






前言
看标题就知道,这个又是个在面试中被问到的问题。这个问题其实是在我上次换工作的时候面试被问到过几次,之前也没在意过,觉得这个东西可能比较深奥,我直接说不理解吧。但是随着Java开发这个行业越来越卷,这次换工作一定要做好充足的准备。把之前落下的坑都填好,再出去受虐(面试)。
什么是分布式事务
我们都知道本地事务是有四个特性的:原子性(atomicity)、一致性(consistency)、隔离性(isolation)和持久性(durability)。
本地事务的ACID一般都是靠关系型数据库来完成的,非关系型数据库一般也可以考数据库来实现,redis这种不能回滚的弱事务除外。
但是在分布式系统中一次操作由多个服务协同完成,这种一次事务操作涉及多个系统通过网络协同完成的过程称为分布式事务。

多个服务之间的可以是同一个数据库,也可以是多个数据库。
另外如果是在同一个服务中,使用了多个数据源连接了不同的数据库,当一个事务需要操作多个数据源的时候也是属于分布式事务。
CAP
CAP理论是目前分布式系统中的处理分布式事务的理论基础。主要是在目前分布式系统中都无法同时满足如下三个属性:
- 一致性(Consistency):多个服务的数据需要保持在同一时刻的数据一致性。
- 可用性(Availability):指单个系统提供的服务需要一直保持可用状态,对于每一个请求,都能及时的响应,超时或不无响应则认为系统不可用。
- 分区容错性(Partition Tolerance):分布式系统再遇到任何网络分区故障时,仍能够保证对外提供满足一致性和可用性的服务,除非整个网络环境发生故障。
在分布式系统中。一个服务最多只能保证上面其中任何两个属性,并不能同时满足。
在保证分区容错性的时候并不能保证数据的一致性和服务的可用性。如果要提高服务的可用性,就要增加多个结点,虽然节点越多可用性越好,但是数据一致性就会越差。
这样在分布式系统设计中,同时满足“一致性”、“可用性”和“分区容错性”几乎是不可能的。
CAP应用组合
- 【CA】放弃分区容错性:放弃分区容错性,也要保证网络可用,最简单的做法就是将所有数据都放在同一个节点上,虽然这样无法保证100%系统不出错,但至少不会出现由于网络分区带来的负面影响。
- 【CP】放弃可用性:放弃可用性,是指一但遇到网络分区或其他系统问题时,那受到影响的服务需要等待一定时间,应用等待期间系统无法对外提供正常服务。即短时间内不可用。
- 【AP】放弃一致性:所谓的放弃一致性,其实并不是完全的不需要一致性,而是放弃强一致性,保证了数据最终一致性。
BASE理论
在分布式系统中,往往追求的是可比性,一般重要程度比一致性高。所以就又出现了另一个理论,就是BASE理论,是对CAP理论的一个扩充。
- Base Availability(基本可用);
- Soft state(软状态);
- Eventually consistent(最终一致性);
BASE理论是对CAP理论中的一致性和可用性的一种权衡的结果,主要思想就是:无法做到强一致,但每个应用可以根据自身业务的特点,采用适当的方式来使系统达到最终的一致性。
分布式事务的解决方案
分布式事务的解决方案,目前市面上是有几类的方式的。
- 2PC(两阶段提交)、3PC(三阶段提交);
- TCC方案;
- 本地消息表;
- 可靠消息最终一致性方案;
- 最大努力通知方案;
2PC(两阶段提交)
两阶段提交主要是将提交事务和执行事务分为了两步。
第一阶段:事务协调器通知参与者准备提交事务,参与者准备成功之后向协调者返回成功,若有一个参与者返回的是准备不成功,那么事务执行失败。
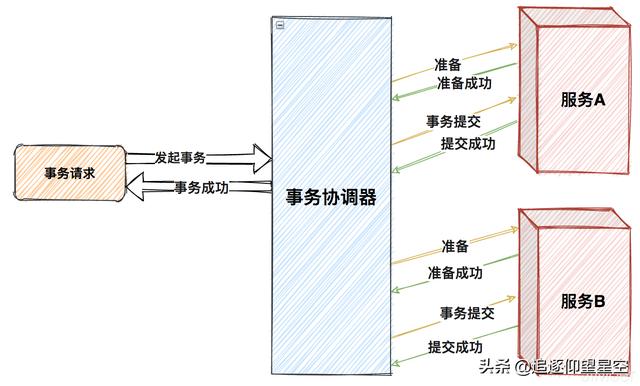
第二阶段:事务协调器根据各个参与者的第一阶段的返回结果,发起最终提交事务的请求,若有一个参与者提交失败,则所有参与者都执行回滚,事务执行失败。
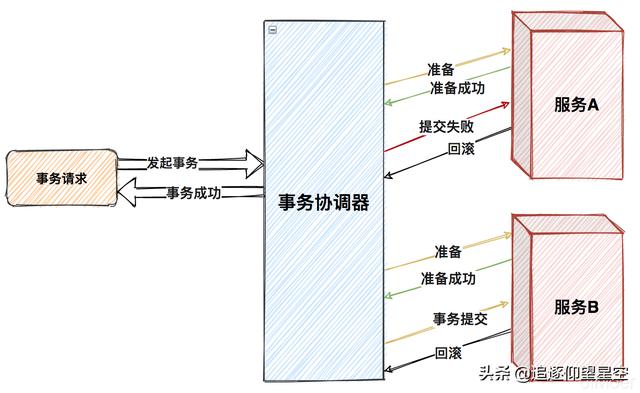
这种属于强一致性的实现,因为在多个服务间的事务执行过程中,有可能第一个服务的事务已经提交了,第二服务提交失败了,虽然说可以让第二个服务的事务回滚但是第一个服务有可能事务已经执行完成了,无法进行回滚了。所以多数情况下是将第二个服务其实是进行重试提交,然后直到重试成功为止,重试到一定次数后仍没有成功就需要预警出来人工干预了。
两阶段提交是一种尽量保证强一致性的分布式事务,因此它是同步阻塞的,而同步阻塞就导致长时间锁定资源问题,所以总体而言效率低,并且存在单点故障的问题(有可能协调者挂,也有可能协调者和其中的某个服务挂了,协调者就不清楚挂了的那个服务到底是执行没执行事务了),所以在极端情况下还是存在数据不一致的风险。
另外就是2PC其实更适合这种多数据源的情况,并且数据源都是关系型数据库。这样可以让两个数据库中的事务都同时处于prepare阶段,提交的时候两个数据库中的事务一起commit。
3PC(三阶段提交)
3PC其实就是比较2PC多了一个预提交阶段,3PC的第一阶段做的事情其实是询问参与者是否有条件执行事务,主要目的就是检查一下是否都可用。第二阶段才是和2PC的第一阶段一样呢。
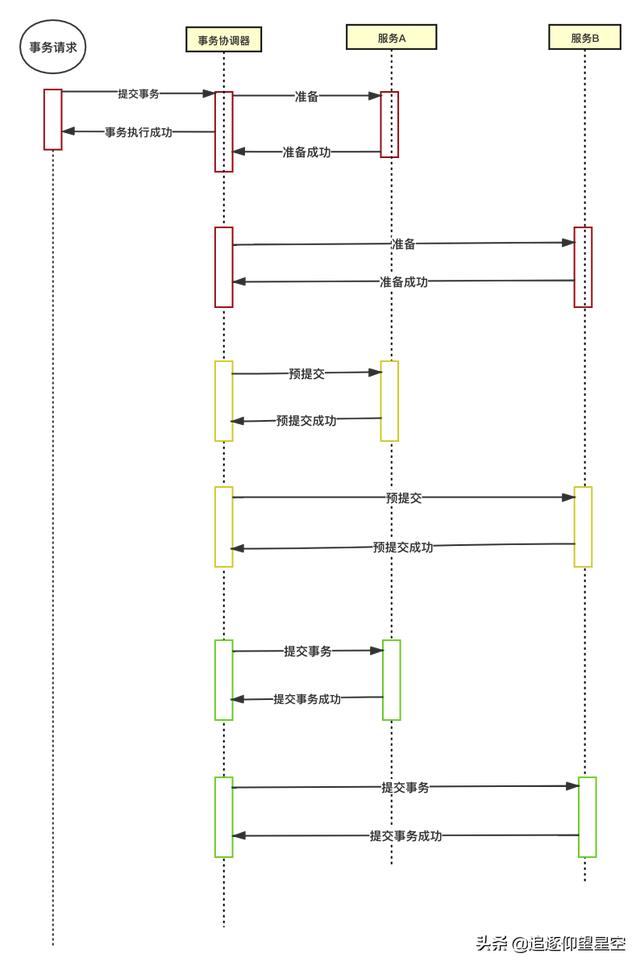
3PC出现的目的是为了解决,2PC阶段协调组和参与者都挂了之后新选举的协调者不知道当前应该提交还是应该回滚的问题。
如果新的协调者来的时候发现一个参与者处于预提交或提交阶段,代表以及过了,所有参与者的确认阶段,这样就直接提交事务就可以了。
所以说新出现的预提交阶段目的是为了让协调者知道,每个参与者目前都是什么阶段,后面该如何同步各个参与者的状态。
但是3PC还是不能保证,当协调者和某个参与者都挂了的时候,重新连接上的参与者是否已经执行了事务。
TCC
TCC和上面的两种方案对比更像是 ,分布式服务之间的事务解决方案。应用面更广一些。
TCC的全称是指:Try、Confirm、Cancel
- Try:对事务参与者的资源的锁定与预留。
- Confirm:这个阶段是在各个参与者服务中执行真正的事务操作。
- Cancel:如果任何一个服务的业务方法执行出错,那么这里就需要进行补偿,就是对已经执行的业务执行回滚操作。
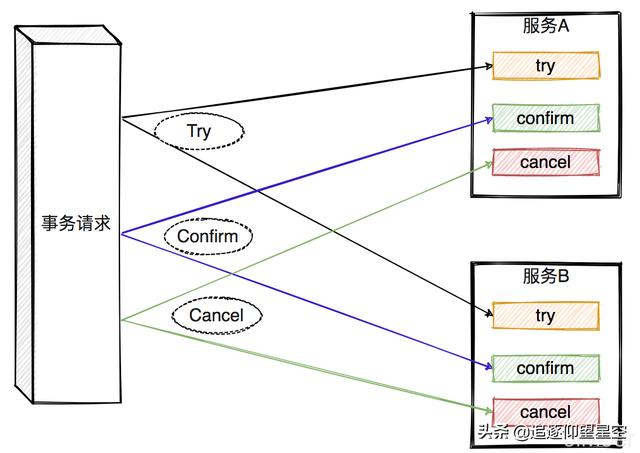
这种方式比较繁琐,每一次事务都要定义三个操作,try-confirm-cancel。而且TCC对业务的侵入性比较大,每个业务都要写相应得到撤销方法。而且如果撤销方法有不成功的情况,还有保证幂等。
但是还是有场景使用的,想一些涉及到支付、交易等这种强一致性,但又是多个服务的场景,使用TCC时比较合理的。这样能严格保证分布式事务要么都成功,要么都失败回滚。
本地消息表
本地消息表的思想主要是依靠各个服务之间的本地事务来保证的。
就是在服务的本地建立一张消息表,一般是在数据库中。当执行分布式事务的时候执行完本地操作后,在本地的消息表中插入一条数据。
然后将消息发送到MQ中,下一个服务接收到消息后执行本地操作,操作成功后更新消息表中的状态。
如果下一个服务执行失败了,那么消息表中的状态是不会变的,这样就靠定时任务去刷消息表来进行重试,但是这样需要保证被重试的服务是幂等的,这样就保证最终数据一致。
可靠消息
可靠消息实际上指的是靠消息中间件来实现分布式事务。
比如A公司的RocketMQ就用消息中间件实现了分布式事务。
例如A系统会先发一个prepared消息到MQ中,消息发送成功了,再执行本地事务,本地事务执行成功了告诉MQ事务执行成功了。否则发送回滚消息。
B系统接收到prepared消息后开始执行本地事务,事务执行成功了,也是告诉MQ发送执行成功。
MQ 会自动定时轮询所有 prepared 消息回调你的接口,问你,这个消息是不是本地事务处理失败了,所有没发送确认的消息,是继续重试还是回滚?一般来说这里你就可以查下数据库看之前本地事务是否执行,如果回滚了,那么这里也回滚吧。这个就是避免可能本地事务执行成功了,而确认消息却发送失败了。
这个时候就需要自己实现反查接口。
如果这个方案里,要是系统 B 的事务失败了咋办?重试咯,自动不断重试直到成功,如果实在是不行,要么就是针对重要的资金类业务进行回滚,比如 B 系统本地回滚后,想办法通知系统 A 也回滚;或者是发送报警由人工来手工回滚和补偿。
最大努力通知
最大努力通知,其实也算是一种最终一致性的方案。
主要是当A系统执行完本地事务后,发送消息给MQ,然后去让B系统执行事务操作,如果B系统执行完成了,就消费消息,若B系统执行失败了,则执行重试,重试多次直到成功。若达到一定次数后还没成功就只能人工干预了。
总结
可靠消息那部分是因为我没有用过RocketMQ,所以并没有认真写,因为我目前在的是腾讯系的公司所以。。。
总结一下面试的时候如果被问到这个问题怎么办,其实就是根据实际的业务场景来看,像涉及到交易,订单等这种强一致性的场景,可以使用TCC,虽然说对也侵入性大,但是最终目的是很好的保证了。
还有就是对于时效性要求不是很强的,我觉得的最大努力通知也可以的。
最后说一下我们的目前使用的方案;
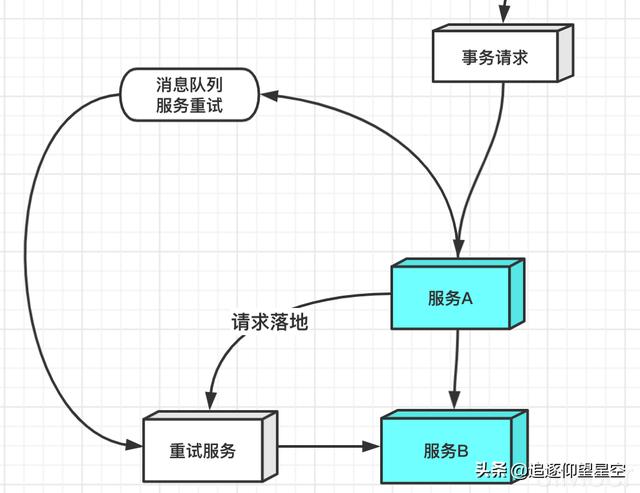
也算是最大努力通知的一种吧,当在一个web服务中,调用多个服务时,如何保证多个服务执行时数据一致性的。
当事务请求调用服务A时,如果服务A的操作执行失败了,那么直接事务执行失败。
如果执行服务A的事务成功了,但是执行服务B的事务失败了,那么我们会先将失败的请求落地(请求参数和被调用方信息入到消息表),然后将请求抛到消息队列中去进行重试,通过消息队列的ACK机制,保证我们重试消息最终可以被消费成功。
主要重试次数是3次,每次的重试的时间间隔不一样,重试三次之后如果消息还没有被ACK,那么就直接发送预警通知给开发人员,进行人工干预。
如果发送消费失败了,我们还有定时任务去定时刷我们的数据库里的消息表,来保证消息一定会被发送。
另外在真实涉及到支付,订单交易的场景时,我们主要也是使用类似TCC的方式来保证的。
说是类似是因为,我们只有CC。要么成功,要么不成功,就直接调用回撤接口进行回滚。
作者:纪莫
原文链接:https://www.cnblogs.com/jimoer/p/14164364.html














 1722
1722











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









