







前言
这个前言其实也没啥好写的,主要是想要和以前的文章风格保持一致吧,哈哈,先皮一吧。其实不是啦,好,开始进入正题。hadoop是一个分布式文件系统,我们想要的要求就是必须安全和稳定,不能说动不动整个集群就挂掉了,也不能动不动集群里面的数据就丢失了或者损坏了,还要能处理海量的数据,于是为了解决不限于以上的这些问题,hadoop就设计了四个机制,分别为:心跳机制,安全机制,机架策略(副本存放策略),负载均衡。
好了,前提情况已经给大家介绍完毕,那么我们接下来就给大家分别介绍一下这四大机制,注意,本文章更侧重于思想,不会出现代码,作为一个程序员要想走上大神之路,最重要的是思想,思想决定了高度,废话不多说,开始。
心跳机制
我们第一个要讲的就是心跳机制。这里有个小知识点,集群节点之间必须要做时间同步。
我们知道namenode是集群的大哥,负责集群上任务的分工,那如果要进行分工,首先一点就是要知道各个从节点的存活状态,你想想如果连哪个从节点是否存活都不知道,又该如何分配任务呢?可是,就有个疑问了,他是怎么知道各个从节点的存活状态的呢?那就是通过DataNode定期的向namenode发送心跳报告,哎?对了,这就是心跳机制。
DataNode默认会每隔3秒向namenode发送一次心跳报告,目的就是告诉namenode,大哥,小弟我还活着呢,砍谁你说,我上。注意我说的是默认哦,其实这个值可以改的,在哪里改呢,就是hdfs-default.xml配置文件里面。
<property>
<name>dfs.heartbeat.interval</name>
// <value>3</value>
<description>Determines datanode heartbeat interval in seconds.</description>
</property>我们看到是3秒,当然了,你在配置hadoop的时候说我不想让他3秒,就让他10秒,那你就可以改成10秒,不过什么后果我可没试过哦,哈哈,你可以试一试。
接下来我们思考一个问题,datanode有没有可能会不给namenode发送心跳呢?是的,会的,上面我们知道了namenode就是通过接受datanode的心跳来确保datanode存活,好了,这下子不发了,咋办?难道就直接断定datanode死了吗?不是的,namenode会给datanode为10次的机会,如果datanode在30秒的时间还没有向namenode发送心跳,namenode就暂时的,记住是暂时的认为datanode死亡了,于是namenode就会每隔5秒钟向datanode发送一次检查,如果发送了两次依旧还没有收到datanode的消息,那么namenode就断定这个小弟不靠谱,可能被仇人给砍死了,也就是判定这个datanode节点挂掉了。
同样的,也有个配置文件标识一次检查的时间。
<property>
<name>dfs.namenode.heartbeat.recheck-interval</name>
<value>300000</value>
<description>
This time decides the interval to check for expired datanodes.
With this value and dfs.heartbeat.interval, the interval of
deciding the datanode is stale or not is also calculated.
The unit of this configuration is millisecond.
</description>
</property>我们看到是300000毫秒,也就是5分钟。所以,我们总结,namenode断定datanode死亡的时间加起来就是630秒,面试的时候面试官可能会问到,记住这个数字哦。
安全模式
上面说完了心跳机制,接下来就说一说安全模式。
要想说清楚这个事情,我们还需从头说起。先聊一聊namenode启动的时候需要做那些事情,首先知道一个概念,就是元数据。元数据包括三部分,第一:存贮抽象目录树,第二:存贮数据和块的映射关系,比如我们一个数据是abc.txt,那么与之对应就会生成一个块为blk_xxxx.第三:数据块存贮的位置信息。
接下来我们再考虑一个问题元数据存贮在哪里呢?好问题。
第一:存贮在磁盘中
我们现在来思考一个问题,如果单纯地就存贮在磁盘中,那么每次进行文件读写操作的时候,都需要对磁盘进行读写操作,必然会造成读写的性能比较低,因为磁盘IO是限制所有计算机的一个主要问题。所以为了解决问题就引入第二个存贮位置。
第二:存贮在内存中
存贮在内存中的好处就是,读写快,可是也是有缺点的,那就是服务器一旦关机,所有的内存将被清空。
所以为了保险起见,我们就把元数据存贮在磁盘和内存中各一份,但是存储的内容稍微有些区别。
内存中会存储所有的元数据,包括抽象目录树,数据和块的映射关系,还是数据块的存贮位置信息,但是第三点稍微有一点疑问,我们一会儿再说。好,再说磁盘,磁盘中只会存贮抽象目录树和数据与块的映射关系。
接下来我们就来详细聊一聊namenode是怎么加载元数据的,也就解答了上面我留的疑问。
当集群第一次启动的时候,首先会将磁盘中的抽象目录和磁盘与块的映射关系加载内存中,可是我们上面不是说内存中还有数据块的存贮位置信息吗?磁盘中没有,那这些数据从哪里来的呢?这就用到了我们上面讲的第一个机制,就是心跳机制,上面说心跳机制的时候,只说了datanode会通过心跳的方式告诉namenode是否存活,其实还有第二个作用就是会报告datanode中的数据块的位置信息。好了,我们在思考一个问题,那就是为什么磁盘中不直接存贮数据块的位置信息呢?因为hadoop考虑到,数据块的位置存贮位置信息比较大,如果也存贮在磁盘中的话,那么当讲磁盘中的数据加载到内存中的时候,加载的时间会非常长,所以采用心跳机制来获取。
有了上面的前提知识,我们就可以接下去了解了。
集群启动的时候按照以下加载:
1)先启动namenode,namenode会将磁盘中的数据加载到内存中
2)再启动datanode,这个时候datanode会通过心跳机制给namenode报告,第一报告存活状态,namenode需要接收到99%的机器的心跳报告,第二上报数据块的存贮位置信息,如果发现有副本数少了,则开始进行复制工作,补齐数据块的副本数
3)然后再启动secondarynamenode
所以,当集群启动的时候必须要把上面三件事情都做完才能正常使用,那如果做不完怎么办?比如磁盘中的数据还没有完全加载到内存中,于是这个时候整个集群就处于安全模式,只要上面任何一个事情都没有做完,都将处于安全模式。
接下来谈一谈,集群处于安全模式的时候可以做哪些事情和不可以做哪些事情?
可以做的事情包括:查看,比如ls,cat,get,如果您看不懂这些命令,可以参考我的另外一篇文章
栋公子:hdfs的shell操作zhuanlan.zhihu.com
简单来说,就是查看和下载都可以操作。
不能做的事情呢,就是:创建目录,上传文件,修改文件名,追加文件内容。
其实说简单的就是:只要不修改元数据的操作都可以做,修改的一律不能做。
那么我们可以借助这个特定来做什么?那就是当我们在维护集群期间或者升级期间,我们不想要元数据修改,就手动让集群处于安全模式。以下是一些命令。
hdfs dfsadmin -safemode enter # 进入安全模式
hdfs dfsadmin -safemode leave # 离开安全模式
hdfs dfsadmin -safemode get # 获取当前是否处于安全模式,如果处于则返回on,否则返回off
hdfs dfsadmin -safemode wait #等待自行退出安全模式OK,以上就是安全模式的知识,接下来我们说下一个机制。
机架策略
要想搞清楚这个问题,我们先得知道机架。上个图吧,认识一下真实的机房里面的机架都是啥样子的。

看图说话,这就是机架。每个机架里面放置的都是一个一个的服务器,硬盘就插在上面。接下来我画个简图来说明一下他的构造。
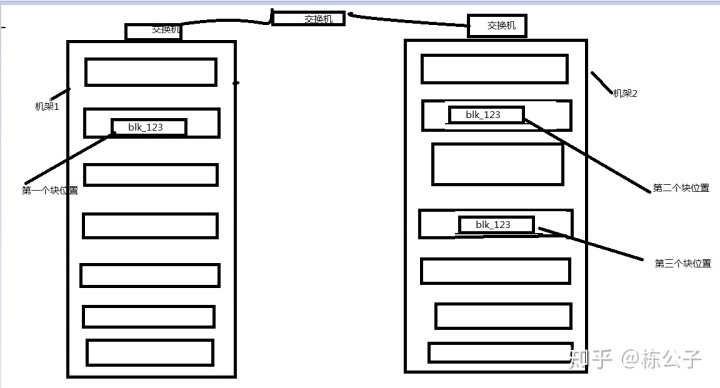
我们先来说机架构造,首先图中是两个机架,分别为机架1,机架2,那么机架内部节点直接通信靠交换机,两个机架机架之间通信也是靠一个交换机。
好,认识完机架,我们就可以具体的来说机架策略了。
如图中所示,假如我们现在上传了一个文件,他的块为blk_123,那么他第一个块存贮的位置为当前客户端连接的节点的机架上,第二个块存贮在不同机架的某个节点上,第三个块存贮在和第二个块相同机架上的不同节点上,这就是机架策略。为什么要这样子呢?
首先来说第一块,为了快速存贮,所以直接存贮客户端当前所在节点的机架上,那么第二个块就存贮在了不同机架的节点上,我们想这么一个问题,假如机架1断电了会怎么办?所以为了保证数据的安全,第二个块存贮在不同的机架上,保证了数据不易丢失。那第三个块呢?因为第三个块是从第二个块复制而来,所以也是为了快速存贮,就直接存贮在相同的机架上。
以上是在hadoop配置默认为3个副本数的时候的默认策略,真实生产环境中,可以根据自己的需要来配置的。
负载均衡
先来说一说什么是负载均衡:每个节点上数据存贮的百分比相差不大。
比如有一个3T的文件存贮在三个不同的节点上,那么每个节点就可以存贮为1T。
当然了这是理想情况下,从上面机架策略我们得知,每次第一个块的存贮位置为当前连接客户端的节点上,如果每次都连接同一个客户端,在一点程度上会造成连接的节点数据量大于其他的节点,于是这个时候,集群就会自动的启动负载均衡操作,就是把多的放到少的里面去,保证每个节点上的数据量都相差不大。
但是这个自动的负载均衡比较慢,有多慢呢?我们来看一下控制自动负载均衡的配置文件。
<property>
<name>dfs.datanode.balance.bandwidthPerSec</name>
<value>1048576</value>
<description>
Specifies the maximum amount of bandwidth that each datanode
can utilize for the balancing purpose in term of
the number of bytes per second.
</description>
</property>从图中看出为1048576字节,也就是1M。也就是带宽为1M/S,并且在集群空闲的时候运行。想一想这个速度是这么的慢啊。所以会经历一个相当长的时间。当然了,如果集群规模本身就很小,这完全没必要担心速度快慢与否。
那如果是集群大的时候呢?
我们就可以手动的进行负载均衡。命令为
start-balancer.sh -t 10% -t 10% 指得是任意两个节点之间存贮的存贮百分比不超过10%,这个值可以自行指定。
为什么我们会让他为10%,或者其他呢?因为没有绝对的负载均衡。
总结
好了,上面就是hadoop的四大机制,已经介绍完毕,如果读者看文章的时候发现错误,或者有什么想和我交流的,欢迎在下方留言,也欢迎关注本专栏,有发布新的文章会及时推送给您的。














 2129
2129











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









