






首先先要再次强调一个概念:系统调优的目的不是怎样去吧那一部分做的特别优化。而是整体的全局的考虑。性能优化是为了找到系统的瓶颈并且想办法提高瓶颈最好能够去除。(个人认为万事皆有利弊,在计算机的世界里同样如此所以完美是不现实的。。) 调优的终极目标是为了让计算机个各个子系统达到一种平衡状态。。 子系统:cpu memory Io network 此处不多赘述。。
下来首先来解决io的优化,其实这个优化就是由内核控制选择一种相对较好的io策略对应您的实际环境。
下面给出我们IO调度在系统调用中的位置:
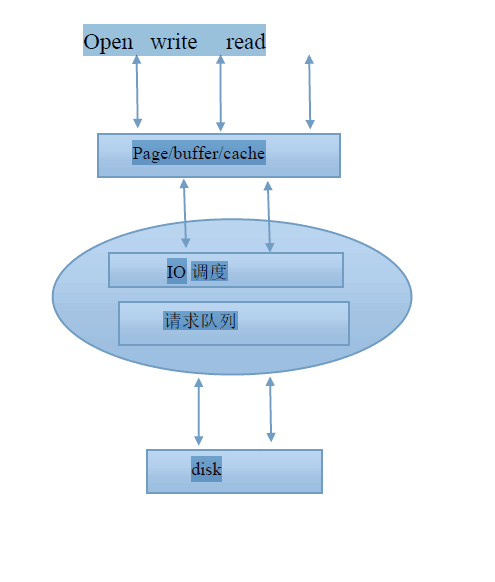
下面详细介绍系统IO调度算法
设备写入或者读取数据快的请求都在队列中等待完成,每个块设备都有自己的队列,
内核会先确认该队列的请求数量,在进行调度。IO调度器的目标:让总往一个方向移动,移动到底再往反向走,类似现实生活中的电梯elevator
cfq完全公平队列,deadline和 AS的折中,原理类似cpu时间分片。。为每个进程/线程单独创建一个队列来管理 该进程所产生的请求,每个进程一个队列,各个队列之间时间片调度,保证每个进程很好的分配到IO带宽,IO调度棋每次执行一个进程的额4次请求。
noop电梯调度。 FIFO队列,有新请求到来时,把新的请求合并到最近的请求之后,保证同一介质,利于写不利于读,写可以通过文件系统cache不需要等待下一次就可完成,然后请求合并。读要等到前面完了才可以读取,此时写在这之前到来,会导致以后没法正确读取,适用于闪存设备,ram嵌入式系统
deadline截止时间调度,通过时间和硬盘区域分类,适用于数据库,确保集诶将诶之时间内的服务请求,截止时间可以调整,默认读期限小于写,保证写的顺利进行,不因不能读饿死
anticipatory:可查觉,预先决定,每次读操作会稍等一会,看看是否有人想读附近的数据,适合于大量的顺序读操作,kernel 2.6.33 已经去掉,可以修改cfq 算法来实现其功能。、、
查看调度算法命令
[#2#dty@localhost ~]$cat /sys/block/sda/queue/scheduler
noop deadline [cfq]
更改命令:echo noop > /sys/block/sda/queue/scheduler
Io通过实际情况选择相应的调度算法就可以
下来是cpu的 优化,
多数监控工具关于cpu的分类有以下几个
usertime 用户进程时间,userspace中被执行进程在cpu开销时间比。
systemtime 内核中线程和中断在icpu开销时间百分比
wait io io请求等待时间,所有进程线程数阻塞等待完成。
idle 空闲 。。 一个完整空闲进程在cpu开销时间百分比
我们可以通过各种监控工具实时检测cpu的状态
cpu的调度策略,这里不做赘述,计算机基本知识,时间分片优先级处理~~~~内核使用调度算法控制
sched_RR :轮询进行
sched_FIFO :一直运行,直到发生IO等待自己让出cpu,或被更高优先级顶掉
SCHED_NORMAL 普通应用使用,标准轮询
SCHED_NATCH 大量操作不打断,更好的利用缓存。
SCHED_IDLE 为低优先级应用使用,比nice值19的优先级还要低
使用实时调度的方法,
1.编程时使用sched_setcheduler 函数
2.chrt -f 命令FIFO
chrt -r 命令 轮询rr
nice -n 优先级 命令 。。指定优先级并运行命令。
cpu的优化涉及到了cpu缓存
首先简要介绍cpu缓存的级别:
一级缓存,分为指令缓存和数据缓存,有静态内存实现。
每一个位是6个晶体管制造的,动态内存1个位1个晶体管,6个可以保持点亮,1个不能,所以需要电流不停的刷,这就是内存速度比 缓存速度慢的原因。
二级缓存,cpu内 cpu核心私有或者cpu核心之间共存
三级缓存,主板上cpu核心间
四级缓存,物理cpu之间(即多个cpu)
工作过程:当cpu去内存去数据的时候,缓存控制器首先检查数据是否在缓存中,在就缓存命中cache-hit。不在cache-miss。并且从内存*(或者下一极缓存)中读取数据到缓存中,叫做缓存行填充。
每个cpu有自己独立的缓存控制器,cpu核心读取数据时,会在共享缓存中查看是否其他核心已将数据读到缓存中。它查看的方式有两种,snopping速度快,不扩展(广播) directory based 速度慢可扩展。
cpu保证cache 和memory一致的方法
write through :cpu向cache写入数据时,同时向memory也写一份,使cache和memory保持一致,缺点是每次访问memory速度慢。。。
write back :cpu更新cache时,把更新的cache区标记一下,不同步更新。。 如果cache区要被更新数据取代则在更新memory。。这样做考虑到很多时候的cache数据是中间数据,减少了没必要的同步更新,优点效率高,缺点,断电数据会部分丢失。。
\
cpu资源限制 编辑 /etc/security/limits.conf 或者使用 cgroup
未完待续。。。















 3170
3170











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









