







Spark Streaming入门
概述
Spark Streaming是核心Spark API的扩展,可实现实时数据流的可伸缩,高吞吐量,容错流处理。数据可以从像卡夫卡,室壁运动,或TCP套接字许多来源摄入,并且可以使用与像高级别功能表达复杂的算法来处理map,reduce,join和window。最后,可以将处理后的数据推送到文件系统,数据库和实时仪表板。实际上,您可以在数据流上应用Spark的 机器学习和 图形处理算法。

在内部,它的工作方式如下。Spark Streaming接收实时输入数据流,并将数据分成批次,然后由Spark引擎处理,以成批生成最终结果流。
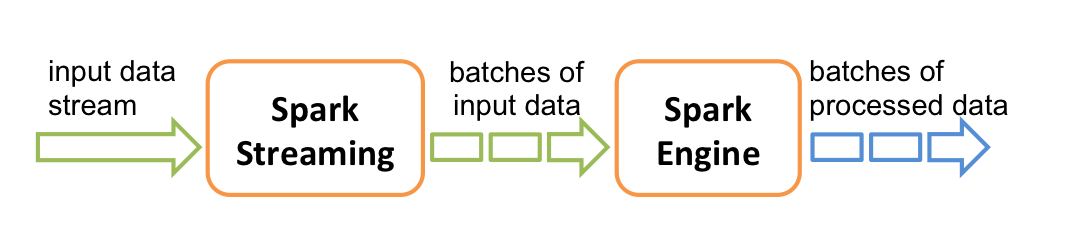
<Spark Streaming提供了称为离散化流或DStream的高级抽象,它表示连续的数据流。可以根据来自Kafka和Kinesis等来源的输入数据流来创建DStream,也可以通过对其他DStream应用高级操作来创建DStream。在内部,DStream表示为RDD序列 。
官方链接
Spark Streaming个人定义:将不同的数据源的数据经过Spark Streaming处理之后将结果集输出到外部文件系统
特点:
- 低延时
- 能从错我中高效的恢复:fault-tolerant
- 能够运行在成百上千的节点
- 能够将批处理、机器学习、图计算等子框架和Spark Streaming综合起来使用
架构:
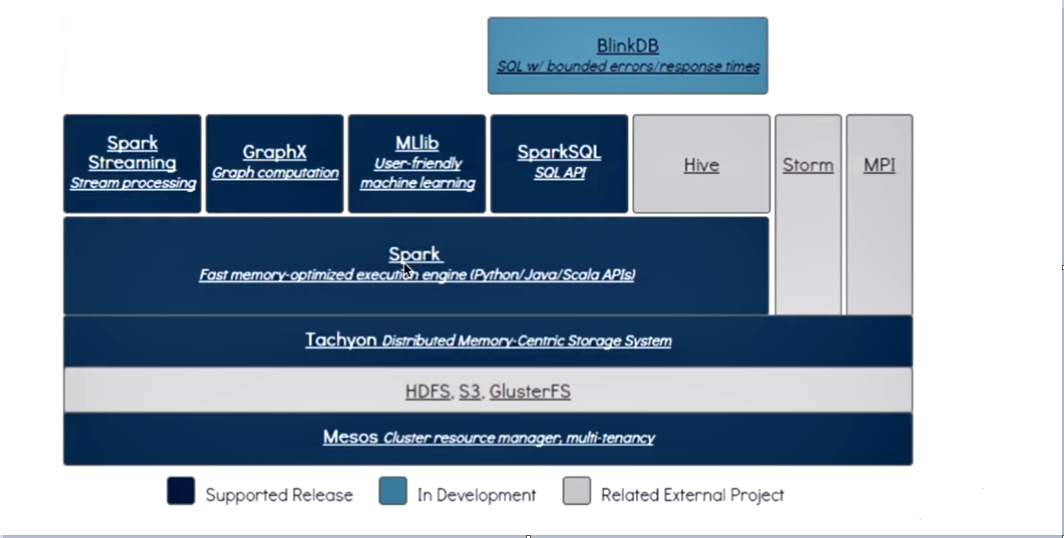
从上图可以看出,只要安装了spark后,Spark Streaming不需要单独安装
验证了 One stack to rule them all:一栈式解决
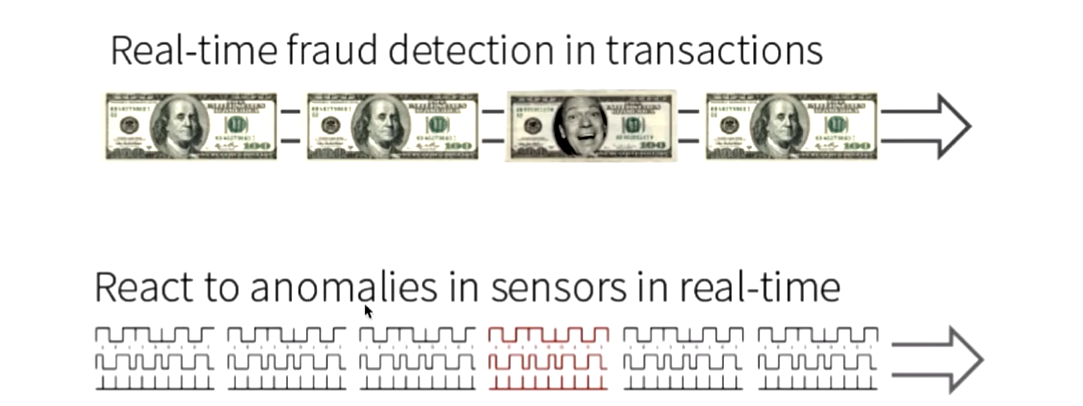
应用场景
- 交易过程中金融欺诈检测
- 实时电子传感器
- 电商产品推荐
- web日志实时监控
集成Spark生态系统的使用
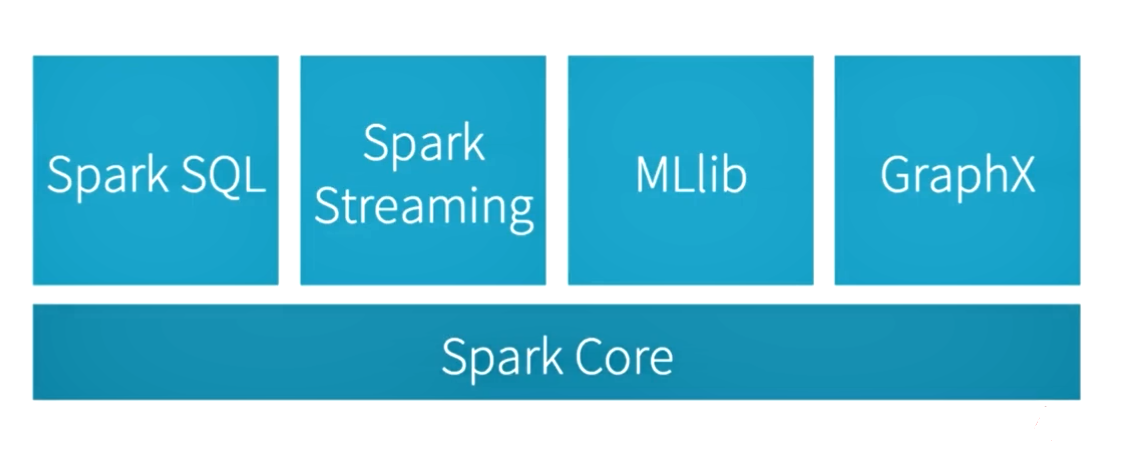
- Spark Streaming 与 Spark Core 结合使用

- Spark Streaming 与 MLlib结合使用

- Spark Streaming 与 Spark SQL结合使用

Spark Streaming发展史
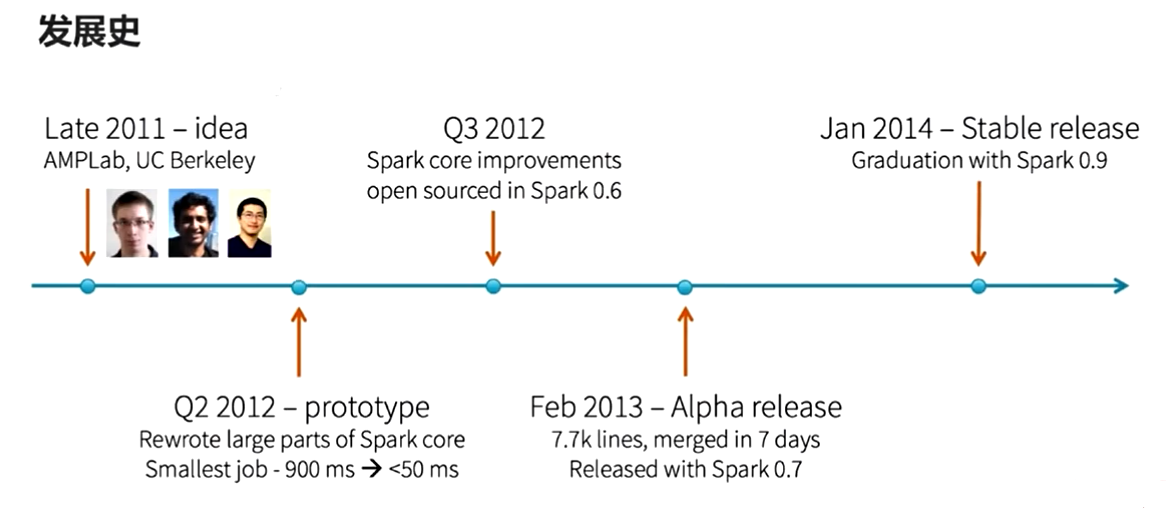
- 2011年伯克利大学提出
- 2012年重写了spark core的大部分代码
- 2014年发布稳定版本0.9版本(Spark Streaming正式毕业)
词频统计
使用spark-submit执行
使用spark-submit提交spark应用程序,适用于生产环境
spark源码地址:https://github.com/apache/spark/tree/master/examples/src/main
选择scala版本,resources下是测试数据
NetworkWordCount.scala是词频统计的代码,在安装spark的服务器上已经有这个编译好的jar包,直接拿来运行即可 CDH版本的jar包路径:/opt/cloudera/parcels/SPARK2-2.2.0.cloudera2-1.cdh5.12.0.p0.232957/lib/spark2/examples/jars/spark-examples_2.11-2.2.0.cloudera2.jar
新起一个客户端,“To run this on your local machine, you need to first run a Netcat server” 执行nc -lk 9999,监听9999端口
spark2-submit --master local[2] \
--class org.apache.spark.examples.streaming.NetworkWordCount \
--name NetworkWordCount \
/opt/cloudera/parcels/SPARK2-2.2.0.cloudera2-1.cdh5.12.0.p0.232957/lib/spark2/examples/jars/spark-examples_2.11-2.2.0.cloudera2.jar hadoop103 9999
注意:这里如果你的CDH Spark的版本升级到了spark2,这里要使用spark2-submit 最后hadoop103 和9999 是运行需要的两个参数:主机名和端口

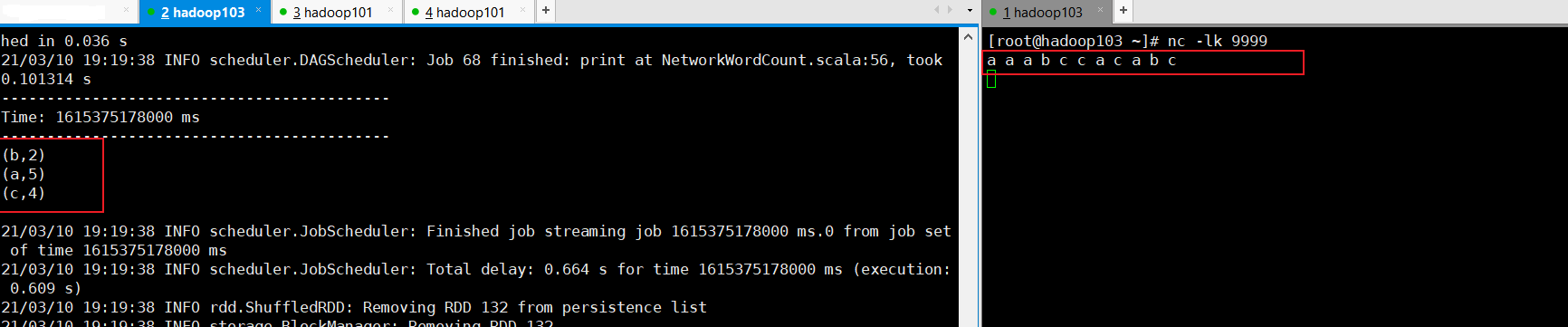
这时在启动Netcat的窗口,发送数据,然后在启动submit的窗口观察,计算情况,可以发现很快就算出来了,注意计算的很快,稍微不注意就刷新过去了
[root@hadoop103 ~]# nc -lk 9999
a a a b c c a c a b c
a打印了5个,b打印了2个,c打印了4个,从下图中可以看到计算的是正确的。
使用spark-shell执行
如何使用spark-shell来提交任务(适用于测试环境)
[hdfs@hadoop103 ~]$ spark2-shell --master local[2]
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Spark context Web UI available at http://172.16.3.160:4040
Spark context available as 'sc' (master = local[2], app id = local-1615465036316).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 2.2.0.cloudera2
/_/
Using Scala version 2.11.8 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_192)
Type in expressions to have them evaluated.
Type :help for more information.
scala> import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.streaming.{Seconds, StreamingContext}
scala> val ssc = new StreamingContext(sc, Seconds(1))
ssc: org.apache.spark.streaming.StreamingContext = org.apache.spark.streaming.StreamingContext@6aed4a23
scala> val lines = ssc.socketTextStream("hadoop103", 9999)
lines: org.apache.spark.streaming.dstream.ReceiverInputDStream[String] = org.apache.spark.streaming.dstream.SocketInputDStream@14f254f
scala> val words = lines.flatMap(_.split(" "))
words: org.apache.spark.streaming.dstream.DStream[String] = org.apache.spark.streaming.dstream.FlatMappedDStream@2d0ce8a1
scala> val wordCounts = words.map(x => (x, 1)).reduceByKey(_ + _)
wordCounts: org.apache.spark.streaming.dstream.DStream[(String, Int)] = org.apache.spark.streaming.dstream.ShuffledDStream@4973fb7d
scala> wordCounts.print()
scala> ssc.start()
scala> ssc.awaitTermination()-------------------------------------------
Time: 1615465111000 ms
-------------------------------------------
-------------------------------------------
Time: 1615465112000 ms
-------------------------------------------
-------------------------------------------
Time: 1615465113000 ms
-------------------------------------------
-------------------------------------------
Time: 1615465114000 ms
-------------------------------------------
[root@hadoop103 ~]# nc -lk 9999
a a c b c a d d a b
同样在右边窗口输入字符回车之后,就可以计算出相应的字符的count值

spark-shell这种方式适用于测试时,将自己开发的代码粘贴到spark-shell中去执行即可,如果使用spark-submit是要将代码进行打成包,然后才能使用submit的方式进行提交,比较繁琐,一般适用于生产环境。
















 1347
1347











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











