






Spark SQL读取hive数据的关键在于将hive的元数据作为服务暴露给Spark。除了通过上面thriftserver jdbc连接hive的方式,也可以通过下面这种方式:
首先,配置 $HIVE_HOME/conf/hive-site.xml,增加如下内容:
<property>
<name>hive.metastore.uris</name>
<value>thrift://ip:port</value>
</property>然后,启动hive metastore
最后,将hive-site.xml复制或者软链到$SPARK_HOME/conf/。如果hive的元数据存储在mysql中,那么需要将mysql的连接驱动jar包如mysql-connector-java-5.1.12.jar放到$SPARK_HOME/lib/下,启动spark-sql即可操作hive中的库和表。而此时使用hive元数据获取SparkSession的方式为:
val spark = SparkSession.builder()
.config(sparkConf).enableHiveSupport().getOrCreate()
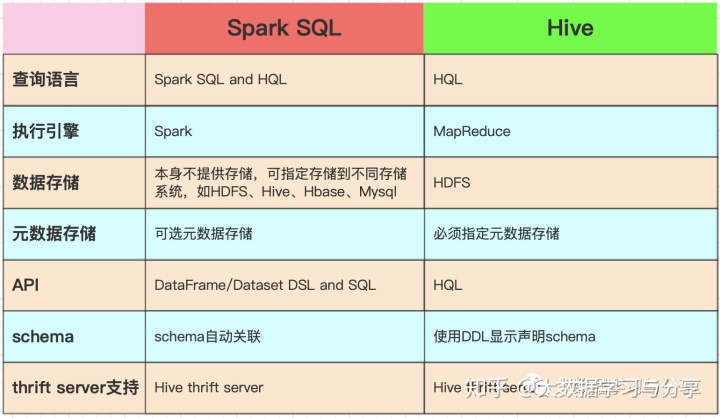
Spark SQL与Hive的区别
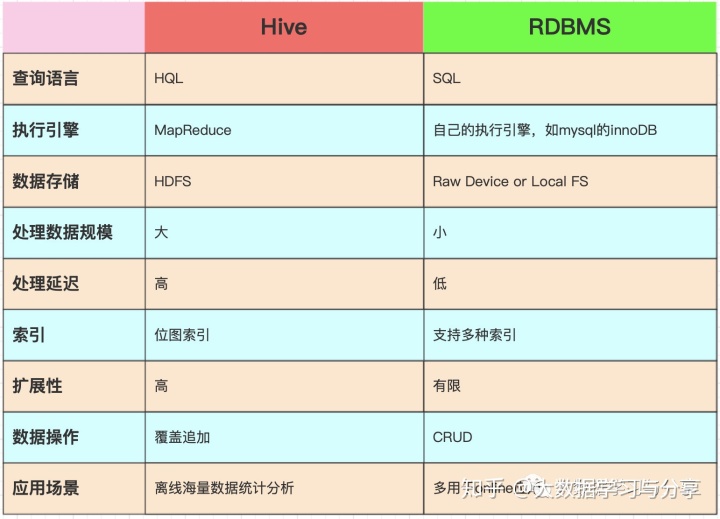
Hive与传统的关系型数据库对比
推荐文章:
Spark SQL解析查询parquet格式Hive表获取分区字段和查询条件
Spark SQL
Apache Hive
关注 微信公众号:大数据学习与分享,获取更多技术干货














 674
674











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









