






栈:如何实现浏览器的前进和后退功能
前进后退实现原理
当你依次访问完一串页面 a-b-c 之后,点击浏览器的后退按钮,就可以查看之前浏览过的页面 b 和 a。当你后退到页面 a,点击前进按钮,就可以重新查看页面 b 和 c。但是,如果你后退到页面 b 后,点击了新的页面 d,那就无法再通过前进、后退功能查看页面 c 了。
我们使用两个栈,X 和 Y,我们把首次浏览的页面依次压入栈 X,当点击后退按钮时,再依次从栈 X 中出栈,并将出栈的数据依次放入栈 Y。当我们点击前进按钮时,我们依次从栈 Y 中取出数据,放入栈 X 中。当栈 X 中没有数据时,那就说明没有页面可以继续后退浏览了。当栈 Y 中没有数据,那就说明没有页面可以点击前进按钮浏览了。
比如你顺序查看了 a,b,c 三个页面,我们就依次把 a,b,c 压入栈,这个时候,两个栈的数据就是这个样子:
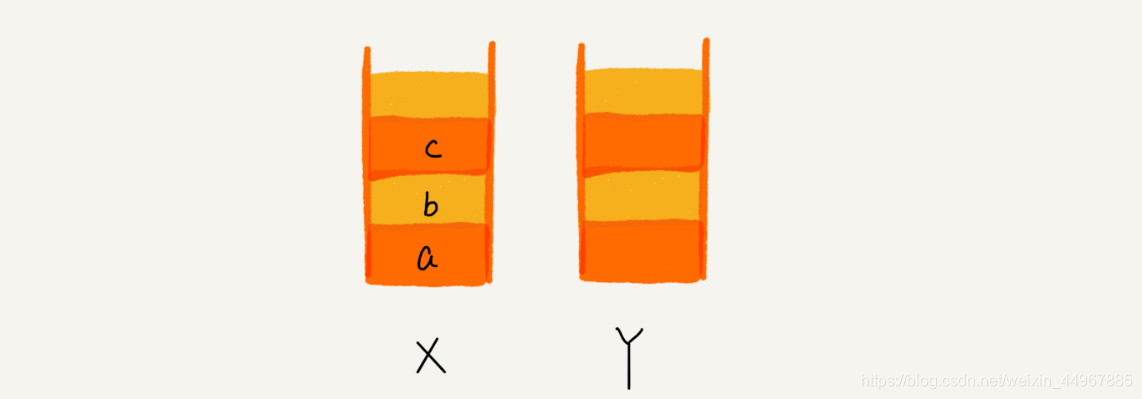
当你通过浏览器的后退按钮,从页面 c 后退到页面 a 之后,我们就依次把 c 和 b 从栈 X 中弹出,并且依次放入到栈 Y。这个时候,两个栈的数据就是这个样子:
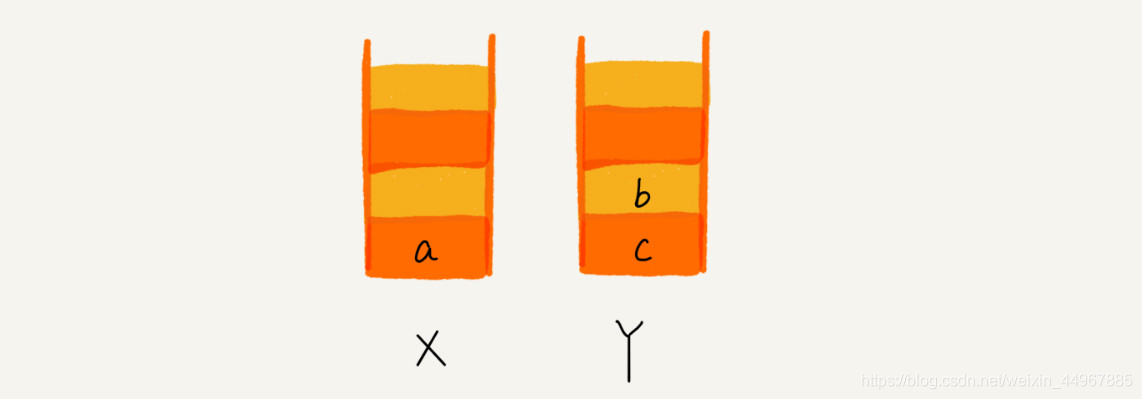
这个时候你又想看页面 b,于是你又点击前进按钮回到 b 页面,我们就把 b 再从栈 Y 中出栈,放入栈 X 中。此时两个栈的数据是这个样子:
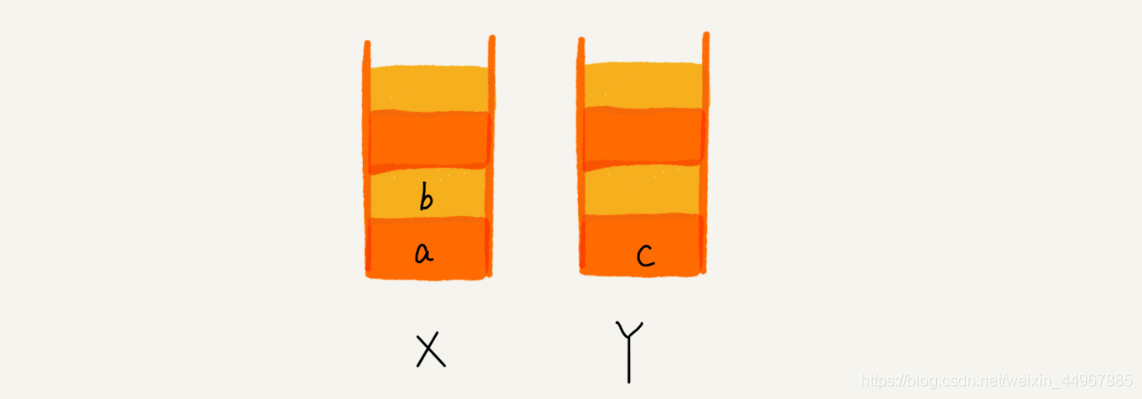
这个时候,你通过页面 b 又跳转到新的页面 d 了,页面 c 就无法再通过前进、后退按钮重复查看了,所以需要清空栈 Y。此时两个栈的数据这个样子:
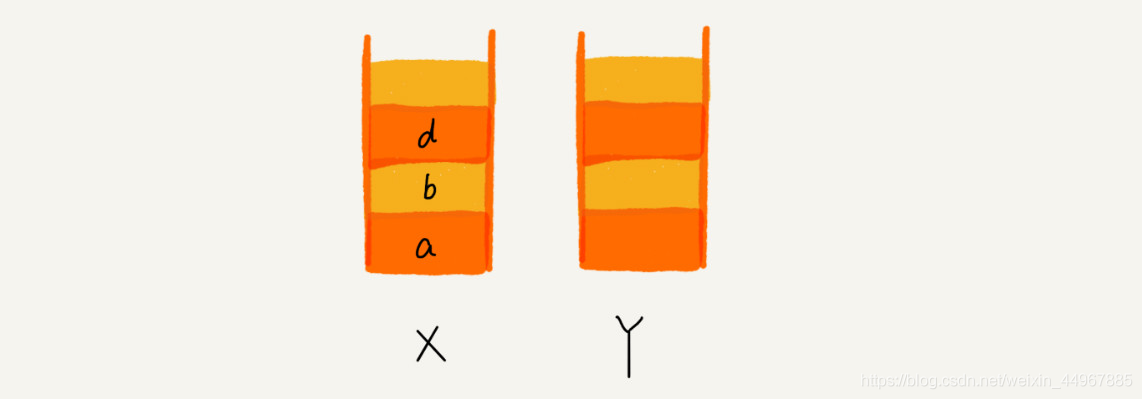
支持动态扩容的顺序栈
栈既可以用数组来实现,也可以用链表来实现。用数组实现的栈,我们叫作顺序栈,用链表实现的栈,我们叫作链式栈。
链式栈的大小不受限,支持动态扩容,但要存储 next 指针,内存消耗相对较多。因此,我们可以基于数组实现一个可以支持动态扩容的栈。
所以,如果要实现一个支持动态扩容的栈,我们只需要底层依赖一个支持动态扩容的数组就可以了。当栈满了之后,我们就申请一个更大的数组,将原来的数据搬移到新数组中。
现在我就带你分析一下支持动态扩容的顺序栈的入栈、出栈操作的时间复杂度。
对于出栈操作来说,我们不会涉及内存的重新申请和数据的搬移,所以出栈的时间复杂度仍然是 O(1)。但是,对于入栈操作来说,情况就不一样了。当栈中有空闲空间时,入栈操作的时间复杂度为 O(1)。但当空间不够时,就需要重新申请内存和数据搬移,所以时间复杂度就变成了 O(n)。
也就是说,对于入栈操作来说,最好情况时间复杂度是 O(1),最坏情况时间复杂度是 O(n)。这个入栈操作的平均情况时间复杂度可以用摊还分析法来分析。
为了分析的方便,我们需要事先做一些假设和定义:
栈空间不够时,我们重新申请一个是原来大小两倍的数组
为了简化分析,假设只有入栈操作没有出栈操作
定义不涉及内存搬移的入栈操作为 simple-push 操作,时间复杂度为 O(1)
如果当前栈大小为 K,并且已满,当再有新的数据要入栈时,就需要重新申请 2 倍大小的内存,并且做 K 个数据的搬移操作,然后再入栈。
这 K 次入栈操作,总共涉及了 K 个数据的搬移,以及 K 次 simple-push 操作。将 K 个数据搬移均摊到 K 次入栈操作,那每个入栈操作只需要一个数据搬移和一个 simple-push 操作。以此类推,入栈操作的均摊时间复杂度就为 O(1)。
栈在函数调用中的应用
操作系统给每个线程分配了一块独立的内存空间,这块内存被组织成“栈”这种结构, 用来存储函数调用时的临时变量。每进入一个函数,就会将临时变量作为一个栈帧入栈,当被调用函数执行完成,返回之后,将这个函数对应的栈帧出栈。示例代码如下:
int main() {
int a = 1;
int ret = 0;
int res = 0;
ret = add(3, 5);
res = a + ret;
printf("%d", res);
reuturn 0;
}
int add(int x, int y) {
int sum = 0;
sum = x + y;
return sum;
}
从代码中我们可以看出,main() 函数调用了 add() 函数,获取计算结果,并且与临时变量 a 相加,最后打印 res 的值。为了让你清晰地看到这个过程对应的函数栈里出栈、入栈的操作。图中显示的是,在执行到 add() 函数时,函数调用栈的情况。
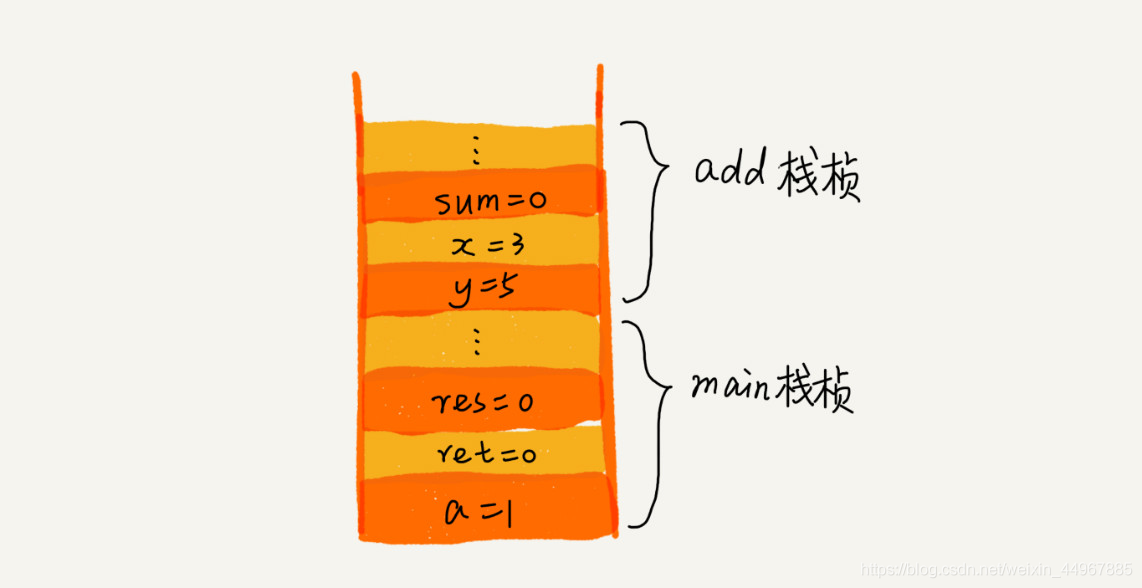
为什么函数调用要用“栈”来保存临时变量呢?用其他数据结构不行吗?
其实,我们不一定非要用栈来保存临时变量,只不过如果这个函数调用符合后进先出的特性,用栈这种数据结构来实现,是最顺理成章的选择。
从调用函数进入被调用函数,对于数据来说,变化的是什么呢?是作用域。所以根本上,只要能保证每进入一个新的函数,都是一个新的作用域就可以。而要实现这个,用栈就非常方便。在进入被调用函数的时候,分配一段栈空间给这个函数的变量,在函数结束的时候,将栈顶复位,正好回到调用函数的作用域内。
本文分享 CSDN - 墨客T。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。















 245
245











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









