






一、组函数
组函数,也叫聚合函数。用来对一组值进行运算,并返回单个值。
COUNT(*|列名) 统计行数
AVG(数值类型列名) 平均值
SUM(数值类型列名) 求和
MAX(列名) 最大值
MIN(列名) 最小值
组函数都会忽略null值
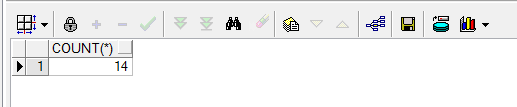
select count(*) from emp;
二、分组查询
-- group by 进行分组
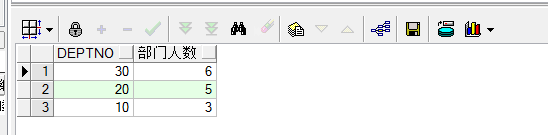
-- 例,按部门进行分组,并统计部门的人数
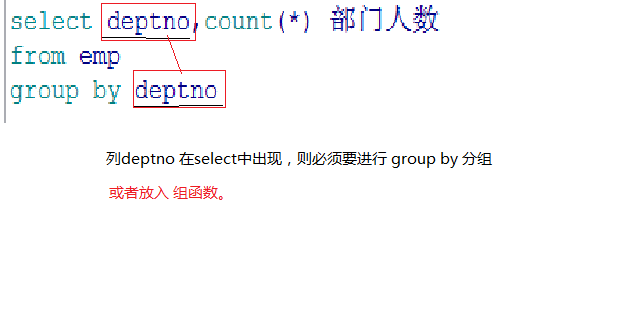
select deptno,count(*) 部门人数
from emp
group by deptno
注意:使用group by 分组函数
1. 出现在 select 后的列,必须要进分组
2. group by 字句的字段可以不出现在 select 列表之中
3.当不使用group by时,即所有的查询结果作为一组
限定组的结果:使用 having 子句
where 和having都是用于条件过滤
where在分组函数之前,不可以使用组函数
having在分组函数之后,可以使用组函数
三、子查询
1. 查询ALLEN的工资
select sal from scott.emp where ename = 'ALLEN';
2. 查询比ALLEN工资高的员工
select * from scott.emp where sal > 1600;
3. 以上一句可以写成子查询
-- 子查询就是把多条语句写成一条,子查询执行的时候会先执行子查询再执行主查询
select * from scott.emp where sal >
(select sal from scott.emp where ename = 'ALLEN');
4. 多行比较运算符:
- in:与列表中的任一个值相等
- any:与子查询返回的每一个值比较,大于最小的,小于最大的
- all:与子查询返回的所有值比较,大于最大的值,小于最小的值
四、RowNum 和 Rowid
RowNum 和Rowid,只有Oracle数据库才有。
rownum 伪行
select rownum, deptno, dname, loc from scott.dept
where rownum = 1;--查到1条数据
注意:
rownum 是在得到结果集的时候产生的,用于标记结果集中结果顺序的一个字段,
这个字段被称为“伪数列”,也就是事实上不存在的一个数列。
它的特点是按“顺序标记”,而且是“逐次递加”的,
换句话说就是只有存在 rownum = 1 的记录,才可能存在rownum = 2的记录。
-- 查询emp中第5-10条记录
select tempid, empno, ename
from (select rownum as tempid,empno ,ename from scott.emp ) t
where t.tempid between 6 and 10;














 1510
1510











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









