






使用聚合函数汇总数据:
SQL提供统计函数:
count([shift+8]):统计表中元组个数
count([distinct]<列名>):统计本列列值个数
sum(<列名>):计算列值总和
avg(<列名>):计算列值平均值
max(<列名>):求列最大值
min(<列名>):求列最小值
●除count([shift+8])外,其他函数在计算过程中均忽略null值
●统计函数不能出现在where字句中
例:统计学生总人数
例:统计选修了课程的学生的人数
在表中,可能会包含重复值。这并不成问题,不过,有时您也许希望仅仅列出不同(distinct)的值。
关键词 DISTINCT 用于返回唯一不同的值。
例:计算学号为“123”的学生考试总成绩之和
例:计算“123”课程学生的考试平均成绩
例:查询选修了‘123’课程的最高分和最低分
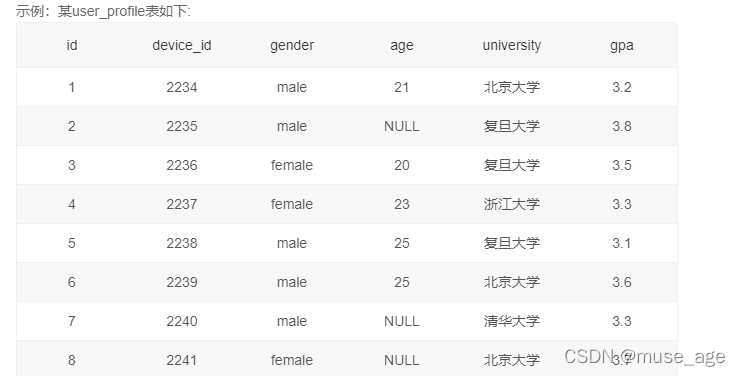
题目:运营想要知道复旦大学学生gpa最高值是多少,请你取出相应数据
题目:现在运营想要看一下男性用户有多少人以及他们的平均gpa是多少,用以辅助设计相关活动,请你取出相应数据。
分组计算:
[group by]
group by中的子句必须是表中存在的列名,不能使用AS子句指派结果列集的别名
例:统计每门课程的选课人数,列出课程号和人数
该语句首先对查询结果按课程号的值分组,所有具有相同课程号值的元组归为一组,然后再对每一组使用count函数进行计算,求出每组的学生人数
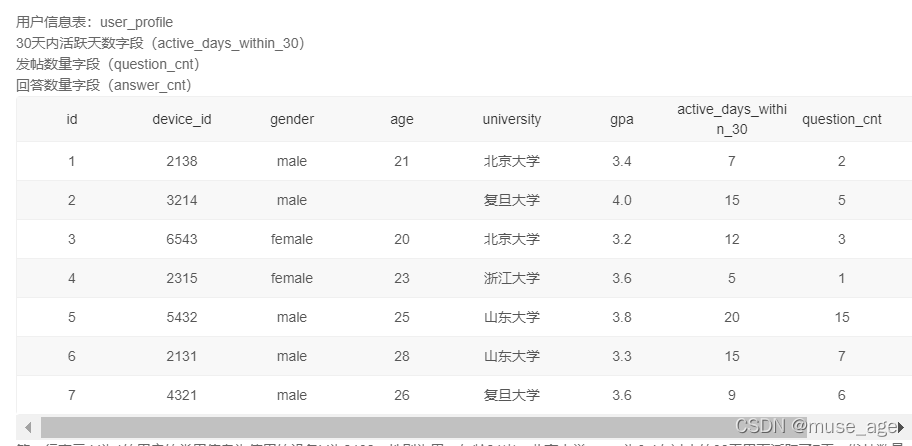
分组筛选
题目:现在运营想要对每个学校不同性别的用户活跃情况和发帖数量进行分析,请分别计算出每个学校每种性别的用户数、30天内平均活跃天数和平均发帖数量。
题目:现在运营想查看每个学校用户的平均发贴和回帖情况,寻找低活跃度学校进行重点运营,请取出平均发贴数低于5的学校或平均回帖数小于20的学校。
使用having:
having子句用于对分组后的结果再进行过滤。
它的功能与where类似,但用于组而不是单个记录
在having 子句中可以使用统计函数,但在where子句中不能
having 通常与group by子句一起使用
代码:
分组排序:
题目:现在运营想要查看不同大学的用户平均发帖情况,并期望结果按照平均发帖情况进行升序排列,请你取出相应数据。















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









