







背景
- 目前机器学习平台后端采用k8s架构进行GPU和CPU资源的调度和容器编排。k8s的核心能力是容器编排,容器服务的稳定运行直接关系到整体平台的稳定性。
- 春节值班期间,机器学习平台实验环境-隔离环境 vgpu资源出现比较多的用户容器异常退出问题。此问题导致Pod中的用户容器发生重建,一些用户在容器运行时环境的数据会丢失,由于平台具有暂存用户异常容器现场的能力,值班同学可以通过恢复用户异常容器现场来恢复用户的数据。
- 用户容器异常退出,虽然可以通过运维工具来恢复用户的数据进行问题降级处理,但是频繁无故的用户容器异常退出,环境重启问题,极大的影响了用户使用 机器学习平台实验环境-隔离环境 vgpu资源的体验和值班同学处理类似问题的时效性。
问题记录-之看现象
- 【看现场】
- 版本信息
root@gpu-ser-xyz:~$ kubelet --version
Kubernetes v1.14-mlpe-20200225
root@gpu-ser-xyz:~$ docker version
Client:
Version: 18.09.2
API version: 1.39
Go version: go1.10.6
Git commit: 6247962
Built: Sun Feb 10 04:13:27 2019
OS/Arch: linux/amd64
Experimental: false
Server: Docker Engine - Community
Engine:
Version: 18.09.2
API version: 1.39 (minimum version 1.12)
Go version: go1.10.6
Git commit: 6247962
Built: Sun Feb 10 03:47:25 2019
OS/Arch: linux/amd64
Experimental: false
root@gpu-ser-xyz:~$ ctr --address /var/run/docker/containerd/containerd.sock version
Client:
Version: 1.2.2
Revision: 9754871865f7fe2f4e74d43e2fc7ccd237edcbce
Server:
Version: 1.2.2
Revision: 9754871865f7fe2f4e74d43e2fc7ccd237edcbce
root@gpu-ser-xyz:~$ containerd -v
containerd github.com/containerd/containerd 1.2.2 9754871865f7fe2f4e74d43e2fc7ccd237edcbce
root@gpu-ser-xyz:~$ runc -v
runc version 1.0.0-rc6+dev
commit: 09c8266bf2fcf9519a651b04ae54c967b9ab86ec
spec: 1.0.1-dev
root@gpu-ser-xyz:~$ nvidia-container-runtime -v
runc version 1.0.0-rc6+dev
commit: 6635b4f0c6af3810594d2770f662f34ddc15b40d-dirty
spec: 1.0.1-dev-
- 表格中记录了2020-01-14到2020-02-04期间一部分用户容器的kvm环境、docker、containerd、容器错误码的信息。
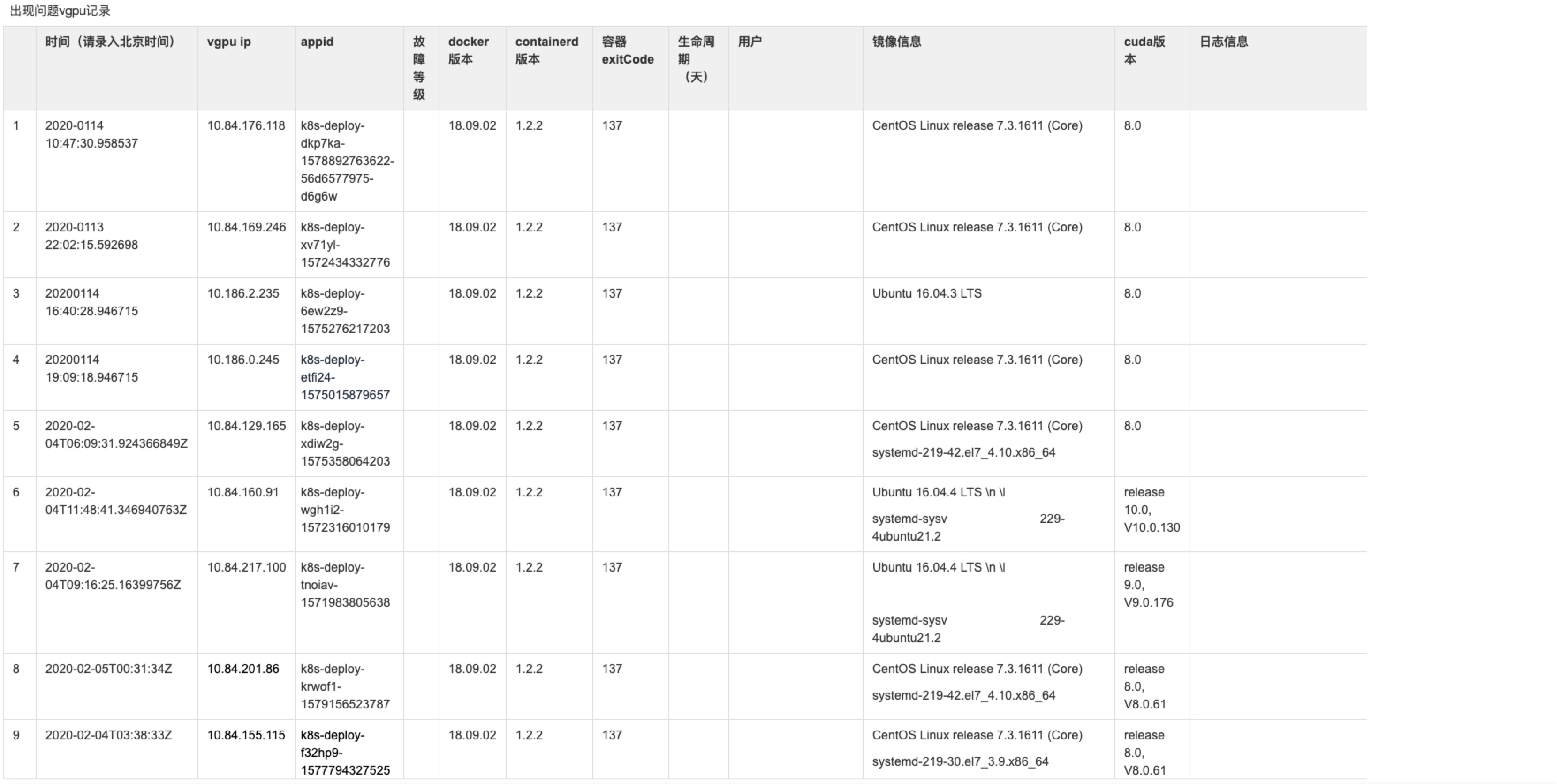
- 开始部分同学是怀疑cuda版本兼容性问题,导致用户容器异常退出,想通过升级cuda版本查看此问题是否收敛,但是cuda-10.0上也有类似现场,此怀疑不攻自破。
- 是否是由于用户容器OOM,导致异常退出,通过dmesg也没有查到任何异常日志。OOM论也被否定了。
- 相同版本的kernel、docker版本,物理GPU节点为出现用户容器重启,只有在kvm vgpu上出现,也让人摸不着头脑。
- 查看docker的日志,当用户容器异常退出时,就只有正常容器退出 clean up的信息,无其他异常日志。PS:其实此处才是澄清137问题的关键。
Feb 19 16:00:07 gpu-ser-xyz dockerd: time="2020-02-19T16:00:07.204930762+08:00" level=info msg="shim reaped" id=18b2fe723696358fb06317c427ab72777f430f074c8473612fad0fc99cbcb226
Feb 19 16:00:07 gpu-ser-xyz dockerd: time="2020-02-19T16:00:07.205071630+08:00" level=warning msg="cleaning up after killed shim" id=18b2fe723696358fb06317c427ab72777f430f074c8473612fad0fc99cbcb226 namespace=moby
Feb 19 16:00:08 gpu-ser-xyz dockerd: time="2020-02-19T16:00:08.305641212+08:00" level=info msg="ignoring event" module=libcontainerd namespace=moby topic=/tasks/delete type="*events.TaskDelete"- 【找同盟】
- 为何出现exitCode=137?
- Container exits with non-zero exit code 137 介绍了kill -9 (128 + 9) 触发的exitCode=137原因是容器stop时没有处理SIGTERM信号,进行容器优雅的退出。但是其本质还是用户容器异常退出了,不是正常stop操作。容器没有OOM,cpu、memory的监控利用率都没有超标,dmesg和messages日志中都没有异常信息,一度开始怀疑人生。
- 类似社区137问题
- Random task failures with "non-zero exit (137)" since 18.09.1 这个issue中作者从docker 18.09.0 升级到 18.09.1 (或者18.09.2)版本都会遇到137问题,也怀疑是OOM问题,但是实际应用没有出现OOM相关的日志现场。其中lwimmer把docker升级到18.09.3后未出现137问题,Ghostbaby用户把contianerd升级到1.2.5后也未出现137问题。Maintainer thaJeztah提了containerd 和runc 在18.09.2和18.09.3版本中差异。containerd/containerd@9754871...e6b3f56 opencontainers/runc@09c8266...6635b4f 结果就是升级没有出现137的问题了。
- 为何出现exitCode=137?
问题排查-之得细品
- 【升级否】
- 组内讨论了一波是否直接升级到docker 18.09.2之后的版本来解决137容器重启的问题。但是社区用户的环境毕竟和机器学习平台还是有差异,存在一些不确定性,在没有详细版本测试情况下,全量升级docker的版本,势必对用户环境稳定性有影响。而且物理GPU节点上部署同样的docker版本,并未出现此问题。保守起见,灰度了一部分节点,升级docker版本,确认是否会出现137问题。
- 事实升级了docker版本还是会出现137问题。同时并行着再灰度一些containerd的版本。PS:升级了contianerd版本的节点未出现容器137问题。

- 【抓现场】
- 从 Random task failures with "non-zero exit (137)" since 18.09.1 issue中发现了auditctl这个信号抓取的工具,可以澄清到底是哪个进程给容器发送了kill -9 信号。
# 配置捕获SIGKILL
auditctl -a always,exit -F arch=b64 -S kill,tkill,tgkill -F a1=0x9 -F key=trace_kill_9- 发现抓取到的现场确实是/usr/bin/nvidia-container-runtime把用户容器systemd进程kill了。因为GPU节点docker runtime都是使用nvidia-container-runtime。但是还是无法确认为什么被kill -9了。
time->Wed Feb 19 16:00:07 2020
type=PROCTITLE msg=audit(1582099207.232:3369619): proctitle=6E76696469612D636F6E7461696E65722D72756E74696D65002D2D726F6F74002F7661722F72756E2F646F636B65722F72756E74696D652D6E76696469612F6D6F6279002D2D6C6F672D666F726D6174006A736F6E0064656C657465002D2D666F72636500313862326665373233363936333538666230363331376334323761
type=OBJ_PID msg=audit(1582099207.232:3369619): opid=18848 oauid=-1 ouid=0 oses=-1 ocomm="systemd"
type=SYSCALL msg=audit(1582099207.232:3369619): arch=c000003e syscall=62 success=yes exit=0 a0=49a0 a1=9 a2=0 a3=0 items=0 ppid=14134 pid=23413 auid=4294967295 uid=0 gid=0 euid=0 suid=0 fsuid=0 egid=0 sgid=0 fsgid=0 tty=(none) ses=4294967295 comm="nvidia-containe" exe="/usr/bin/nvidia-container-runtime" key="trace_kill_9"- 一方面为了抓取更多的docker日志,灰度一部分节点,打开docker debug日志开关。
- 一方面为了确认是否有进程coredump的问题,把一些节点的coredump配置也打开,抓取问题现场。
- 同时review docker的代码,发现容器创建运行的一个简单基本流程是dockerd -> containerd -> containerd-shim -> nvidia-container-runtime -> entrypoint。containerd-shim托管了容器的运行时状态,当contianerd-shim 异常退出时,会调用exitHandler 中进行cleanupAfterDeadShim操作触发kill -9。
- 为了确认containerd-shim进程是异常退出,增加kill -15信号捕获。
# 配置捕获SIGTERM
auditctl -a always,exit -F arch=b64 -S kill,tkill,tgkill -F a1=0xF -F key=trace_kill_15抓取到trace信号 -9 和-15,证明containerd-shim进程确实异常退出,具体还是需要确认是什么原因导致。
time->Thu Feb 20 22:47:19 2020
type=PROCTITLE msg=audit(1582210039.403:2649702): proctitle=6E76696469612D636F6E7461696E65722D72756E74696D65002D2D726F6F74002F7661722F72756E2F646F636B65722F72756E74696D652D6E76696469612F6D6F6279002D2D6C6F672D666F726D6174006A736F6E0064656C657465002D2D666F72636500666631613337626130303962396262396562303466633861643763
type=OBJ_PID msg=audit(1582210039.403:2649702): opid=2858 oauid=-1 ouid=0 oses=-1 ocomm="systemd"
type=SYSCALL msg=audit(1582210039.403:2649702): arch=c000003e syscall=62 success=yes exit=0 a0=b2a a1=9 a2=0 a3=0 items=0 ppid=24502 pid=6558 auid=4294967295 uid=0 gid=0 euid=0 suid=0 fsuid=0 egid=0 sgid=0 fsgid=0 tty=(none) ses=4294967295 comm="nvidia-containe" exe="/usr/bin/nvidia-container-runtime" key="trace_kill_9"
time->Thu Feb 20 22:47:26 2020
type=PROCTITLE msg=audit(1582210046.181:2649752): proctitle="/usr/lib/systemd/systemd-udevd"
type=OBJ_PID msg=audit(1582210046.181:2649752): opid=6686 oauid=-1 ouid=0 oses=-1 ocomm="systemd-udevd"
type=SYSCALL msg=audit(1582210046.181:2649752): arch=c000003e syscall=62 success=yes exit=0 a0=1a1e a1=f a2=8 a3=bb8 items=0 ppid=1 pid=16425 auid=4294967295 uid=0 gid=0 euid=0 suid=0 fsuid=0 egid=0 sgid=0 fsgid=0 tty=(none) ses=4294967295 comm="systemd-udevd" exe="/usr/lib/systemd/systemd-udevd" key="trace_kill_15"
time->Thu Feb 20 22:47:42 2020
type=PROCTITLE msg=audit(1582210062.620:2649753): proctitle="/usr/sbin/init"
type=OBJ_PID msg=audit(1582210062.620:2649753): opid=7283 oauid=-1 ouid=0 oses=-1 ocomm="sshd"
type=SYSCALL msg=audit(1582210062.620:2649753): arch=c000003e syscall=62 success=yes exit=0 a0=bf a1=f a2=0 a3=ffffffc0 items=0 ppid=6661 pid=6683 auid=4294967295 uid=0 gid=0 euid=0 suid=0 fsuid=0 egid=0 sgid=0 fsgid=0 tty=(none) ses=4294967295 comm="systemd" exe="/usr/lib/systemd/systemd" key="trace_kill_15"【起死回生】
- containerd-shim 异常退出现场,看到在执行docker exec命令时,发生了panic: runtime error: invalid memory address or nil pointer dereference,显示代码访问空指针,contaienrd-shim进程异常退出,触发cleanupAfterDeadShim,导致用户容器异常退出。
Feb 25 22:07:13 gpu-ser-xyz dockerd: time="2020-02-25T22:07:13.374422177+08:00" level=debug msg="Calling POST /v1.39/containers/de42a6372c1d996efc475d294afc42f430beaad3ff443a86f124754a70a1b517/exec"
Feb 25 22:07:13 gpu-ser-xyz dockerd: time="2020-02-25T22:07:13.374608247+08:00" level=debug msg="form data: {"AttachStderr":true,"AttachStdin":true,"AttachStdout":true,"Cmd":["ip","a"],"Detach":false,"DetachKeys":"","Env":null,"Privileged":false,"Tty":false,"User":"","WorkingDir":""}"
Feb 25 22:07:13 gpu-ser-xyz dockerd: time="2020-02-25T22:07:13.376137747+08:00" level=debug msg="Calling POST /v1.39/exec/0f80962a9b908b89ea5af2f20f361e9dc10cfee6986cdc29d59e040e863427ef/start"
Feb 25 22:07:13 gpu-ser-xyz dockerd: time="2020-02-25T22:07:13.376236749+08:00" level=debug msg="form data: {"Detach":false,"Tty":false}"
Feb 25 22:07:13 gpu-ser-xyz dockerd: time="2020-02-25T22:07:13.376409211+08:00" level=debug msg="starting exec command 0f80962a9b908b89ea5af2f20f361e9dc10cfee6986cdc29d59e040e863427ef in container de42a6372c1d996efc475d294afc42f430beaad3ff443a86f124754a70a1b517"
Feb 25 22:07:13 gpu-ser-xyz dockerd: time="2020-02-25T22:07:13.377794937+08:00" level=debug msg="attach: stdin: begin"
Feb 25 22:07:13 gpu-ser-xyz dockerd: time="2020-02-25T22:07:13.377888031+08:00" level=debug msg="attach: stdout: begin"
Feb 25 22:07:13 gpu-ser-xyz dockerd: time="2020-02-25T22:07:13.377945302+08:00" level=debug msg="attach: stderr: begin"
Feb 25 22:07:13 gpu-ser-xyz dockerd: time="2020-02-25T22:07:13.378383214+08:00" level=debug msg="Closing buffered stdin pipe"
Feb 25 22:07:13 gpu-ser-xyz dockerd: time="2020-02-25T22:07:13.378459556+08:00" level=debug msg="attach: stdin: end"
Feb 25 22:07:13 gpu-ser-xyz dockerd: time="2020-02-25T22:07:13.521401882+08:00" level=debug msg="event published" ns=moby topic="/tasks/exec-started" type=containerd.events.TaskExecStarted
Feb 25 22:07:13 gpu-ser-xyz dockerd: time="2020-02-25T22:07:13.522615348+08:00" level=debug msg=event module=libcontainerd namespace=moby topic=/tasks/exec-started
Feb 25 22:07:13 gpu-ser-xyz dockerd: time="2020-02-25T22:07:13.742957161+08:00" level=debug msg="event published" ns=moby topic="/tasks/exit" type=containerd.events.TaskExit
Feb 25 22:07:13 gpu-ser-xyz dockerd: time="2020-02-25T22:07:13.744535201+08:00" level=debug msg=event module=libcontainerd namespace=moby topic=/tasks/exit
Feb 25 22:07:13 gpu-ser-xyz dockerd: time="2020-02-25T22:07:13.745009232+08:00" level=debug msg="attach: stderr: end"
Feb 25 22:07:13 gpu-ser-xyz dockerd: time="2020-02-25T22:07:13.745069071+08:00" level=debug msg="attach: stdout: end"
Feb 25 22:07:13 gpu-ser-xyz dockerd: time="2020-02-25T22:07:13.745086517+08:00" level=debug msg="attach done"
Feb 25 22:07:13 gpu-ser-xyz dockerd: time="2020-02-25T22:07:13.749102092+08:00" level=debug msg="Calling GET /v1.39/exec/0f80962a9b908b89ea5af2f20f361e9dc10cfee6986cdc29d59e040e863427ef/json"
Feb 25 22:07:13 gpu-ser-xyz dockerd: time="2020-02-25T22:07:13.793241263+08:00" level=debug msg="Calling GET /v1.38/containers/json?all=1&filters=%7B%22label%22%3A%7B%22io.kubernetes.docker.type%3Dpodsandbox%22%3Atrue%7D%7D&limit=0"
Feb 25 22:07:13 gpu-ser-xyz dockerd: time="2020-02-25T22:07:13.803366670+08:00" level=debug msg="Calling GET /v1.38/containers/json?all=1&filters=%7B%22label%22%3A%7B%22io.kubernetes.docker.type%3Dcontainer%22%3Atrue%7D%7D&limit=0"
Feb 25 22:07:13 gpu-ser-xyz systemd: Removed slice User Slice of root.
Feb 25 22:07:13 gpu-ser-xyz dockerd: panic: runtime error: invalid memory address or nil pointer dereference
Feb 25 22:07:13 gpu-ser-xyz dockerd: [signal SIGSEGV: segmentation violation code=0x1 addr=0x78 pc=0x5ff488]
Feb 25 22:07:13 gpu-ser-xyz dockerd: goroutine 5 [running]:
Feb 25 22:07:13 gpu-ser-xyz dockerd: github.com/containerd/containerd/runtime/v1/linux/proc.(*execProcess).pidv(...)
Feb 25 22:07:13 gpu-ser-xyz dockerd: /go/src/github.com/containerd/containerd/runtime/v1/linux/proc/exec.go:76
Feb 25 22:07:13 gpu-ser-xyz dockerd: github.com/containerd/containerd/runtime/v1/linux/proc.(*execStoppedState).Pid(0x8d8cf0, 0xffffffffffffffff)
Feb 25 22:07:13 gpu-ser-xyz dockerd: /go/src/github.com/containerd/containerd/runtime/v1/linux/proc/exec_state.go:175 +0x8
Feb 25 22:07:13 gpu-ser-xyz dockerd: github.com/containerd/containerd/runtime/v1/linux/proc.(*execProcess).Pid(0xc4201e0000, 0x55ec)
Feb 25 22:07:13 gpu-ser-xyz dockerd: /go/src/github.com/containerd/containerd/runtime/v1/linux/proc/exec.go:72 +0x34
Feb 25 22:07:13 gpu-ser-xyz dockerd: github.com/containerd/containerd/runtime/v1/shim.(*Service).checkProcesses(0xc42000e0c0, 0xbf8d68647291f929, 0xbec8633ef91e, 0x8bc720, 0x4308, 0x0)
Feb 25 22:07:13 gpu-ser-xyz dockerd: /go/src/github.com/containerd/containerd/runtime/v1/shim/service.go:514 +0xde
Feb 25 22:07:13 gpu-ser-xyz dockerd: github.com/containerd/containerd/runtime/v1/shim.(*Service).processExits(0xc42000e0c0)
Feb 25 22:07:13 gpu-ser-xyz dockerd: /go/src/github.com/containerd/containerd/runtime/v1/shim/service.go:492 +0xd0
Feb 25 22:07:13 gpu-ser-xyz dockerd: created by github.com/containerd/containerd/runtime/v1/shim.NewService
Feb 25 22:07:13 gpu-ser-xyz dockerd: /go/src/github.com/containerd/containerd/runtime/v1/shim/service.go:91 +0x3e9
Feb 25 22:07:13 gpu-ser-xyz dockerd: time="2020-02-25T22:07:13.874199295+08:00" level=info msg="shim reaped" id=de42a6372c1d996efc475d294afc42f430beaad3ff443a86f124754a70a1b517
Feb 25 22:07:13 gpu-ser-xyz dockerd: time="2020-02-25T22:07:13.874266470+08:00" level=warning msg="cleaning up after killed shim" id=de42a6372c1d996efc475d294afc42f430beaad3ff443a86f124754a70a1b517 namespace=moby问题分析-之论本质
- 【从代码中来到代码中去】
- 为什么在打开docker debug日志节点能抓到现场,线上其他vgpu上为什么没有出现SIGSEGV这个panic的问题。
- containerd-shim出现panic时,因为containerd启动containerd-shim进程时,stdout/stderr都没有重定向到os的stdout/stderr上,所以在messages中没有找到任何panic信息。只有debug日志打开时,containerd-shim设置了重定向,才会有panic的日志输出。
- 为什么在打开docker debug日志节点能抓到现场,线上其他vgpu上为什么没有出现SIGSEGV这个panic的问题。
if debug {
cmd.Stdout = os.Stdout
cmd.Stderr = os.Stderr
}- 为什么containerd-shim出现panic时,dmesg和/var/log/message中都没有相关segment fault的日志。
- c/c++程序遇到segment fault都会在messages有类似的日志。
segfault at 0 ip 00000000004005c7 sp 00007ffce36494f0 error 6 in main。因为containerd-shim是go程序,go的runtime catch到了SIGSEGV。当containerd-shim SIGSEGV 触发panic时,go runtime会调用runtime.crash,dieFromSignal(_SIGABRT) 实际 raise的是SIGABRT信号,所以dmesg和/var/log/message同时由于docker启动的时候,没有配置GOTRACEBACK=crash环境变量,默认是 GOTRACEBACK=single,ulimited -c 是0,也不会生成coredump文件。
- c/c++程序遇到segment fault都会在messages有类似的日志。
- 为什么容器中会有频繁的exec操作
- 平台kubelet使用内网sdn接口获取ip,没有使用cni插件的方式,当每秒执行PLEG,检查Pod状态,通过docker exec -i ip a 获取Pod IP。
- 频繁的exec操作,增加了containerd-shim触发exec bug概率。
- 问题本质是exec.go代码 访问了空指针。
Feb 25 22:07:13 gpu-ser-xyz dockerd: panic: runtime error: invalid memory address or nil pointer dereference
Feb 25 22:07:13 gpu-ser-xyz dockerd: [signal SIGSEGV: segmentation violation code=0x1 addr=0x78 pc=0x5ff488]
Feb 25 22:07:13 gpu-ser-xyz dockerd: goroutine 5 [running]:
Feb 25 22:07:13 gpu-ser-xyz dockerd: github.com/containerd/containerd/runtime/v1/linux/proc.(*execProcess).pidv(...)
Feb 25 22:07:13 gpu-ser-xyz dockerd: /go/src/github.com/containerd/containerd/runtime/v1/linux/proc/exec.go:76- 【从社区来到社区去】
- containerd社区相关的issue,在1.2.2版本上抓到了和我们类似的现场,pid原来是int类型修改成safePid,加锁线程安全了。[signal SIGSEGV: segmentation violation code=0x1 addr=0x78 pc=0x5ff488]
- Fix exec race condition pr中已经解决2969此问题,1.2.3版本上合入了这个commit:5730c5003980f2b8c6d18188b56188230353ba81
- 同时也能解释通升级到containerd 1.2.3之后的版本,容器未出现137问题
解决方案
- 【降运维】
- 在137问题根本原因未澄清前,为了减少用户容器异常退出带来的运维工作量。修改了kubelet 容器异常重启的策略,通过用户容器的标签信息,将平台实验环境vgpu的容器发生异常退出时,不在是容器重建,修改成容器重启。
- 修改平台Daemonset hostNetwork=true的方式,不在使用sdn网络,减少exec操作。
- 【开处方】
- 问题本质原因是containerd execde bug,后续增量环境containerd升级至1.2.4版本。
- 去除kubelet sdn网络exec获取容器IP的方式。
- 使用平台自研的sdn cni网络插件,目前正在研发中。
参考文档
- Container exits with non-zero exit code 137
- STOPSIGNAL--与信号转发
- Random task failures with "non-zero exit (137)" since 18.09.1
- [signal SIGSEGV: segmentation violation code=0x1 addr=0x78 pc=0x5ff488]
作者:童超【滴滴出行资深软件开发工程师】
- 现在注册滴滴云,得8888元立减红包
- 7月特惠,1C2G1M云服务器 9.9元/月限时抢
- 滴滴云使者专属特惠,云服务器低至68元/年
- 输入大师码【7886】,GPU全线产品9折优惠















 904
904











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









