







前几天,刷数据分析的面试题,期间遇到几个SQL题,其中有一道需要用到Oracle中的nvl函数,还有关于数据类型转换,时间格式转换的函数等等;
“虽说有印象,但确实不会写了!可要是看一眼,马上就能做出来!”我就是这种感觉。
所以,就有了接下来这篇文章:复盘之前写过的SQL函数!
只需要看这篇文章,理解这些函数就可以了,不必要自己敲代码,因为我已经将运行结果截图了,理解为上!
重要提示:大家用电脑看效果比较好,手机屏幕太小,sql看不完整!
关于数据库介绍的,请点求知鸟:分析视角之主流数据库
关于mysql的,请点求知鸟:数据分析:你需要知道的mysql相关知识
业务上常用的SQL模型,请点求知鸟:数据分析之SQL:常用模型
SQL实战项目,请点求知鸟:实战:SQL分析+Excel可视化
Oracle篇
1、Null是没有,不参与计算。可以将null转换为0参与计算;
nvl(字段,0):字段非空显示本身,null补为0! nvl(字段,1,0):字段非空替换为1,null补为0! 注意:''是空字符串,空也是字符!
2、链接符||与“q”
select first_name||‘’ from employees;--right
select first_name||q'[]' from employees;--right 与上等价
select first_nameq'[]' from employees;--wrong
select first_name||"abc" from employees;--wrong
链接符q需要在||后使用;除了起别名,会用到“”;在其他任何地方,都使用‘’
3、order by双层排序
select * from employees order by department_id asc , salary desc;先对department_id按照升序排序,如果department_id相等则再对排序结果按照salary降序排列 。
select * from employees order by salary;
select * from employees order by 8;
select first_name ,last_name from employees order by salary;
select first_name ,last_name from employees order by 8;
1,2句:此时二者都是对全表结果排序(*),所以效果相同
3,4句:第4句查询结果只有两个字段,8就是无效的。
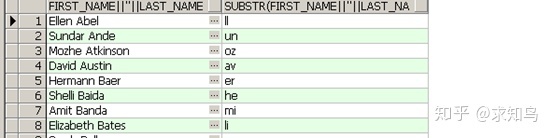
4、substr函数
select first_name ||‘ .'||last_name ,substr(first_name ||' '||last_name,2,2 ) from employees;
SUBSTR(列|字符串,开始点[,⻓度]):字符串|数字截取
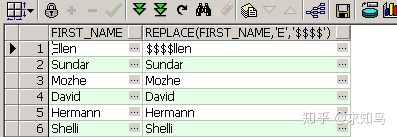
5、replace函数
select first_name ,replace(first_name,'E','$$$$') from employees;
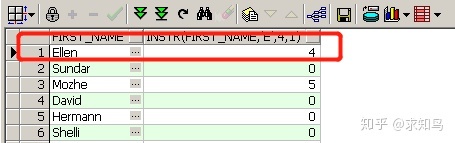
6、Instr
select first_name ,instr(first_name,'e',4,1) from employees;
Instr 从第几个开始,第几次出现在整个字符串的位置;
7、round
select round(59.866,2) from dual;--59.87
select round(59.866,-1) from dual;--60
round :四舍五入只能针对数字
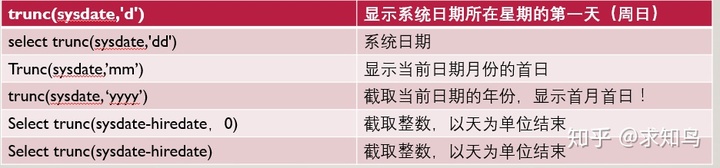
8、trunc
select trunc(59.866,2) from dual;--59.86
select trunc(59.866,-1) from dual;--50
trunc:可以对数字或日期起作用,不能对字符串起作用!

9、to_number
select to_number('$12332123.12','$99999999.00') from dual;--right 12332123.12 前后格式一致,位数一致;前是数字,后接数字类型
select to_number('$12332123.12','99999999.00') from dual;--wrong qianhou format type 前有 $,后没有,就报错!
10、To_char &to_number to_char &to_date 字符,数字,时间格式互转!
select to_char(to_number('$12332123.12','$99999999.00'),'$99999999.00') from dual;-- $12332123.12
select to_date('2018-01-01','yyyy-mm-dd')+3 from employees;
select to_char(to_date('2018-01-01','yyyy-mm-dd'),'2018-01-01') from employees;--wrong '2018-01-01'不是日期类型!
select to_char(to_date('2018-01-01','yyyy-mm-dd'),'yyyy-mm-dd') from employees;
select to_char(to_date('2018-01-01','yyyy-mm-dd'),'yyyy-mm-dd')+3 from employees;--wrong
小练习:求一年多少天&简单嵌套
Select to_char((add_months(trunc(sysdate,'yyyy'),12))-1),'ddd') from dual;
分解步骤:trunc(sysdate,'yyyy')—显示结果2018-01-01
add_months(trunc(sysdate,'yyyy'),12)—显示结果2019-01-01
(add_months(trunc(sysdate,'yyyy'),12))-1—显示结果2018-12-31
to_char((add_months(trunc(sysdate,'yyyy'),12))-1),'ddd')—ddd表示一年的第几天
扩展为:求一个员工工作了多少年,零多少月,零多少天
这个题比较绕,即便你能抠出来,也不优雅!
下面是比较优雅的写法:
select trunc( months_between(sysdate,hire_date)/12) , trunc(mod( months_between(sysdate,hire_date),12 ) ) ,trunc(sysdate-add_months(hire_date,months_between(sysdate,hire_date))) from employees;
利用了add_months的特征:忽略小数
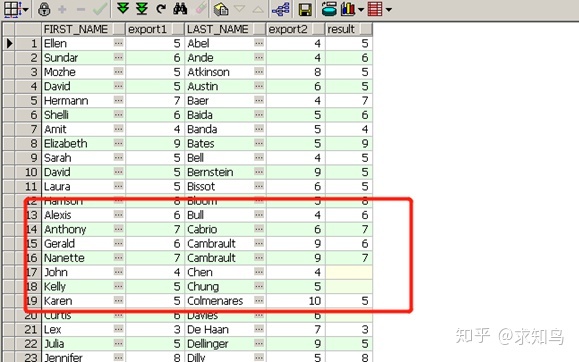
11、nullif
select first_name ,length(first_name) "export1" ,
last_name ,length(last_name) "export2" ,
nullif (length(first_name)❶,length(last_name)❷) "result"
from employees;
nullif 若❶与❷相等,则返回空;若不等,则返回❶
12、关于求平均工资中的最高工资,并显示部门号的讨论
select deptno,avg(sal) from emp group by deptno having avg(sal)=(select max(avg(sal)) from emp group by deptno);--right
select * from (select deptno,avg(sal) sal from emp group by deptno order by sal DESC) where rownum = 1;--right
第一句用的是having
第二句用的是子查询+伪列!
伪列:rownum,rowid
13、分析函数:sum(字段)over()
select empno,sal,sum(sal)over(order by sal) from emp;
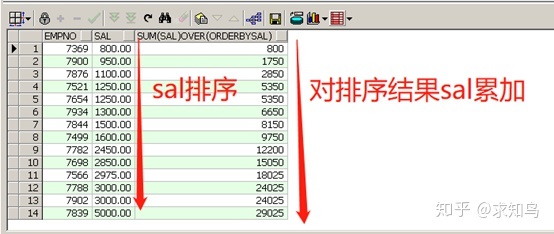
先执行over后的排序,再对排序结果执行累加!
select empno,ename,sal,sum(sal) over( partition by deptno order by sal) ,deptno from emp;
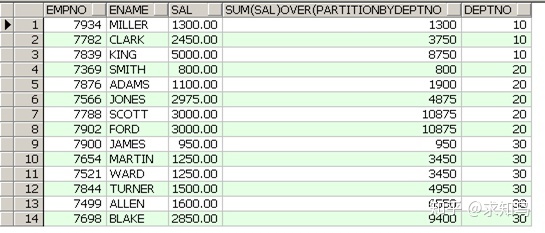
先执行over后的pytition by分组,然后对分组执行求和!
partition by和group by的区别:group by 后的分组键限制select 后的的字段!而partition by不会!Group by 有分组去重复的作用;partition by分组求和不去重
14、Row_number()over():会排名不会并列
select empno,deptno,sal,row_number() over(partition by deptno order by sal desc) from emp;
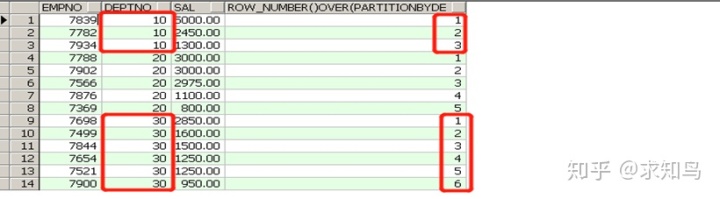
只要上图清清楚楚,实在没有解释的必要!
练习:取每个部门员工sal第一的人
select empno,deptno,sal from (select empno,deptno,sal ,row_number()over(partition by deptno order by sal desc) "addup" from emp) where addup=1;
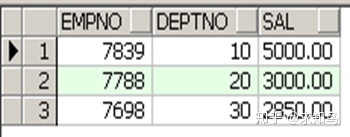
取每个部门员工第一,我们最先想到的可能是对deptno部门号分组,然后取第一!
可这个需求还需要提供empno员工编号,以及sal工资的信息,所以就考虑用row_number()over(partition by deptno order by sal desc)这个函数!
此外,相似的排序函数还有:
row_number()over():不显示并列!出现:1,2,3,4,5的排次
rank()over():区别是,显示并列,并且占名次!也就是会出现:1,1,3,4,5的排次
dense_rank()over():显示并列,并列不占名次!也就是会出现:1,1,2,3,4的排次
15、高级分组rollup
Select department_id,job_id,sum(salary) from employees where department_id<60
Group by rollup(department_id,job_id);
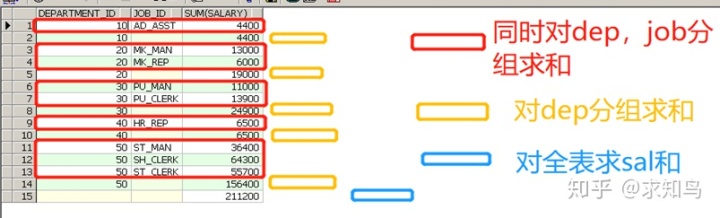
什么,看不懂?!这么清楚,你还看不懂?
rollup(a,b) 统计列包含:(a,b)、(a)、()
rollup(a,b,c) 统计列包含:(a,b,c)、(a,b)、(a)、()
roll up(deptno,job)= group by (deptno,job)+ group by (deptno)+ sum(sal)
这下看懂了没?要还不懂,我也没招了!
16、高级分组cube
select deptno,job ,sum(sal) from emp group by cube(deptno,job);

cube(a,b) 统计列包含:(a,b)、(a)、(b)、()
cube(a,b,c) 统计列包含:(a,b,c)、(a,b)、(a,c)、(b,c)、(a)、(b)、(c)、()
cube(deptno,job)= group by (deptno,job)+ group by deptno
+ group by job+ sum(sal);
总结:rollup/cube都是跟着group by的后面,依旧要遵循group by的逻辑(select 字段要是连接键!);牛逼之处,排序范围更大了,更接地气了!
17、牛逼的函数grouping sets
•Grouping sets 是对group by 子句的进一步扩充
•使用Grouping sets在同一个查询中定义多个分组集
•Oracle中对grouping sets 子句指定的分组集进行分组后用union all 操作将各分组结果结合起来
•Grouping sets的优点:
•只进行一次分组即可
•不必书写复杂的union语句
•Grouping sets 中包含的分组越多性能越好
目前为止,至少已经学过1个oracle独有的函数nvl(,),至于row_number(),rank() over(order by 列名),grouping 和 grouping set函数,cube,rollup这些函数是Oracle特有的吗?我也不知道啊,小伙伴们要是知道,请在评论区留言哦!
与case when 类似功能的decode (Oracle独有)!以及对nvl的补充,nvl2(,,)
select deptno,job,sum(sal) from emp group by grouping sets(deptno,job);

select deptno,job,ename,avg(sal) from emp group by grouping sets ((deptno,job),(job,ename));
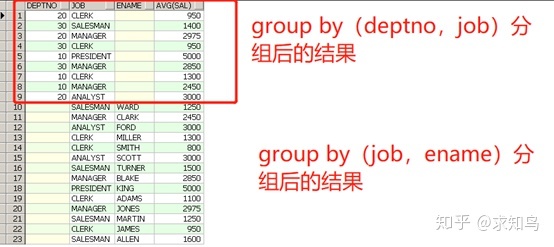
group by grouping sets ((deptno,job),(job,ename));
=group by (deptno,job) union all group by (job,ename)
再看另一种变形:
select deptno,job,mgr,ename,avg(sal) from
emp group by grouping sets (deptno,job),
grouping sets (mgr,ename);
与上题不同的是:此题grouping sets()又写了一遍!
那么此题分组的原则是:
(a+b)*(c+d)=ac+ad+bc+bd;最终以union all形式显示分配结果的四种情况
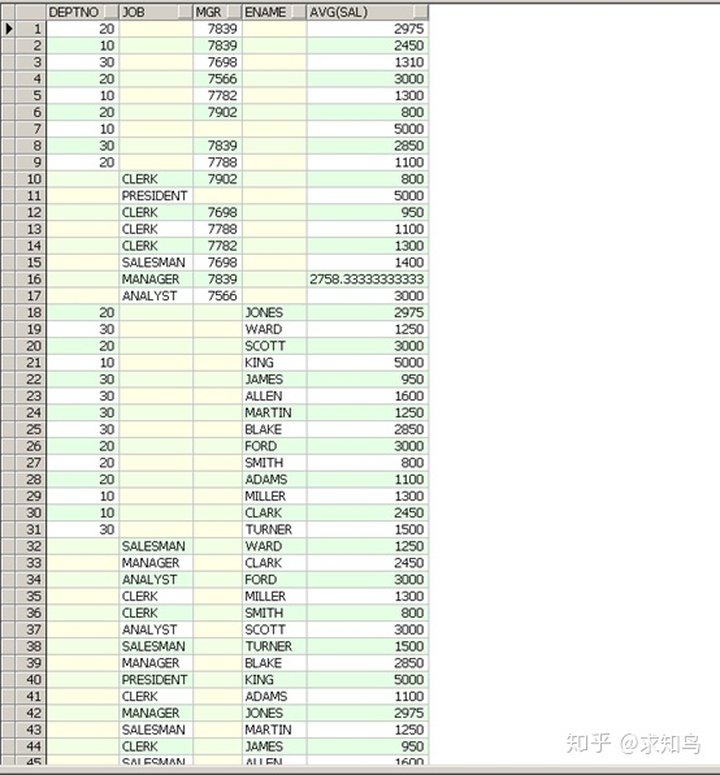
18,伪列rownum
rownum和rowid都是伪列,但是两者的根本是不同的,rownum是根据sql查询出的结果给每行分配一个逻辑编号,所以你的sql不同也就会导致最终rownum不同,但是rowid是物理结构上的,在每条记录insert到数据库中时,都会有一个唯一的物理记录 .
•我们要查找emp表格中第5到第10行的数据;
select rownum,e.* from emp e where rownum>5 and rownum<10 ---wrong
select * from (select rownum rn,e.* from emp e) where rn between 5 and 10--right
rownum要查找的范围必须包含1;因为rownum是从1开始的; 通常都是将rownum 起别名作为一个子查询!
同样的,我们要查找emp表格中倒数第5行到第8行的值
select * from (select rownum rn,e.* from emp e ) where rn between (select count(*)-7 from emp ) and (select count(*)-4 from emp ) ; --between 小 and 大
19,正则表达式
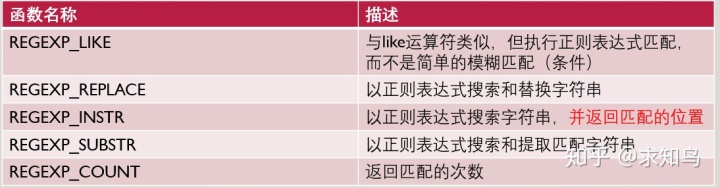
select first_name,last_name from employees where regexp_like (first_name,‘^Ste(v|ph)en$’);---^ 起始位置$结束位置 |或
select first_name from employees where regexp_like(first_name,‘^al(an|yss)a$’,‘i’);--不分大小写;
select first_name from employees where regexp_like(first_name,‘^al(.){2}a$’,‘i’);--任意字符出现2次
select first_name from employees where regexp_like(first_name,‘^al[^y]+a$’,‘i’);--[y]该位置就只能出现y;[^y]该位置不能是y
总结:
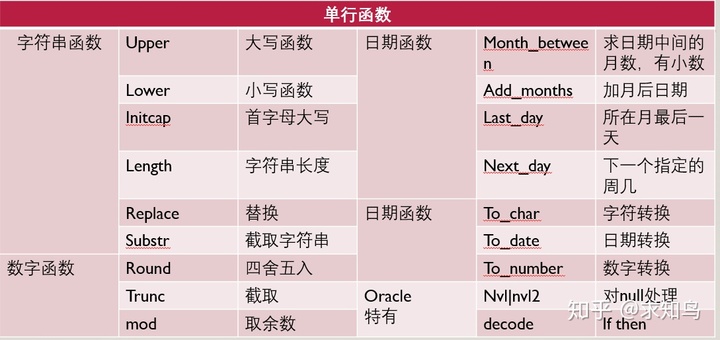
tips:
整理不易,我说这篇文档包含我5个月时间的集训精华,大家可能不信!但的确是集训内容之一,还有其它的东西都糅杂在我的专栏里面了
数据分析zhuanlan.zhihu.com
总之,花了我不少心血,点赞收藏大家看着办吧,就是要赞又咋滴,我不要,你能给吗?!哈哈














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









