpResponse response = HttpUtils.doGet(baseUrl + title + postUrl, headers);
InputStream is = getInputStreamFromResponse(response);
responseText = Utils.getStringFromInputStream(in);
result = EncodeUtils.unicdoeToGB2312(responseText);
//上面使用到的函数
public static HttpResponse doGet(String url, Map headers) {
HttpClient client = createHttpClient();
HttpGet getMethod = new HttpGet(url);
HttpResponse response = null;
response = client.execute(getMethod);
return response;
}
public static String getStringFromStream(InputStream in) {
StringBuilder buffer = new StringBuilder();
BufferedReader reader = null;
reader = new BufferedReader(new InputStreamReader(in, "UTF-8"));
String line = null;
while ((line = reader.readLine()) != null) {
buffer.append(line + "\n");
}
reader.close();
return buffer.toString();
}
解析到的结果如下图所示,一团乱麻。
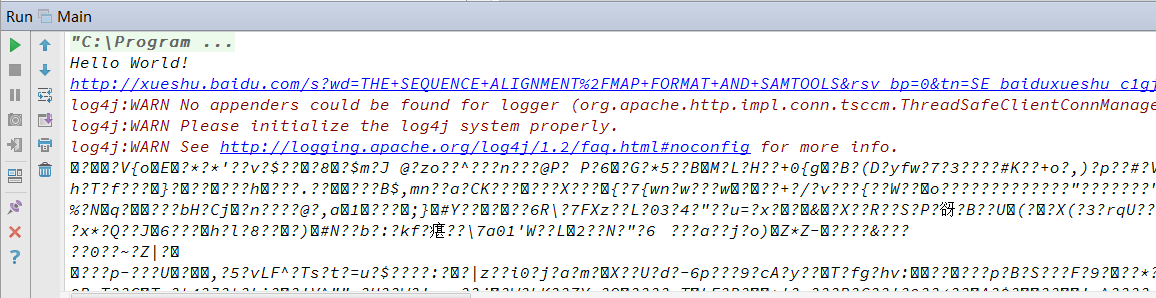
解决方案
上面的代码基本逻辑是没有问题的,也考虑到了中文的编码,但是却有一个很隐秘的陷阱在里面,一般的网站都先将网页压缩后再传回给浏览器,减少传输时间,如下图所示:
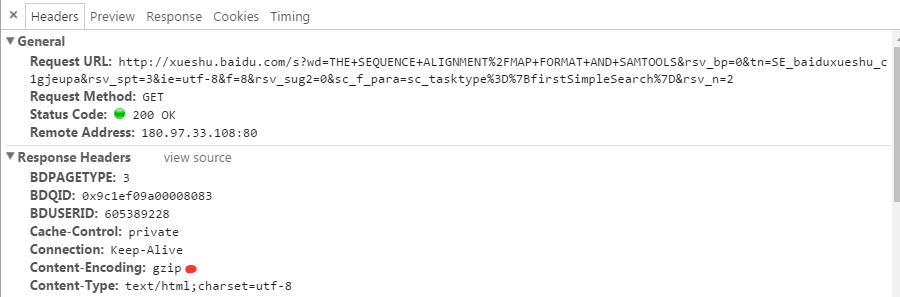
而上面的处理逻辑则没有考虑到Response的inputStream是经过压缩的,需要使用对应的数据流对象处理,图中使用的content-encoding是gzip格式,则需要使用GZIPInputStream对其进行处理,只需要对上文中的函数public static String getStringFromStream(InputStream in)改进即可,如下所示:
public static String getStringFromResponse(HttpResponse response) {
if (response == null) {
return null;
}
String responseText = "";
InputStream in = getInputStreamFromResponse(response);
Header[] headers = response.getHeaders("Content-Encoding");
for(Header h : headers){
if(h.getValue().indexOf("gzip") > -1){
//For GZip response
try{
GZIPInputStream gzin = new GZIPInputStream(is);
InputStreamReader isr = new InputStreamReader(gzin,"utf-8");
responseText = Utils.getStringFromInputStreamReader(isr);
}catch (IOException exception){
exception.printStackTrace();
}
break;
}
}
responseText = Utils.getStringFromStream(in);
return responseText;
}
最终得到的结果就是人能够看懂的了。

问题原因
在分析服务器返回response时,只注意到content-type是text/html,表明我们可以用文本解析的方式来获取response的内容,如果content-type是excel,则表明我们可以用excel软件来读取内容。content-type表明的是内容是以何种格式组织的。但是我却忽略了content-encoding这个字段,content-encoding字段表明的是服务器以何种方式来对传输的内容进行额外编码,例如压缩,如果content-encoding是gzip,则表明服务器是以Gzip格式压缩数据,而数据本身的格式可以是文本,也可以是视频等。两者需要区分对待。但是需要注意的是,有的服务器虽然返回的是gzip的content-encoding,而实际上却并没有对内容进行gzip编码,所以有可能会出现gzip解码失败。
(官方原文解释)
RFC 2616 for HTTP 1.1 specifies how web servers must indicate encoding transformations using the Content-Encoding header. Although on the surface, Content-Encoding (e.g., gzip, deflate, compress) and Content-Type(e.g., x-application/x-gzip) sound similar, they are, in fact, two distinct pieces of information. Whereas servers use Content-Type to specify the data type of the entity body, which can be useful for client applications that want to open the content with the appropriate application, Content-Encoding is used solely to specify any additional encoding done by the server before the content was transmitted to the client. Although the HTTP RFC outlines these rules pretty clearly, some web sites respond with “gzip” as the Content-Encoding even though the server has not gzipped the content.
Our testing has shown this problem to be limited to some sites that serve Unix/Linux style “tarball” files. Tarballs are gzip compressed archives files. By setting the Content-Encoding header to “gzip” on a tarball, the server is specifying that it has additionally gzipped the gzipped file. This, of course, is unlikely but not impossible or non-compliant.
Therein lies the problem. A server responding with content-encoding, such as “gzip,” is specifying the necessary mechanism that the client needs in order to decompress the content. If the server did not actually encode the content as specified, then the client’s decompression would fail.
参考
HTTP 1.1 协议官方文档














 6931
6931











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









