






逻辑回归将样本特征和样本发生的概率联系起来,用于解决分类问题。
Sigmoid 函数
在最简单的二分类中,逻辑回归里样本发生的概率的值域为 [0, 1],对于线性回归 $\hat{y} = \theta^T·x_b$,为了将 $\hat y$ 映射到值域 [0, 1] 中,引入了 $\sigma$ 函数得到了概率函数 $\hat p$,即:
$$
\hat p=\sigma(\theta^T·x_b), \hat p\in[0, 1]
$$
Sigmoid 函数 $\sigma$ 表示为:$\sigma(t)=\frac{1}{1+e^{-t}}$,图示如下:
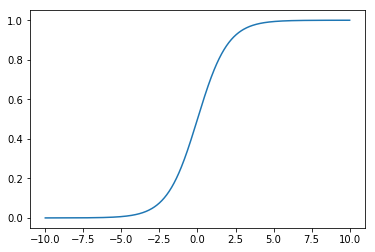
当 t > 0 时,$\sigma$ > 0.5;当 t < 0 时,$\sigma$ < 0.5。因此可对二分类的分类方式为:
$$\hat y=\begin{cases} 1, & \hat p \geq 0.5 \\ 0, & \hat p \leq 0.5 \end{cases}; \hat p=\sigma(\theta^T·x_b)=\frac{1}{1+e^{-\theta^T·x_b}}$$
损失函数
如果实际的分类为1,p 越小时,损失越大;如果实际的分类为0,p 越大时,损失越大。引入 log 函数表示则为:
$$
-ylog(\hat p)-(1-y)log(1-\hat p)
$$
当 y=0 时,损失为 $-log(1-\hat p)$;当 y=1 时,损失为 $-log(\hat p)$。
对于有 m 样本的数据集 (X, y),损失函数为:
$$
J(\theta)=-\frac{1}{m}\sum_{i=1}^my^{(i)}log(\sigma(X_b^{(i)}\theta))+(1-y^{(i)})log(1-\sigma(X_b^{(i)}\theta))
$$
其中:$X_b^{(i)} = (1,x_{1}^{(i)},x_{2}^{(i)},...,x_{n}^{(i)})$;$\theta = (\theta_{0}, \theta_{1}, \theta_{2},..., \theta_{n})^T$。
损失函数的梯度
为了得到在损失尽可能的小的情况下的 $\theta$,可以对 $J(\theta)$ 使用梯度下降法,结果为:
$$
\nabla J(\theta) = \frac{1}{m}·\begin{pmatrix} \sum_{i=1}^{m}(\sigma(X_b^{(i)}\theta) - y^{(i)}) \\\ \sum_{i=1}^{m}(\sigma(X_b^{(i)}\theta) - y^{(i)})·X_1^{(i)} \\\ \sum_{i=1}^{m}(\sigma(X_b^{(i)}\theta) - y^{(i)})·X_2^{(i)} \\\ \cdots \\\ \sum_{i=1}^{m}(\sigma(X_b^{(i)}\theta) - y^{(i)})·X_n^{(i)} \end{pmatrix}
$$
略去了公式的推导过程。
进行向量化处理后结果为:
$$
\nabla J(\theta) = \frac{2}{m}·X_b^T·(\sigma(X_b\theta)-y)
$$
实现二分类逻辑回归算法
使用 Scikit Learn 的规范将逻辑回归的过程封装到 LogisticRegression 类中。
_init_() 方法首先初始化逻辑回归模型,_theta 表示 $\theta$,interception_ 表示截距,chef_ 表示回归模型中自变量的系数:
class LogisticRegression:
def __init__(self):
self.coef_ = None
self.interceiption_ = None
self._theta = None
_sigmoid() 方法实现 Sigmoid 函数:
def _sigmoid(self, t):
return 1 / (1 + np.exp(-t))
fit() 方法根据训练数据集训练模型,J() 方法计算损失 $J\theta$,dJ() 方法计算损失函数的梯度 $\nabla J(\theta)$,gradient_descent() 方法就是梯度下降的过程,X_b 表示添加了 $x_{0}^{(i)}\equiv1$ 的样本特征数据:
def fit(self, X_train, y_train, eta=0.01, n_iters=1e4):
def J(theta, X_b, y):
y_hat = self._sigmoid(X_b.dot(theta))
try:
return - np.sum(y * np.log(y_hat) + (1 - y) * np.log(1- y_hat) ** 2) / len(y)
except:
return float('inf')
def dJ(theta, X_b, y):
return X_b.T.dot(self._sigmoid(X_b.dot(theta)) - y) /len(y)
def gradient_descent(X_b, y, initial_theta, eta, n_iters=n_iters, epsilon=1e-8):
theta = initial_theta
i_ters = 0
while i_ters < n_iters:
gradient = dJ(theta, X_b, y)
last_theta = theta
theta = theta - eta * gradient
if (abs(J(theta, X_b, y) - J(last_theta, X_b, y)) < epsilon):
break
i_ters += 1
return theta
X_b = np.hstack([np.ones((len(X_train), 1)), X_train])
initial_theta = np.zeros(X_b.shape[1])
self._theta = gradient_descent(X_b, y_train, initial_theta, eta)
self.interception_ = self._theta[0]
self.coef_ = self._theta[1:]
return self
predict_proba() 将传入的测试数据与训练好模型后的 $\theta$ 经过计算后返回该测试数据的概率:
def predict_proba(self, X_predict):
X_b = np.hstack([np.ones((len(X_predict), 1)), X_predict])
return self._sigmoid(X_b.dot(self._theta))
predict() 方法将经过 predict_proba() 方法得到的测试数据的概率以 0.5 为界转换成类别(0或1):
def predict(self, X_predict):
proba = self.predict_proba(X_predict)
return np.array(proba >= 0.5, dtype='int')
score() 将测试数据集的预测分类与实际分类进行比较计算模型准确度:
def score(self, X_test, y_test):
y_predict = self.predict(X_test)
return sum(y_predict == y_test) / len(y_test)
决策边界
对于 $\hat p=\sigma(\theta^T·x_b)=\frac{1}{1+e^{-\theta^T·x_b}}$,要使 $\hat p=0.5$ 则 $\theta^T·x_b=0$,这就是决策边界。
假设 X 数据集只有两个特征,则由 $\theta_0+\theta_1x_1+\theta_2x_2=0$ 得到 $x_2$ 和 $x_1$ 的关系为:
$$
x_2=\frac{-\theta_0-\theta_1x_1}{\theta_2}
$$
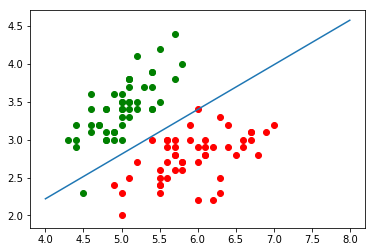
如图所示,图中的点为只有两个特征的数据,纵轴为特征 $x_2$,横轴为特征 $x_1$,梯度下降法得到的 $\theta$ 与上面公式计算后的决策边界即为图中斜线:
逻辑回归中使用多项式特征
对于多项式回归,如对 $y=x_1^2+x_2^2-r$ 进行逻辑回归,可以将 $x_1^2$ 看作一个特征 $z_1$,将 $x_2^2$ 看作一个特征 $z_2$,Scikit Learn 提供了 PolynomialFeatures 可以方便的进行转换。
举例如下。首先准备数据:
import numpy as np
X = np.random.normal(0, 1, size=(200, 2))
y = np.array(X[:, 0] ** 2 + X[:, 1] ** 2 < 1.5, dtype='int')
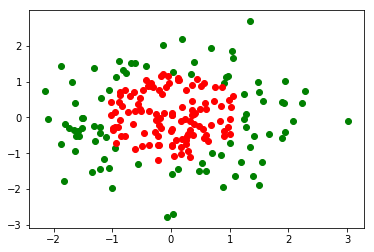
数据可视化如图:
使用前面的 LogisticRegression 类进行逻辑回归,并且使用 Scikit Learn 的 Pipeline 将多项式特征、数据归一化和逻辑回归组合在一起:
from LogisticRegression import LogisticRegression
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import PolynomialFeatures
from sklearn.preprocessing import StandardScaler
def PolynomailLogisticRegression(degree):
return Pipeline([
('poly', PolynomialFeatures(degree=degree)),
('std_scaler', StandardScaler()),
('log_reg', LogisticRegression())
])
设定 PolynomialFeatures 处理后得到的新的特征数据最高维度为2,然后 fit() 方法训练模型:
poly_log_reg = PolynomailLogisticRegression(degree=2)
poly_log_reg.fit(X, y)
得到模型可视化如图:

Scikit Learn 中的逻辑回归
Scikit Learn 中的 linear_model 模块中也提供了逻辑回归的算法,同时也封装了模型正则化相关的内容。
根据正则化中的正则项的不同,正则化的方式主要有四种:
$J(\theta)+\alpha L_1$
$J(\theta)+\alpha L_2$
$C·J(\theta)+L_1$
$C·J(\theta)+L_2$
Scikit Learn 中的逻辑回归算法的模型正则化采用后两种的方式。
L1 为 L1正则项,即 $\sum_{i=1}^n|\theta_i|$,LASSO 回归使用了L1;
L2 为 L2正则项,即 $\frac{1}{2}\sum_{i=1}^n\theta_i^2$,岭回归使用了L2;
Scikit Learn 的逻辑回归算法中的参数 c 设定 C 的大小,参数 penalty 设定使用哪种正则项(l1 或 l2)。使用方式如下:
from sklearn.linear_model import LogisticRegression
def PolynomailLogisticRegression(degree, C, penalty='l2'):
return Pipeline([
('poly', PolynomialFeatures(degree=degree)),
('std_scaler', StandardScaler()),
('log_reg', LogisticRegression(C=C, penalty=penalty))
])
poly_log_reg = PolynomailLogisticRegression(degree=20, C=0.1, penalty='l1')
poly_log_reg.fit(X_train, y_train)
OvR 与 OvO
前面说的都是二分类的逻辑回归,如果要进行多分类的逻辑回归,有 OvR 和 OvO 两种方式。
OvR(One vs Rest)将多类别简化成其中一个类别和其余类别为一个类别这种二分类,因此 n 个类别就进行 n 次分类,对于新的数据,看它在这 n 个分类结果中哪个分类得分最高即为哪个类别。
OvO(One vs One)在多类别中选取两个类别作为二分类,因此 n 个类别就进行 $C_n^2$ 次分类,对于新的数据,看它在这 $C_n^2$ 次分类结果中数量最大即为哪个类别。
Scikit Learn 的逻辑回归算法中的参数 multi_class 用于设定使用 OvR(参数值为 ovr)还是 OvO(参数值为 multinomial),如:
LogisticRegression(multi_class='ovr')
LogisticRegression(multi_class='multinomial')
同时 Scikit Learn 中的 multiclass 模块中也提供了 OneVsRestClassifier(OvR)类和 OneVsOneClassifier(OvO)类,可以将任意的二分类算法(要求符合 Scikit Learn 规范)应用在这两个类上完成多分类。使用方式如下:
# OvR
from sklearn.multiclass import OneVsRestClassifier
ovr = OneVsRestClassifier(LogisticRegression())
ovr.fit(X, y)
# OvO
from sklearn.multiclass import OneVsOneClassifier
ovo = OneVsOneClassifier(log_reg)
ovo.fit(X, y)














 111
111











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









