






1 基础
HTML解析:定位基础是xpath,了解下面的链接的基本知识。
在python中使用HTML解析等操作时,需要安装lxml包,在pycharm的terminal下:pip install lxml
最重要的两个函数是:
html = etree.HTML(response.text) 获取到响应的内容后,采用etree的HTML方法,返回DOM树型结构的根节点
ans = html.xpath('//div[@class = "billboard-bd"]//tr/td/a/text()') 采用etree的xpath方法,定位到我们需要的东西
2 例题
DOM Tree是嵌套树结构,形象的理解为下图:
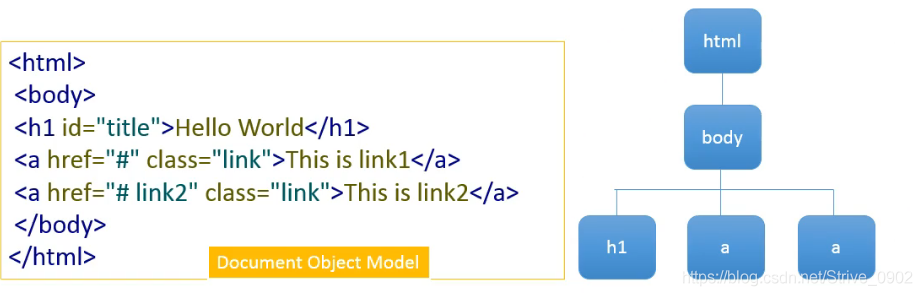
下面是构建HTML的DOM嵌套树形结构:
from lxml import etree
##构建HTML:header和body
###添加元素
root = etree.Element('html')
body = etree.Element('body')
root.append(body)
print(type(root))
print(root.tag)
###添加子元素
div1 = etree.SubElement(body,'div1')
div2 = etree.SubElement(body,'div2')
print(etree.tostring(root,pretty_print = True).decode())
运行结果为

3 爬虫(解析HTML)
目标是:用爬虫爬取豆瓣电影的一周口碑排行榜的电影名字。
首先:打开“https://movie.douban.com/”鼠标点击一周口碑榜下面的电影名字——右键查看。就可以看到该段对应的HTML源码


根据HTML的xpath定位语法,分别定位到order的文本1 ,2,3,4,5...和a下面的文本:电影的名字。xpath定位到的结果是列表。使用lxml里etree模块的最重要的两个函数:
html = etree.HTML(response.text) 获取到响应的内容后,采用etree的HTML方法,返回DOM树型结构的根节点
ans = html.xpath('//div[@class = "billboard-bd"]//tr/td/a/text()') 采用etree的xpath方法,定位到我们需要的东西
Python代码如下:
from urllib.parse import urlencode
import requests
from lxml import etree
url = "https://movie.douban.com/"
ua = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/42.0.2311.135 Safari/537.36 Edge/12.10240"
with requests.request('GET',url,headers = {'User-agent':ua}) as res:
content = res.text #获取HTML的内容
html = etree.HTML(content) #分析HTML,返回DOM根节点
#path = //div[@class='billboard-bd']//td//a/text()
orders = html.xpath("//div[@class='billboard-bd']//tr/td[@class='order']/text()")
titles = html.xpath( "//div[@class='billboard-bd']//td//a/text()") #使用xpath函数,返回文本列表
print(orders)
print(titles)
ans = dict(zip(orders,titles)) #豆瓣电影之本周排行榜
for k,v in ans.items():
print(k,v)
实验结果如下:
D:Program_myAnaconda3python.exe F:/Python_workspace/spyder_study/HTML_Douban_xml.py
['1', '2', '3', '4', '5', '6', '7', '8', '9', '10']
['神奇动物:格林德沃之罪', '重金属囧途', '孤狼之血', '一个明星的诞生', '法外之王', '滑板少年', '风的另一边', '狼屋', '麦昆', '我的冤家是条狗']
1 神奇动物:格林德沃之罪
2 重金属囧途
3 孤狼之血
4 一个明星的诞生
5 法外之王
6 滑板少年
7 风的另一边
8 狼屋
9 麦昆
10 我的冤家是条狗
Process finished with exit code 0
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









