








背景:ZynqNet能在xilinx的FPGA上实现deep compression。
目的:读懂zynqNet的代码和论文。
目录
1.4 FPGA based accelerator需要执行:
FPGA-realted optimization(3.4.2)
Xilinx Software Development Kit
Memory-Mapped Input and Output
一、网络所需的运算与存储
1.1 运算操作:
- macc:multiply-accumulation,
- comp:comparison
- add: addition/substraction
- div: division
- exp: expontential
1.2 Memory requirements:
- activation: size of output feature maps
- param: number of weight parameters
1.3 需求分析:
- 网络为1×1和3×3的卷积,所以将近530 million次MACC操作。
- ReLU操作耗费将近3 million次comp操作。
- 均值池化需要66000 次加法和一次除法,
- 最终的softmax需要执行1024次exponentiation,add和div。
- exponentiation与division很少,所以softmax层被ARM处理器执行。
1.4 FPGA based accelerator需要执行:
- conv layer:
- kernel 1×1,padding 0
- kernel 3×3,padding 1
- stride 1 or stride 2
- ReLU nonlineralrties
- concatenation
- global average pooling
二、网络结构
针对网络结构进行了三种优化:
- efficiency-related optimization (report 3.4.1)
- FPGA-related optimization(report 3.4.2)
- accuracy-related optimization(report 3.4.3)
FPGA-realted optimization(3.4.2)
- 2的次方数的维度:能减少14%的参数和9%的MACC操作。
- 全卷积网络:只包含卷积和非线性的网络。我们将最大值池化改为步长为2的subsequent conv.
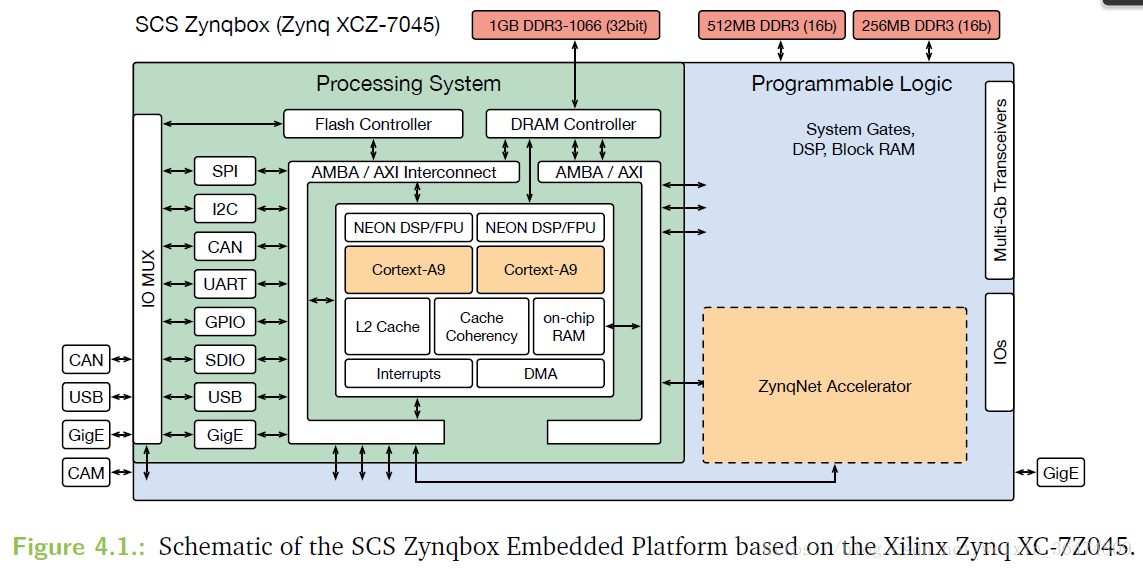
- Layer splitting:因为on-chip memory的不足,xc-7z045只有2180kB个Block RAM memory,只能存储560 000 个32bit 浮点参数。conv10被分为conv10/split1与conv10/split2
循环嵌套:
循环嵌套顺序layer——height——width——input channel——output channel——kernel elements


三、编译优化
并行处理(4.2.3)
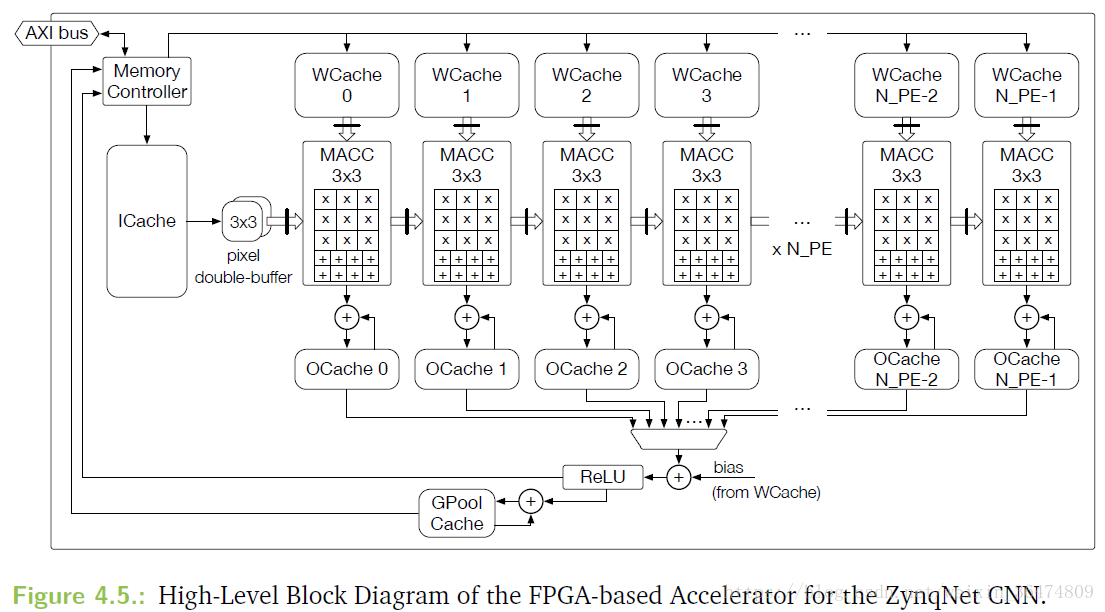
并行策略,将所有3×3的循环展开(fullly unroll),unroll the output channels co by 参数N(PE)
数据复用(4.2.4)
四种on-chip cache
- ICache(Image cache):line buffer,为input feature map准备的。
- OCache(Output cache)
- GPoolCache(Global pooling cache)
- WCache(weights cache):最大的cache,需要当前layer的ci×co个filter
每一个输入像素都被加载一次,输出像素也被加载一次,权重也被取一次。相比于main memory access,这种算法的数据复用较为理想。
Coding Style(4.4.2)
object-orinted
最初整体的进行编程与调试,HLS报错,作者并不知道错误在哪里。因此作者使用object-orinted的方法。
- hardware block modules被作为class instances,包括MemoryController, ImageCache, WeightsCache, OutputCache, ProcessingElements
- 数组与变量被封装为private class members
- 数据搬运被实现在高级别的函数中。
- 控制依然在top-level的嵌套的函数中(layer,height,width,inputchannels)和class ProcessingElement(output channel与kernel y与x)
这种编码模式在综合之中就更容易查找问题。但是因为编译等等的问题,作者依然不能调通。
Block-structured(ZynqNet采用的)
这种方法运用namespace来确定相应的代码,部分被运用下面的方法:
- namespace to structure code into modules
- 数组与变量被封装于namespace-scopes中
- 数据搬运通过high-level namespace-scoped 函数来进行
- 控制依然通过top-level的嵌套的函数中(layer,height,width,inputchannels)和namespace ProcessingElement(output channel与kernel y与x)
最终的代码优点:
- 直接,接近硬件描述
- 易于阅读,更改和调试
- 易于运用优化指令
Compiler Directives(4.4.3)
具体的硬件实现需要对相应的c/c++代码进行编译指令。
包括了Interfaces, function-level interface protocols, port-level interface protocols, AXI4 interfaces, AXI4 Depth Settings。
Data and control flow
涉及每个指令的优化的意义与硬件相关讲解。
Loop Unroll, Dependencies,Pipeline,resource specification and pipelining of arithmetic operation. Function inlining, Function instantiation , Dataflow
四、实现方法(4.5.1)
FPGA side
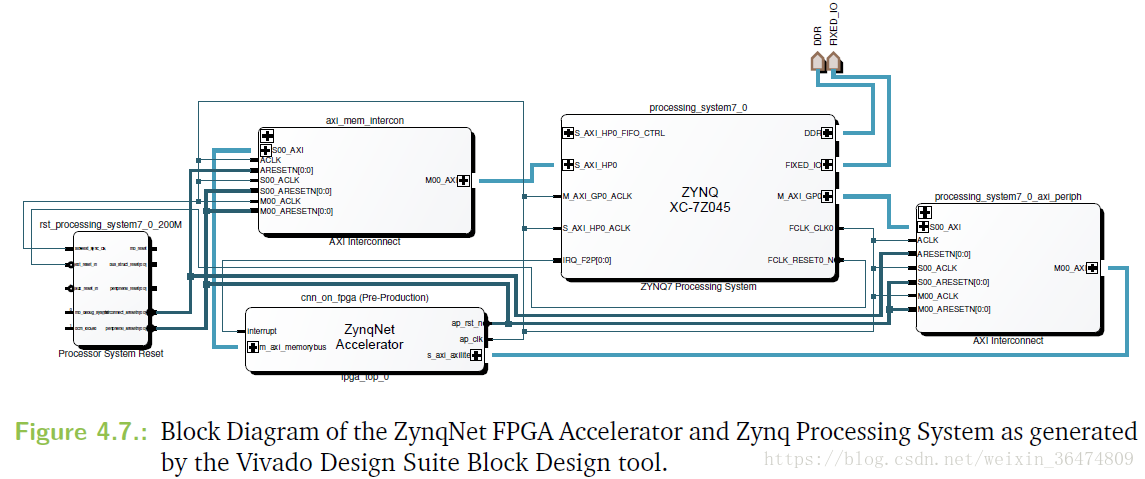
通过文档UG871,我们可以将相应的代码生成为相应IP core,然后根据下面搭建系统。(通过这个我们看出HLS最高级别的函数为FPGA top)。然后VHLS会将相应的系统生成VHDL或者Verilog wrapper。然后就可对设计进行synthesis,之后RTL会生成相应的比特流,.bit文件
CPU side
Xilinx Software Development Kit
Vivado Design Suite会输出一个 .hdf文件(hardware design file),后续会被SDK打开,可以创建一个裸的不需要操作系统的应用。它包括所有的工具来创建一个完整的新的Linux环境下的First Stage Boot Loader(FSBL)
Memory-Mapped Input and Output
Vivado Design Suite会输出基于c的AXI4-Lite的驱动:
- 开始与停止top level FPGA entity
- check statue of acceleator(idle 、ready 、done)
- 设置与获得所有AXI-Lite接口的参数
ZynqNet驱动:
- 当前的First Stage Boot Loader(FSBL)在zynqbox configuration中对programmable logic为FCLK_CLK0的时钟源100MHz,所以ZynqNet的FPGA accelerator只是运行了200MHz的一半。
- 在启动驱动之前,S_AXI HP0应被设置为32 bit bus width。
- 对于ZynqNet的FPGA加速器需要加载zynqnet_200MHz.bit.















 7999
7999











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











