






参考:
廖雪峰的解释
http://openskill.cn/article/448
python字符编码
了解编码历史
计算机只能存储数字,不能存储字符等. 文字等必须映射成数字,然后存储到硬盘.
计算机美国发明的,他们发明1个字节(8bit),最多256个字符映射的assicc表.只满足了英语国家
中文,韩文等存储,assicc码不够.最后国际统一unicode(占2个字节),但是字母汉字混排,这样造成存储和网络传输浪费.
出现了可变长的utf-8编码,特性: 在存储时候,遇到英语1个字节存,汉字3个字节存.特别生僻字4-6个字节存.
在encode时候,必须保证前面是unicode字符串
小结:
ascii(1)-->unicode(2)-->utf-8(可变长;文件保存,网络传输)
python编码操作规则

python在内存中操作的一律是unicode编码
python在硬盘中存储是utf-8编码(自己设置)
一些py库默认读文件到内存时候,默认会将文件转为unicode.
浏览网页的时候,服务器会把动态生成的Unicode内容转换为UTF-8再传输到浏览器:
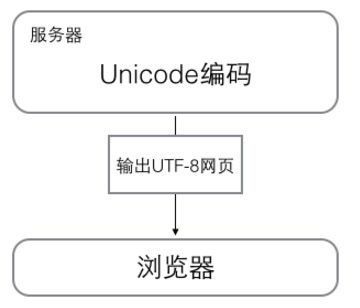
所以你看到很多网页的源码上会有类似的信息,表示该网页正是用的UTF-8编码。
windows下操作
>>>s = '我用python'
>>>su='我用python'
>>> s.decode("utf8")
Traceback (most recent call last):
File "", line 1, in File "C:\Python27\lib\encodings\utf_8.py", line 16, in decode
return codecs.utf_8_decode(input, errors, True)
UnicodeDecodeError: 'utf8' codec can't decode byte 0xce in position 0: invalid continuation byte
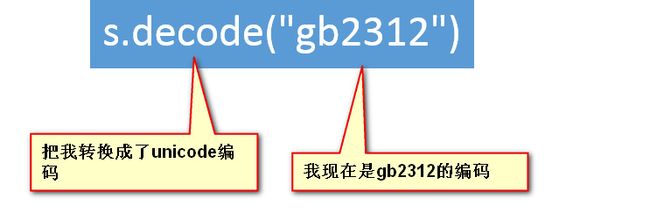
>>>s.decode("gb2312")
>u'\u6211\u7528python'
注意
- windows默认编码gb2312
- linux默认编码utf-8
s.decode(“utf8”).encode(“utf8”)
s.decode(“gb2312”).encode(“gb2312”)
查看py默认的字符编码
>>>import sys
>>>sys.getdefaultencoding()
'ascii'
直接encode先会隐式调用默认编码格式decode操作,然后再执行这个.
s="我用python"
s.encode("utf8") #会隐式调用s.decode("ascii"),因为win是gb2312,所以报错
解析:s.decode(“ascii”)已经会报错
正确操作(win)
s="我用python"
s.decode("gb2312").encode("gb2312")
>>>s="我用python"
>>>s.decode("gb2312").encode("gb2312")
'\xce\xd2\xd3\xc3python' # 这里虽然乱码,但是用print显示正常了.
>>>print s.decode("gb2312").encode("gb2312")
我用python
存储的时候即用unicode
su = u"我用python"
su.encode("gb2312") # su已是unicode,然后encode时候就不会报错.
python3的区别
s="我用python" # 前面默认给加了u
s.encode("utf8")
还有些不太理解的地方需要进一步查询
2017年8月21日
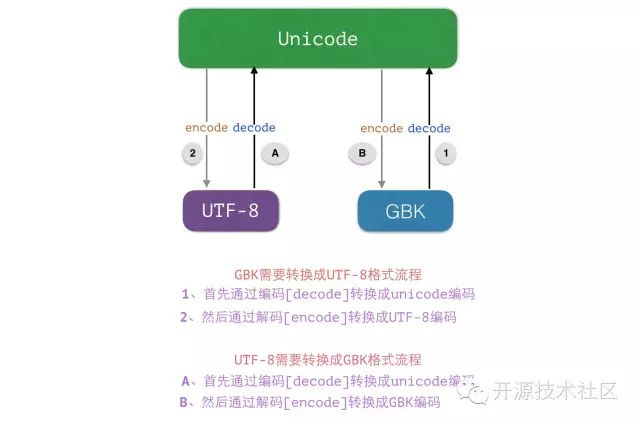
字节码之间的互转:
#!/usr/bin/env python2
# _*_coding:utf-8_*_
# Author: Lucky.chen
import sys
print(sys.getdefaultencoding())
msg = "我爱北京天安门"
msg_gb2312 = msg.decode("utf-8").encode("gb2312")
gb2312_to_gbk = msg_gb2312.decode("gbk").encode("gbk")
print(msg)
print(msg_gb2312)
print(gb2312_to_gbk)
借助chardet彻底理解py编码
pip install chardet
on windows
>>> import chardet
>>> s = '我用python' # win上存储编码是gb2312,和你打开一个文件保存,编码一样. 道理一样.
# 检测编码格式,None我怀疑py无法显示gb2312
>>> chardet.detect(s)
{'confidence': 0.0, 'language': None, 'encoding': None}
# win上用gb2312转unicode是成功的
>>> print s.decode("gb2312").encode("gb2312")
我用python
# win上用utf8转unicode是失败的,为什么? 因为s本身保存时候就是gb2312编码保存的
>>> print s.decode("utf8").encode("utf8")
Traceback (most recent call last):
File "", line 1, in
File "C:\Python27\lib\encodings\utf_8.py", line 16, in decode
return codecs.utf_8_decode(input, errors, True)
UnicodeDecodeError: 'utf8' codec can't decode byte 0xce in position 0: invalid continuation byte
>>>
on linux
In [4]: import chardet
In [4]: s = '我用python'
# 检测编码格式utf8
In [5]: chardet.detect(s)
Out[5]: {'confidence': 0.75249999999999995, 'encoding': 'utf-8', 'language': ''}
In [6]: print s.decode("utf8").encode("utf8")
我用python
In [7]: print s.decode("gb2312").encode("gb2312")
---------------------------------------------------------------------------
UnicodeDecodeError Traceback (most recent call last)
7-a1d2c98e0fd6> in ()
----> 1 print s.decode("gb2312").encode("gb2312")
UnicodeDecodeError: 'gb2312' codec can't decode bytes in position 0-1: illegal multibyte sequence














 5538
5538











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









