







我们都知道,自从 Kafka 诞生之际,就一直使用 Zookeeper 服务来进行 kafka 集群的元数据和状态管理,虽然在 KIP-500 中有提议未来将移除 Zookeeper 的依赖,使用 Raft 协议来实现新的元数据和状态管理,但在这之前,我们仍然需要对 kafka 集群的整个元数据和状态有一定理解,才能更好的维护和保障 kafka 集群。
前言
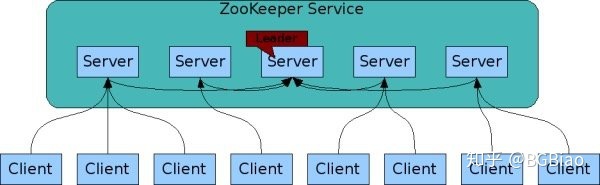
在 kafka 集群中,ZooKeeper 集群用于存放集群元数据、成员管理、Controller 选举,以及其他一些管理类任务。
存放元数据: 是指主题分区的所有数据都保存在 ZooKeeper 中,且以它保存的数据为权威,其他 “人” 都要与它保持对齐。成员管理: 是指 Broker 节点的注册、注销以及属性变更。Controller 选举: 是指选举集群 Controller,而其他管理类任务包括但不限于主题删除、参数配置。
Zookeeper 服务
在开始之前,我们首先需要对 Zookeeper 服务有一定的了解。在官方文档中,Zookeeper 有如下能力:
- 配置管理:其实就是单纯的 K/V 存储,可以用来配置的存储和管理,实现对分布式系统组件的集中式的配置管理
- 命名:命令空间管理,在 zookeeper 中配置可通过不同的根路径来实现简单的命名空间隔离 (简单的 chroot 隔离)
- 分布式的同步服务:可保证分布式的同步
- 分组服务:可以将一组服务配置进行分组管理,其实在 Dubbo 的注册中心中,就是使用分组和命名来统一进行生产者的注册和发现
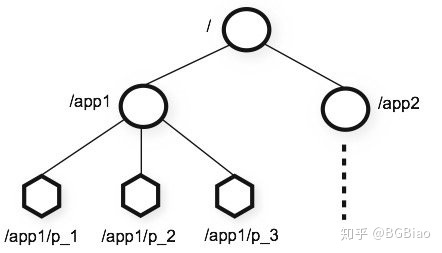
在 Zookeeper 中所有的命名空间和文件系统比较类似,每个节点都有一个唯一的路径,如下图:
为什么 Zookeeper 服务可以满足配置管理和协调服务呢?主要是因为它的节点属性,通常也是经常可能会忽略的问题,即在 Zookeeper 中存在两种节点: 持久节点和临时节点,节点也称之为 znode,而 znode 本身除了数据之外,还会存储一些额外的信息:
- 数据变更的版本号
- ACL 变更的版本号
- 时间戳
每次 znode 中的数据有变更,版本号都会递增,并且 client 在向 znode 获取数据时&#x
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 762
762











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









