





问题现象
客户的java日志中有如下异常信息:

问题的风险及影响
对正常的业务流程无影响,但是影响druid的merge sql功能(此功能会将sql语句中的字面量替换为绑定变量,然后将替换以后的sql视为同一个,然后用做执行性能统计)
问题影响的版本
与yashandb版本无关
问题发生原因
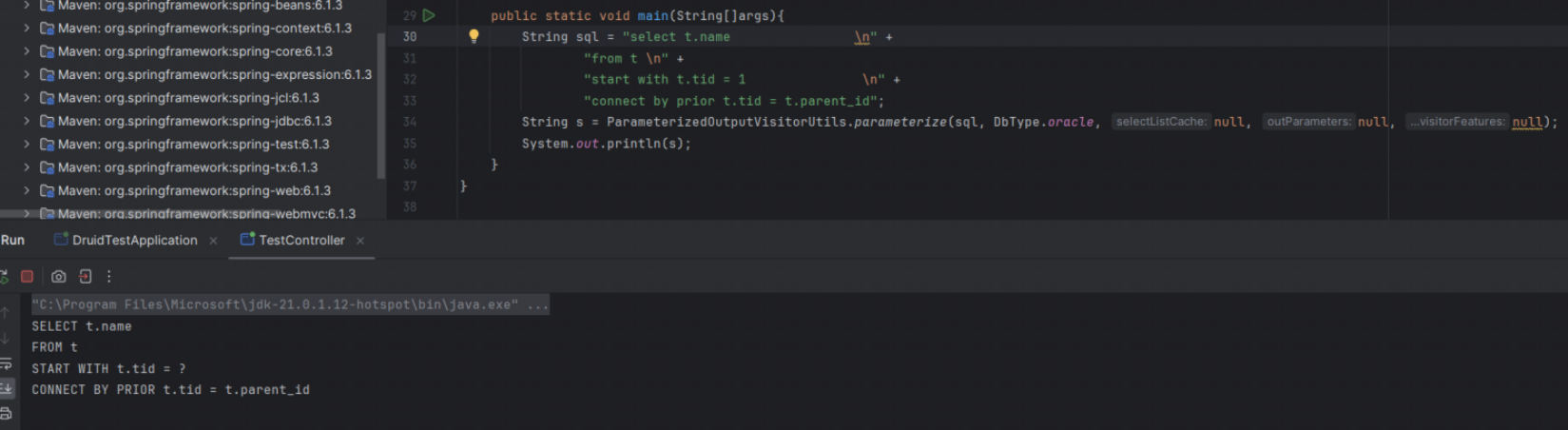
druid源码中在merge sql时会调用ParameterizedOutputVisitorUtils.parameterize(sql, null, null, null, null);此方法的第二个参数为dbType,此时传入为null,解析时不识别递归查询中的start关键字,因而抛出异常。
解决方法及规避方式
由于此异常对正常的业务流程无影响,忽略此异常或者关闭merge sql功能即可(设置spring.datasource.druid.filter.stat.mergeSql=false)
问题分析和处理过程
spring+druid连接池初始化时,要指定dbtype属性(由参数spring.datasource.druid.dbType指定)。但是druid目前不支持yashan,此参数的值又不能写成oracle。如果写成oracle,启动时会有如下异常:

所以,spring.datasource.druid.dbType的值就要设置为空或者YaShanDB。
无论设置为哪种,druid在merge sql的时候,都会进入dbType=null的分支,此时ParameterizedOutputVisitorUtils.parameterize方法就会抛出token IDENTIFIER start异常。
而此方法在dbType=oracle的时候,可以正常解析,不会抛出异常。但是由于druid支持的原因,我们无法在jvm进程启动时通过配置达到如下效果。
经验总结
如下为一个可以直接运行的springboot + druid + yashandb demo:















 648
648

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









