






 点击上方蓝字关注我们 文末有惊喜
点击上方蓝字关注我们 文末有惊喜
什么是索引?
在mysql中,索引就是帮助mysql快速找到某条数据的一种数据结构,它是排好序的,独立于mysql表数据之外的。
索引数据结构分为哪几种
二叉树、红黑树、Hash表、B树。
在这里我们主要介绍hash表和B树
Hash表
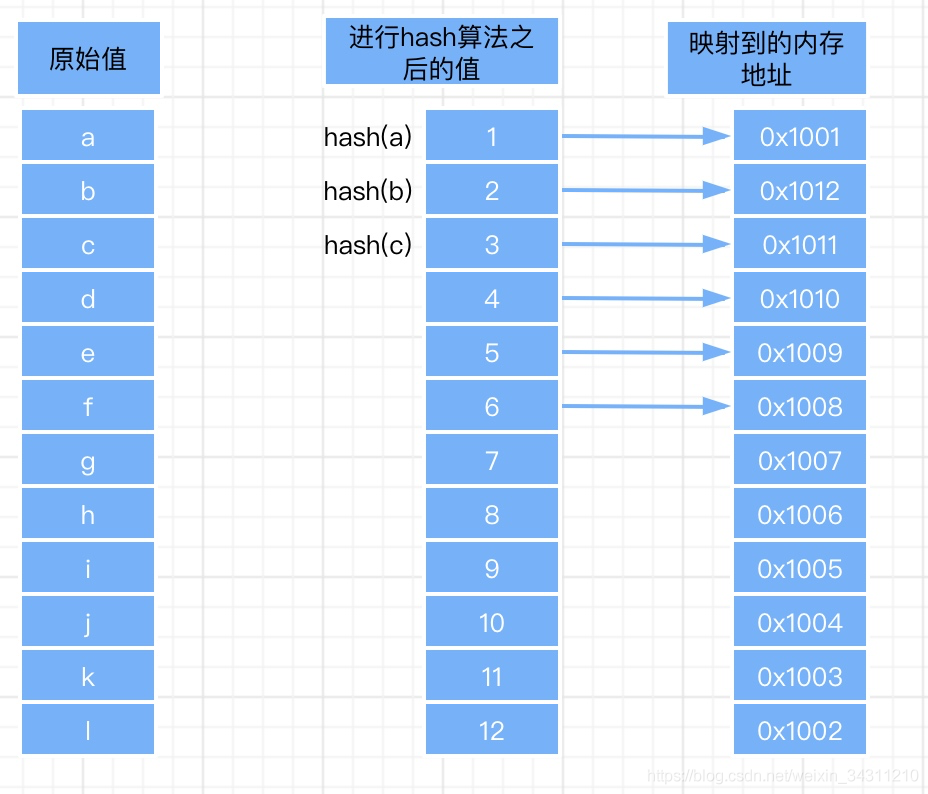
什么是hash? hash是一种散列函数,通过将输入值映射为一个数值,如:hash(100) = 1,不同的hash算法,hash之后的值有可能是不同的。Hash表是以数据映射形式存在于mysql中的,那么hash表是如何产生的呢?当添加一条数据到表中的时候,首先会对主键进行hash,然后将这条数据存在的地址和hash值建立一个映射关系,当我们根据主键查找这条数据的时候,只需要将主键进行hash,得到hash值,最后根据hash值就可以直接定位到这条数据。所以hash算法只需要进行一次磁盘IO,查询速度是非常快的。
BTree
B树又称为多叉树,它在二叉树的基础之上,划分出来多个叉,我们看下它的数据结构图示。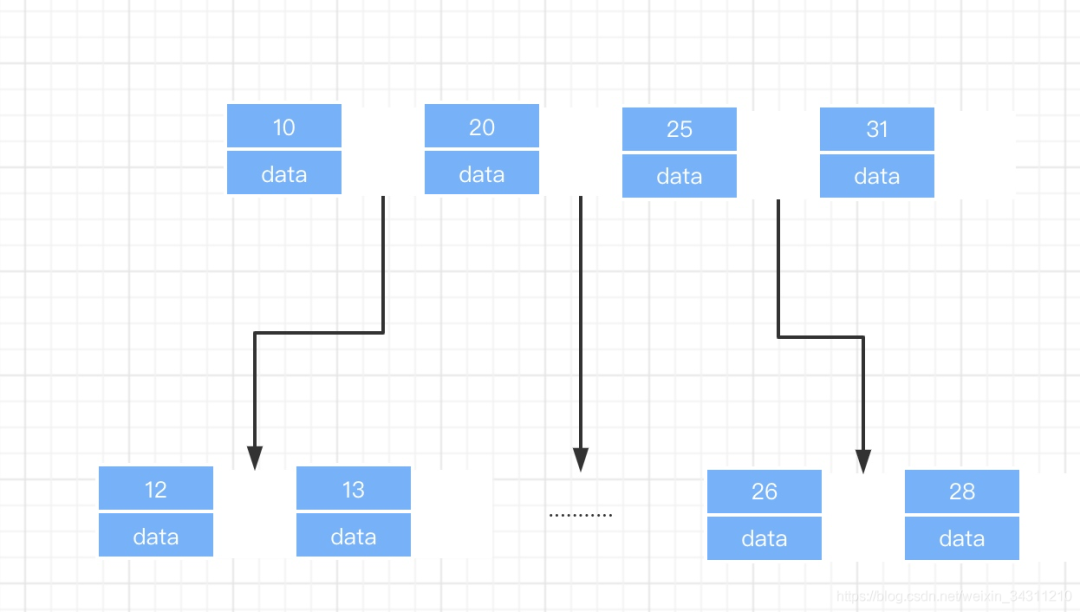
我们从图中可以看出B树具有这几种特性:1.节点从左到右递增排序 2.每个数据节点后面都会紧跟着一个指针,该指针是指向下一级的内存地址。下一级指的是位于当前指针左右两边数值中间的数据记录所存在内存中的地址。3.叶子节点 的指针为空 4.所有索引元素是不重复的。5.每个索引节点都存着当前指向的记录数据(或内存地址)
B+Tree
B+树其实是B树的一个变种,它在B树的基础之上做了一些改善,将索引节点所关联的数据记录全部移到叶子节点上了,目的是为了可以存储更多的索引节点,但是却增加了索引节点的冗余,因为叶子节点包含了所有的索引节点。
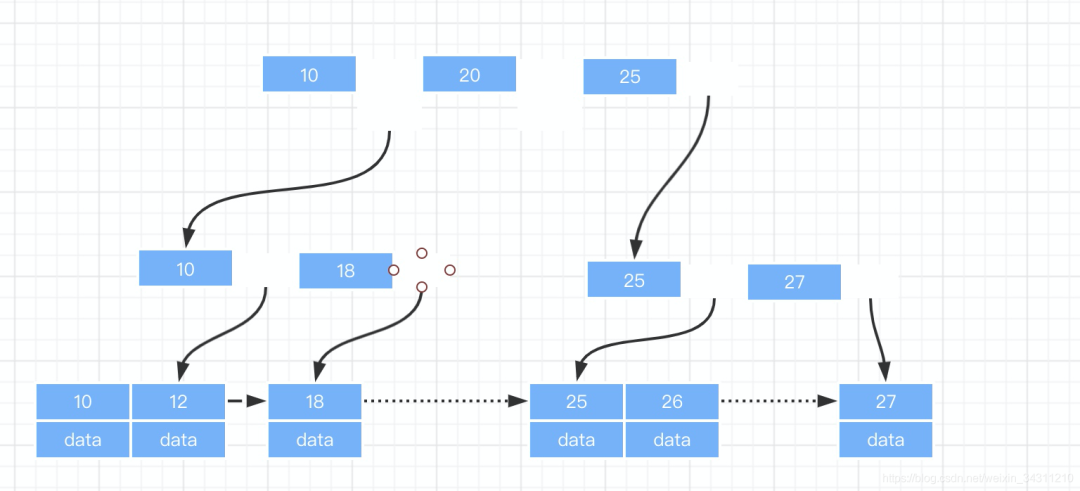
从图中可以看出,B+树具有以下几个特性:1.叶子节点包含所有的索引节点 2.非叶子节点不存储数据记录 3.叶子节点之间使用指针连接,提高区间访问的便利 4.指针所指向的索引节点的最左边都是大于等于指针所在深度左边的值
mysql的b+ tree优化了什么?
我们看下mysql中的B+树长什么样子的
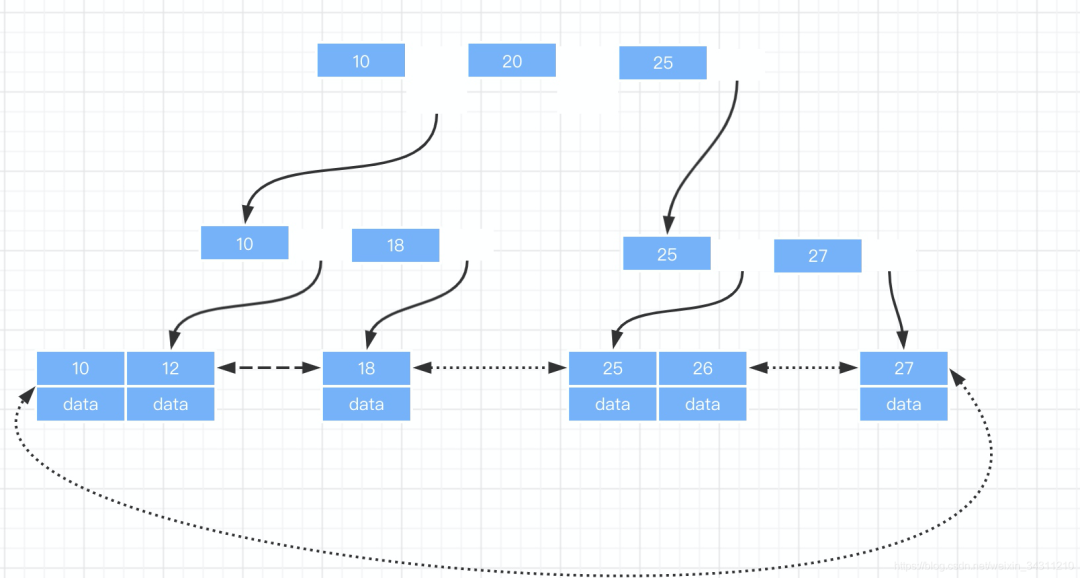
1.增加了一个双向的指针 2.首尾节点也通过指针进行关联起来 主要目的是为了更加友好的支持索引内部的范围查找。如果不加双向链表指针,我们每次查找的时候,都要回到根节点查找,增加了磁盘IO,增加查询时间。
如何计算 B+ tree最大支持数据量
在mysql中,可以使用SHOW GLOBAL STATUS LIKE 'Innodb_page_size%'指令查找到mysql对索引节点页面大小的设置,这个参数的大小决定了我们一次性能够从磁盘盘中load出多少索引数量。在5.7版本中Innodb_page_size 默认设置为16384,也就是16k。我们现在计算下myssql中,如果存储引擎为innodb的话,大概能支撑多少量级的数据?我们按照高度为3的树进行计算:
1.按照每个bigint数据类型的字段存储,每个非叶子索引节点最多需要8B
2.再加上每个索引节点后面连接的指针,指针在innodb中设置的大小为6B
3.两者加起来总共14B,所以一级节点总共能存储 16kB/14B = 1170个索引节点
4.二级节点都是从一级节点划分出来,也就是一级节点中的每个节点又能划分出1170个,所以二级节点和一级节点总共能存储1170*1170 = 1368900个 索引节点。
5.三级节点也就是叶子节点,叶子节点存储的是主键值+记录数据,记录数据最多为1K,这个时候主键值8B可以忽略不计了,所以每个叶子节点最多能存储16k/1k = 16条记录。
6.所以Innodb引擎结构的表中最多能支撑1170117016 = 21902400 条数据,大概21亿,如果大于这个值,基本上都需要进行分库分表了,mysql建议B+树的深度最好小于3.
hash算法很快,为什么mysql 很少使用hash索引?
在上面说过,hash算法,在查找数据的时候只用进行一次磁盘IO,查询速度非常快,但是为什么mysql不推荐使用呢?主要有以下几个原因
1.hash冲突(占比小,因为mysql的hash算法质量比较高,造成hash冲突的概率比较低)
2.无法进行范围查询(因为hash表里面存放的是hash值,不是数据本身,所以无法进行数据的比较,如果你确定你的表中只会用到精准查找的话,则可以使用hash结构的索引)
B tree与B+ tree区别?
1.增加了双向链表,便于范围查找.
2.只有叶子节点才存储数据记录,意味着可以存储更多的索引节点.
聚集(聚簇)索引与非聚集(聚簇)索引的区别?
聚集(聚簇)索引:索引文件与数据文件是合并在一起存放的 非聚集(聚簇)索引:索引文件与数据文件是独立存放的
innodb存储引擎实现(主键和辅助键)
主键索引:在innodb中默认使用B+ tree结构类型,存储的是聚集索引,叶子结点的data区域存储的是当前主键关联的整条记录 辅助键:辅助键的data区域存储的是主键值,也就是说如果使用辅助键索引查询,最后还得通过主键值查找对应的记录。
myisam存储引擎的索引,不管主键还是辅键索引,data区域保存的都是所关联数据的内存地址,因为myisam是非聚集索引,索引文件和数据文件是分开存储的。
为什么Innodb表必须有主键?并且推荐使用整型 并且 自增主键?
1.为什么Innodb表必须有主键?
在innodb存储引擎表中,mysql会给主键添加聚集索引,如果没有主键,mysql则会选举表中设置了唯一索引的字段设置为主键,创建主键索引;如果表中没有字段设置为唯一索引,则mysql会生成一个row_id,作为主键,创建主键索引。
2.为什么mysql推荐使用整形作为主键字段类型?
在组建B树的时候,mysql会按照从小到大的顺序进行组建,如果是整形数字的话,mysql则可以直接进行比较,如果是其它类型的话,mysql还得需要将值转换为ascill码,进行比较,会增加创建索引和查询的时间。
3.为什么要求是自增类型?
这是由mysql限制条件决定的:
1.mysql设置innodb的一次性读取到内存中的页大小设置为16384B,也就是每个节点最大为16k,
2.btree按照顺序从左往右排列;
假如现在主键不是自增的,这时候如果加入了一个新的值11,那么通过比较之后,11是需要存储在10和12之间的:
1.如果这个时候该节点已经为16k了,再加入一个数据的话,会超过mysql设置的限制,就会出现分裂,拆分成两个节点,这个操作同样会增加索引创建的时间。
2.如果按照字段设置为自增的,则不会插入比当前序号小的数据,只需要在右边继续扩充就行,不会出现节点分裂的情况。
为什么非主键索引结构叶子节点存储的是主键值 (一致性和存储空间)
1.如果存储的是具体的数据的话,会造成数据不一致的问题,因为主键索引和辅助索引会同时维护数据记录,如果有一方维护失败则会出现不一致性的问题
2.都存储具体数据的话,会造成存储空间的浪费,如果只存储主键记录的话,可以存储更多的索引记录,但是需要二次根据主键查找具体数据,以时间换空间
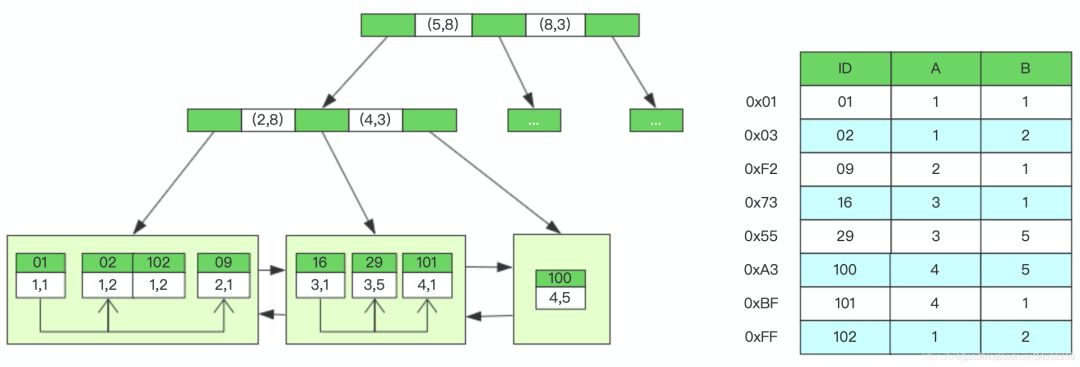
联合索引的底层存储结构
 认真读一本书
如果需要电子版,也可以关注公众号“乐哉开讲“,后台点击“干货领取“。「当然,写书不易,条件允许的话,还请支持正版。」
认真读一本书
如果需要电子版,也可以关注公众号“乐哉开讲“,后台点击“干货领取“。「当然,写书不易,条件允许的话,还请支持正版。」
作者:乐哉 图片:来源于网络,如有侵权,联系删除。
免费技术干货/经验分享

往期推荐
如何优雅的使用Redis实现分布式锁
如何快速搭建Redis集群及理解其实现原理
Redis竟然是这样做同步的,服了!
原来Redis里面的事务是这么操作的
redis为什么需要持久化?

点个赞,证明你还爱我














 1477
1477











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









