




简介:Streamlit是一个用于创建和分享数据应用程序的开源框架。本项目展示了如何利用Streamlit构建交互式数据可视化工具,并介绍了项目结构、配置和部署方式。开发者可以通过此项目学习Streamlit的基础知识,包括如何使用支持的库和直观的API,以及如何在不同环境中部署自己的应用。
1. Streamlit框架介绍
在现代的Web开发中,快速构建和部署数据驱动的应用变得越来越重要。 Streamlit 是一个专门为此设计的Python框架,它简化了这个过程,使得数据科学家和开发人员可以迅速将数据分析结果转化为交互式Web应用。
Streamlit的概念和特点
什么是Streamlit及其用途
Streamlit是一个开源库,允许用户轻松创建美观的Web应用,这些应用可以展示数据科学和机器学习的工作成果。它减少了前端开发的复杂性,让你能够专注于应用的逻辑和数据。
Streamlit相较于其他框架的优势
与传统的Web框架如Flask或Django相比,Streamlit的代码更简洁、直观。它隐藏了繁杂的前端细节,使用户能够以声明式的方式展示数据和布局。此外,Streamlit的热重载功能让开发过程更加高效,这使得你可以快速看到代码更改对应用的影响,无需重新启动服务器。
Streamlit的安装和基本使用
如何安装Streamlit
安装Streamlit非常简单,只需在你的环境中运行以下命令即可:
pip install streamlit
创建你的第一个Streamlit应用
安装完成后,创建一个新的Python文件(例如 app.py ),并输入以下代码:
import streamlit as st
st.title('我的第一个Streamlit应用')
st.write('欢迎使用Streamlit!')
之后,在命令行中运行 streamlit run app.py ,你的默认Web浏览器将自动打开并显示你的应用。
这个过程展示了Streamlit的快速入门特点。随着你对框架的深入了解,你会发现它还能够支持更复杂的功能,如数据输入、图表展示和更丰富的用户交互,这些内容将在后续章节中详细探讨。
2. 数据可视化基础
在数据分析和软件开发领域,数据可视化是一个不可或缺的组成部分,它通过图形化手段清晰有效地传达和呈现信息。在本章节中,我们将探讨数据可视化的重要性、常用的数据可视化库,并在Streamlit中进行实践。
2.1 数据可视化的重要性
数据可视化利用图形化手段,使得复杂的数据集更易于理解。它不仅有助于展示数据趋势和模式,而且可以提供洞察力,促进数据驱动的决策。
2.1.1 数据可视化的定义和作用
数据可视化是一个将数据转换为图形表示的过程,它使人们能够通过视觉元素快速识别和吸收信息。通过数据可视化,我们可以:
- 揭示数据集中的模式、趋势和异常。
- 通过视觉呈现简化复杂数据的理解。
- 提升沟通效果,使得非技术背景的观众也能理解数据集内容。
数据可视化不仅对数据科学家和分析师重要,它对任何需要分析和解释数据的人都是有价值的。
2.1.2 数据可视化在Streamlit中的应用
Streamlit作为一个为数据科学和机器学习设计的应用框架,支持直接在应用中集成数据可视化。这使得数据探索和可视化可以更紧密地集成,用户可以直观地在应用中与数据交互。
例如,在Streamlit应用中,用户可以上传数据集,然后立即在应用中展示数据的可视化结果,如柱状图、线图、散点图等。这不仅使得数据分析结果更加直观,而且提高了用户体验。
2.2 常用数据可视化库简介
Python社区提供了多个强大的数据可视化库。其中最为人熟知的两个库是matplotlib和seaborn,它们提供了丰富的可视化选项,并且与Streamlit兼容性良好。
2.2.1 matplotlib库基础使用
matplotlib是一个Python 2D绘图库,它能够在各种图形窗口和图像格式中绘制出版质量级别的图形。以下是使用matplotlib绘制简单折线图的基本代码示例:
import matplotlib.pyplot as plt
# 准备数据
x = [1, 2, 3, 4, 5]
y = [1, 4, 9, 16, 25]
# 绘制折线图
plt.plot(x, y)
# 添加标题和标签
plt.title('Simple Plot')
plt.xlabel('x values')
plt.ylabel('y values')
# 显示图表
plt.show()
此代码将输出一个基本的折线图,展示了x和y之间线性关系。 matplotlib.pyplot 是matplotlib中绘图的主要接口。
2.2.2 seaborn库的高级特性
seaborn是一个基于matplotlib的数据可视化库,它提供了更高级的接口,尤其擅长绘制统计图形。以下是如何使用seaborn库绘制一个散点图矩阵的示例代码:
import seaborn as sns
import pandas as pd
# 创建数据框
data = {
'Length': [2.2, 4.3, 5.1, 7.8, 6.5],
'Width': [1.2, 1.5, 2.1, 2.7, 3.2]
}
df = pd.DataFrame(data)
# 绘制散点图矩阵
sns.pairplot(df)
plt.show()
这段代码将生成一个散点图矩阵,展示了数据集中不同变量之间的关系。
2.3 Streamlit中的数据可视化实践
Streamlit不仅提供了一个易于使用的框架来创建数据应用,还支持在应用中直接集成数据可视化。
2.3.1 图表的基本绘制
在Streamlit中绘制图表非常简单。以下是一个在Streamlit应用中集成matplotlib绘制图表的完整示例:
import streamlit as st
import matplotlib.pyplot as plt
# Streamlit的标题和侧边栏内容
st.title('Data Visualization Example')
choice = st.sidebar.selectbox(
'Choose a graph type:',
('Line', 'Bar', 'Scatter')
)
# 选择数据
if choice == 'Line':
# 绘制折线图
st.line_chart([1, 2, 3, 4, 5])
elif choice == 'Bar':
# 绘制条形图
st.bar_chart([1, 2, 3, 4, 5])
else:
# 绘制散点图
st.area_chart([1, 2, 3, 4, 5])
这段代码将根据用户的选择在Streamlit应用中展示不同的图表类型。
2.3.2 利用Streamlit展示复杂数据
Streamlit也支持展示更复杂的数据可视化。例如,我们可以集成Plotly,一个支持更高级交互式的可视化库。以下是如何在Streamlit中集成Plotly绘制交互式散点图的代码:
import plotly.express as px
# 创建数据框
df = px.data.iris()
fig = px.scatter(df, x="sepal_width", y="sepal_length")
# 展示图表
st.plotly_chart(fig)
上述代码将创建一个基于鸢尾花数据集的交互式散点图,用户可以缩放和平移以查看不同的数据点。
结合Streamlit,数据可视化不仅变得简单,而且更加直观和互动,这极大地提高了用户体验和数据探索的效率。
3. Streamlit项目结构解释
在探索如何构建一个交互式数据应用时,理解Streamlit项目的结构至关重要。它不仅有助于你维护代码,而且对于在团队环境中协作同样必不可少。本章节将深入探讨Streamlit项目的文件结构、组件配置,以及开发和调试过程中的关键操作。
3.1 Streamlit项目的文件结构
3.1.1 文件和文件夹的作用
Streamlit应用通常以一个Python文件开始,也可以包含多个文件。这包括所有必要的数据文件、图像资源、以及第三方库文件。理解这些文件和文件夹在项目中的作用对于高效地组织你的Streamlit应用至关重要。
-
app.py:这是Streamlit应用的主入口文件。所有的Streamlit代码都写在这个文件中,它是运行应用时首先被调用的文件。 -
requirements.txt:包含了所有Python依赖项的列表。这个文件对于在不同环境中重现相同的依赖环境非常有用。 -
static/:用于存放静态文件,如图片、CSS样式表和JavaScript文件。Streamlit会自动让这些资源在应用中可用。 -
assets/:虽然不是Streamlit固有的文件夹,但它通常用来存放那些可能被静态文件引用的资源,如自定义CSS样式或JavaScript文件。 -
data/:存放数据文件,比如CSV、JSON或者其它格式的数据。这些数据可以被Streamlit应用读取和展示。
3.1.2 应用的代码组织方式
Streamlit框架设计上鼓励模块化和代码重用,因此理解和掌握代码组织方式是至关重要的。通常,你可以将代码分割成多个Python文件,并在主文件中导入和使用它们。
# app.py
import streamlit as st
from your_module import function_a, function_b
# 使用函数
function_a()
function_b()
# your_module.py
def function_a():
st.write("Function A has been called")
def function_b():
st.write("Function B has been called")
3.2 Streamlit项目组件的配置
3.2.1 静态资源的引用
在Streamlit中引用静态资源,如图片、样式表和JavaScript文件,可以让你的应用更加丰富和动态。Streamlit提供了简单的机制来引用这些资源。
# 引用图片
st.image('static/myimage.png')
# 引用CSS文件以改变Streamlit组件样式
st.markdown('<style>.reportview-container .main .block-container{padding-top:0rem}</style>', unsafe_allow_html=True)
# 引用JavaScript文件
st.components.v1.html('<script src="static/my_script.js"></script>', height=200)
3.2.2 页面布局和主题设置
Streamlit应用可以通过页面布局和主题设置来提高用户体验。Streamlit支持多种布局选项,并允许你选择主题。
# 使用页面布局组件
st.sidebar.write('This is the sidebar')
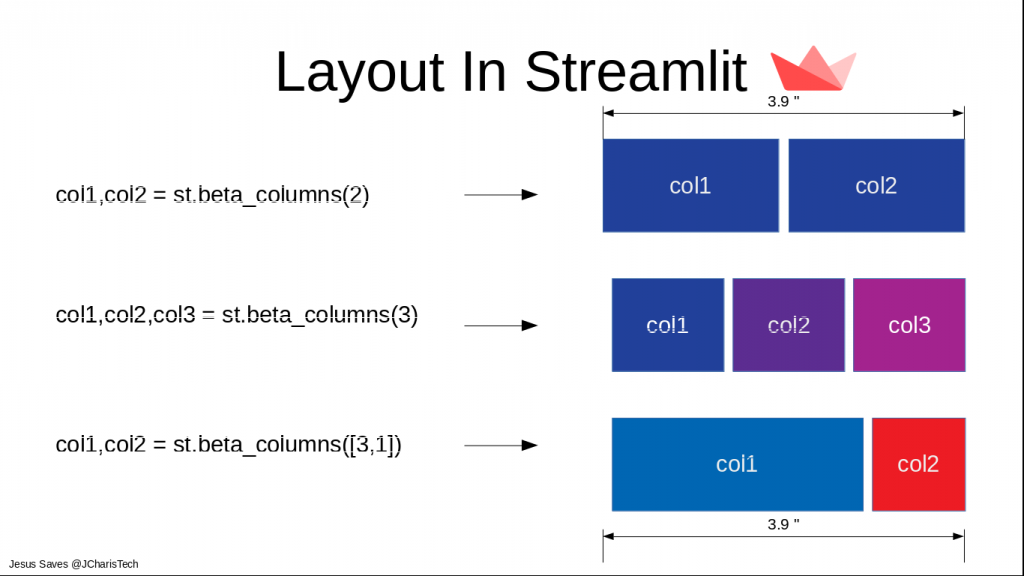
# 你还可以使用st.beta_columns()进行更复杂的布局设计
left_column, right_column = st.beta_columns(2)
# 设置主题
st.set_page_config(layout="wide")
3.3 应用的开发和调试
3.3.1 开发过程中的常见操作
在Streamlit应用开发过程中,了解一些常见的操作可以提高开发效率和应用性能。例如, st.cache 可以用来缓存函数的结果,从而加速数据加载和处理。
@st.cache
def expensive_computation(data):
# 进行复杂的计算
return result
data = st.experimental_get_query_params()
cached_data = expensive_computation(data)
3.3.2 调试Streamlit应用的技巧
调试对于任何开发者来说都是不可或缺的技能,Streamlit提供了 st调试 模式来帮助开发者快速定位问题。
# 开启调试模式
st.set_page_config(layout="wide", initial_sidebar_state="expanded")
st.debug("Hello, World!")
调试模式会在应用页面上显示变量和数据的详细信息,这对于快速识别问题非常有帮助。
通过本章节的介绍,你已经对Streamlit项目的结构有了深入的理解。下一章,我们将探讨如何使用Python依赖管理工具与Streamlit配置文件,以及如何打包和分发你的Streamlit应用。
4. Python依赖管理与Streamlit配置文件说明
4.1 Python依赖管理工具介绍
4.1.1 pip和pipenv的使用对比
在Python开发过程中,依赖管理是保证项目环境一致性的关键步骤。传统的依赖管理工具是 pip ,它是Python包安装器,被广泛用于安装和管理Python包。然而,随着项目复杂度的增加,使用 pip 直接安装依赖可能会导致依赖冲突和环境混乱。这时, pipenv 应运而生,它自动创建和管理虚拟环境,并通过 Pipfile 维护依赖列表,使得项目依赖的管理和追踪变得更为简单和可靠。
使用 pipenv 的步骤:
- 安装
pipenv:
bash pip install pipenv - 在项目根目录下初始化
pipenv:
bash pipenv install
这将创建两个文件:Pipfile和Pipfile.lock。Pipfile列出了开发依赖和生产依赖,而Pipfile.lock确保依赖的精确性和可复现性。
使用 pipenv 与 pip 的对比:
-
pipenv创建的虚拟环境位于~/.local/share/virtualenvs/,而pip的虚拟环境通常在项目目录下,且管理更为松散。 -
pipenv使用Pipfile代替requirements.txt,使得依赖管理更为友好。 -
pipenv自动处理依赖的冲突和环境隔离,而使用pip安装需要手动确保环境的一致性。 -
pipenv结合了pip和virtualenv的功能,简化了开发工作流程。
4.1.2 创建依赖管理文件
依赖管理文件的作用:
依赖管理文件是项目依赖的蓝图,它详细记录了项目运行所需的全部库及其版本,保证了项目在不同环境中的一致性。以下是常用的依赖管理文件:
-
requirements.txt: 用于记录使用pip安装的依赖。 -
Pipfile和Pipfile.lock: 由pipenv使用,分别记录依赖和锁定依赖版本。 -
setup.py: 用于Python包的分发,可以包含依赖信息。
创建和使用依赖管理文件:
-
使用
pipenv创建依赖管理文件:
bash cd your_project pipenv install numpy pandas
这会自动在Pipfile中添加依赖并创建Pipfile.lock。 -
如果你使用
requirements.txt,可以通过以下方式生成:
bash pip freeze > requirements.txt
当你分发项目时,其他人可以通过以下方式安装依赖:
bash pip install -r requirements.txt
通过使用依赖管理文件,项目可以清晰地知道需要哪些依赖,同时避免不同环境中的依赖冲突,这对于团队协作和项目部署至关重要。
4.2 Streamlit配置文件的深入解析
4.2.1 配置文件的作用和结构
Streamlit应用的配置文件允许开发者自定义应用的行为,例如应用名称、依赖库版本和主题样式。配置文件通常名为 streamlit_config.py ,位于项目的根目录。
配置文件的主要作用包括:
- 维护应用的基本配置,如应用名称、布局设置等。
- 调整样式和主题,以符合品牌或个人偏好。
- 管理应用的依赖和扩展,确保应用的稳定运行。
配置文件的结构一般包含多个配置项,例如:
# streamlit_config.py
# 设置应用标题
st.set_page_config(
page_title="My Streamlit App",
page_icon=":bar_chart:",
initial_sidebar_state="expanded",
)
# 自定义样式
st.markdown("""
<style>
body{background-color: #f5f5f5}
</style>
""", unsafe_allow_html=True)
在这个例子中,我们设置了应用的标题、图标和侧边栏的初始状态,并自定义了应用的背景颜色。
4.2.2 如何自定义Streamlit的配置
要自定义Streamlit配置,你需要在配置文件中使用 st.set_page_config 方法和自定义样式。例如,你可以设置应用的标题、页面图标和侧边栏的状态:
# 设置页面图标和标题
st.set_page_config(
page_title="My Customized App",
page_icon=":tada:",
layout="wide"
)
# 添加自定义CSS样式来改变按钮颜色
custom_css = """
<style>
button{-webkit-appearance: none;
appearance: none;
background-color: #009879;
border: none;
border-radius: 3px;
color: white;
cursor: pointer;
font-size: 150%;
margin: 0;
padding: 5px 10px;
}
button:hover {
background-color: #007d6a;
}
</style>
"""
st.markdown(custom_css, unsafe_allow_html=True)
# 自定义组件
my_button = st.button('Click Me!')
if my_button:
st.success('You clicked the button!')
通过这种方式,你可以改变Streamlit应用的多个方面,包括用户界面的美观和用户体验。自定义配置不仅可以提升应用的外观,还能增强用户与应用的互动性。
4.3 应用的打包与分发
4.3.1 应用打包的步骤
打包你的Streamlit应用是将所有依赖和代码压缩成一个可执行文件的过程,使其可以在没有Python环境的计算机上运行。打包的一个流行工具是PyInstaller。以下是打包的基本步骤:
-
安装PyInstaller:
bash pip install pyinstaller -
在命令行中使用PyInstaller打包你的应用:
bash pyinstaller your_script.py --onefile --windowed这里
your_script.py是你的Streamlit应用的主脚本文件。--onefile参数会将所有依赖打包到一个单一的可执行文件中,而--windowed参数会防止控制台窗口在应用启动时打开。 -
PyInstaller会在
dist文件夹中创建可执行文件。
4.3.2 如何分享和部署你的Streamlit应用
分享和部署Streamlit应用涉及到让应用在线上环境中运行,以便其他人可以通过互联网访问。部署过程可以简单也可以复杂,取决于你的需求。
一种常见的方法是使用免费的云平台服务,如Heroku,来部署你的应用。以下是部署到Heroku的基本步骤:
- 在Heroku上创建一个新的应用。
- 将你的应用代码推送到Heroku Git仓库。
- 设置环境变量,例如
PORT和STREAMLIT_HOME。 - 通过Heroku CLI运行你的应用或在Heroku仪表板上部署。
部署到Heroku的基本流程示意代码:
# 初始化Heroku项目
heroku create my-streamlit-app
# 设置环境变量
heroku config:set PORT=8501
heroku config:set STREAMLIT_HOME=/tmp/streamlit
# 部署你的Streamlit应用
git push heroku main
# 启动应用
heroku ps:scale web=1
# 打开应用查看
heroku open
注意:部署到其他平台(如AWS, GCP, Azure等)会涉及不同的步骤,通常需要更详细的配置和环境设置。你可以根据实际情况选择最适合你的部署方法。
打包和部署是将Streamlit应用从本地开发环境推向生产环境的重要步骤。理解这些步骤和工具能够帮助你更有效地分发你的应用,使其能够被更多人使用。
5. 交互式UI元素创建与项目部署
5.1 Streamlit中的交互式UI组件
Streamlit的核心理念之一就是简化交互式UI元素的创建过程。它提供了多种内置组件来实现输入和输出的功能。
5.1.1 输入控件的创建和应用
Streamlit允许开发者轻松创建各种输入控件,这些控件可以响应用户的操作并实时更新显示结果。举个例子, st.text_input 、 st.number_input 、 st.slider 等都是常用的输入控件。
import streamlit as st
# 文本输入
user_name = st.text_input('请输入你的名字', '张三')
# 数字输入
user_age = st.number_input('请输入你的年龄', 25)
# 范围滑块
price = st.slider('选择你愿意支付的价格', 100, 1000, 500)
# 输出结果
st.write(f'名字: {user_name}, 年龄: {user_age}, 价格: {price}')
5.1.2 输出控件的使用技巧
输出控件是将数据以可视化方式展示给用户的关键。Streamlit提供了诸如 st.write 、 st.dataframe 、 st.plotly_chart 等输出控件,让数据展示变得更灵活。
import pandas as pd
import numpy as np
import altair as alt
# 随机生成数据
data = pd.DataFrame(
np.random.randn(10, 2),
columns = ['a', 'b']
)
# 在Streamlit中展示数据
st.write(data)
# 使用图表展示数据
chart = alt.Chart(data).mark_line().encode(
x='a',
y='b'
)
st.write(chart)
5.2 Streamlit中的高级交互功能
Streamlit不仅仅能创建简单的交互式UI,其设计哲学还支持复杂的交互逻辑和数据处理。
5.2.1 交互式数据操作
Streamlit允许开发者进行复杂的交互式数据操作,这些操作可以直接在用户的会话中进行。例如,用户可以上传一个数据文件,然后开发者编写代码来分析这个文件。
# 允许用户上传数据文件
uploaded_file = st.file_uploader("上传一个CSV文件", type="csv")
if uploaded_file is not None:
# 读取上传的文件
data = pd.read_csv(uploaded_file)
# 展示数据
st.dataframe(data.head())
# 其他数据操作...
5.2.2 应用中的数据存储与读取
对于临时数据存储和读取,Streamlit提供了内置的会话状态管理功能。这意味着开发者可以很容易地在不同用户的会话间保持应用状态。
# 保存数据到会话状态
if 'user_count' not in st.session_state:
st.session_state['user_count'] = 0
st.session_state['user_count'] += 1
# 读取并显示会话状态中的数据
st.write(f'当前访问次数: {st.session_state.user_count}')
5.3 应用的部署与运维
部署是应用开发的最后一步,确保应用稳定和可访问对于最终用户来说至关重要。
5.3.1 本地部署的流程和注意事项
本地部署通常用于测试和演示目的,但有时候也适用于小规模的应用部署。在部署之前,确保你的应用是无状态的,可以快速启动,以及设置合适的环境变量。
# 保存环境变量
import os
os.environ["STREAMLIT_SERVER_PORT"] = "8501"
# 启动本地服务
import streamlit as st
st.run()
5.3.2 云平台部署与自动化的探讨
云平台提供了更灵活的部署选项,包括但不限于Heroku、AWS和Google Cloud Platform。自动化部署流程可以使用GitHub Actions或者GitLab CI/CD来实现持续部署。
flowchart LR
A[代码提交] --> B{是否通过CI测试?}
B -- 是 --> C[构建镜像]
B -- 否 --> Z[终止流程]
C --> D[推送到容器注册中心]
D --> E[自动部署到云服务]
注意 :上述流程图是一个简化的部署流程,实际上云服务部署需要考虑更多因素,如安全性、监控、资源限制等。
部署到云服务后,还需要定期进行应用维护和监控。通过集成监控工具来监控应用性能,可以帮助及时发现并解决潜在的问题。
简介:Streamlit是一个用于创建和分享数据应用程序的开源框架。本项目展示了如何利用Streamlit构建交互式数据可视化工具,并介绍了项目结构、配置和部署方式。开发者可以通过此项目学习Streamlit的基础知识,包括如何使用支持的库和直观的API,以及如何在不同环境中部署自己的应用。


















 1410
1410

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









