







基于深度学习的泰坦尼克旅客生存预测
摘要:近年来,随着深度学习的迅速发展和崛起,尤其在图像分类方向取得了巨大的成就。本文实验基于Windows10系统,仿真软件用的是Anaconda下基于python编程的JupyterNotebook编辑器。通过利用Google的深度学习框架Tensorflow的高阶框架Keras,搭建神经网络结构,实现对泰坦尼克号上旅客生存概率预测。
关键词:深度学习;Keras;神经网络
Titanic passenger survival prediction based on deep learning
Abstract: In recent years, with the rapid development and rise of deep learning,great achievements have been made especially in the direction of image classification. The experiment of this article is based on Windows 10 system,and the simulation software uses JupyterNotebook editor based on python programming under Anaconda. By using Google’s deep learning framework Tensorflow's high-order framework Keras, a neural network structure is built to realize the passenger survival probability prediction on the Titanic.
Keywords: deep learning; Keras; neural network
第1章绪论
1.1深度学习
深度学习是一门新的技术科学,但实际上目前大家所熟悉的“深度学习”基本上是深层神经网络的代名词,而早期神经网络的发展可以追溯到上个世纪40年代,深度学习的发展历史主要可以分为三个阶段,从BP算法的提出到2006年这段期间被称作萌芽期;1896年,辛顿和鲁梅哈特共同提出了BP后向传播算法,解决了当时双层网络难以训练的问题,使得神经网络进入了实用阶段,但是,随着神经网络的层数加深,研究员们发现了BP算法存在着一个缺点,在计算梯度时发生了不稳定的情况,直白来说就是离输出层越远的参数就越难以训练,要么变化非常大,要么就不发生变化,这种问题后来被称作梯度爆炸或者梯度消失,通过研究发现,随着层数递增,出现梯度爆炸或者梯度消失的情况就越明显。除了层数的限制,参数过多也成了神经网络的问题之一,对计算机的能力也提出了要求,加之那个年代很多问题的训练数据都不大,模型容易发生过拟合,泛化能力很差,除了参数的问题之外,因为BP算法本身依赖于梯度,所以神经网络在训练时容易陷入局部最小值而不能达到全局最小值,这也是存在的一个大问题。在进入二十世纪九十年代后,神经网络的发展变的相对缓慢,由于新的机器学习算法支持向量机SVM(Support Vector Machine)被提出,SVM在解决当时手写体识别等问题上成功打败了其他的浅层神经网络,在当时SVM相比其他的浅层神经网络,具有调参简单、全局最优和泛化能力强等优点,很快就成了研究的主流对象,神经网络再一次受到了冷落。
在2006到2012年期间,是深度学习的迅速发展期,在2006年,号有深度学习之父之称的Hinton教授提出了深度信念网络,一举打败了风光已久的SVM,这让许多研究者的目光重新回到了神经网络,并提出了“深度学习”概念和深度学习的训练方法,揭开了深度学习发展的序幕;自2012年后到今天,深度学习进入了爆发期,2012年由Hinton教授的学生提出的AlexNet 模型在Imagenet竞赛中取得了冠军,并且效果在很大程度上超过了传统的方法,经过将近十年的发展,深度学习逐渐出现了以卷积神经网络、深度置信网络、栈式自编码网络和循环神经网络为代表的模型。现在世界各大互联网公司已经成立了专门进行深度学习工程化的研究部门,其中国外的代表公司有谷歌、微软,国内有百度和科大讯飞,均已经在语音识别、图像检索、机器翻译等领域上取得了很好的效果。
机器学习是实现人工智能的一种重要途径,而深度学习又是机器学习中极为有效的一种方法。以目标检测为例,基于区域选择和人工特征提取的传统方法大大增加了计算量,耗时而且无法满足实时性的要求,并且识别误差明显过大,因此传统方法遇到了瓶颈。然而,深度学习以其强大的模型表达和特征提取的能力,使精确度和实时性取得了跨越式提升,推动了目标检测领域的变革。
从宏观角度讲,深度学习中的“深度”即神经网络的层数之深,如图1.1所示,最常见的人工神经网络由输入层、隐含层和输出层构成,最左边的是输入层,其中包含输入神经元,最右边是输出层,其中包含有输出神经元,中间层就是隐含层。这种以上一层的输出作为下一层的输入,并且上一层神经元与先下一层神经元均有联系的网络,即为前馈全连接神经网络,也是最基本的神经网络。深度学习又称为深度神经网络,所以网络中隐含层的层数较大,少者数十层,多者数百层,这种结构有利于从原始数据中自主、有效的学习到复杂特征。以卷积神经网络为例,一般来讲,卷积神经网络层数越深,模型从数据中学习到的特征越复杂,识精确度越高。
深度学习中的“学习”也是核心问题之一,简单来讲,即为自动的将简单的特征组合成更加复杂的特征,并利用这些组合特征解决问题。以卷积神经网络为例,深度学习可以从图像的像素特征逐渐组合线、边、角、简单形状、复杂形状等更加有效的复杂特征。出学习的过程即为权重更新过程,通过正向传播和反向传播的结合,以损失函数的渐小为目标,不断沿着梯度的反方向更新权重的大小,直至模型合适。学习过程中,采用激活函数去除模型线性化,引入正则化防止模型过拟合,以及采用梯度下降算法、学习率衰减算法等方法对学习过程进行优化。

图1.1前馈全连接神经网络
1.2经典卷积神经网络
深度学习的兴起源于深度神经网络的崛起,1989年,被世界公认的人工智能三大巨头之一的Yann LeCun教授提出了LeNet网络结构,这是卷积神经网络的鼻祖,接着在1998年,他又提出了新的LeNet结构,即LeNet-5,当时LeNet-5用于解决手写数字识别问题,输入的图片均为单通道灰度图,分辨率为28×28,在Mnist数据集上,LeNet-5达到了大约99.2%的正确率,LeNet-5模型总共7层,由两个卷积层,两个下采样(池化)层,三个全连接层组成,最后通过输出全连接层输出10个概率值,对应0~9的预测概率,网络结构如下图1.2所示。

图1.2 LeNet-5网络结构图
在往后的十多年里,越来越多的新型卷积神经网络模型被提出,其中比较经典的模型有:AlexNet、ZFNet、VGGNet、GoogleNet、ResNet、DenseNet。AlexNet[2]是在2012年由Alex Krizhevsky提出的一个深度学习模型,并赢得了视觉领域竞赛ILSVRC2012的冠军,并且大幅度超过传统的方法,在百万量级的ImageNet数据集上,识别率从传统的70%多提升到了80%多,top5预测的错误率为16.4%,远超第一名,将深度学习正式推上了舞台。AlexNet为8层结构,其中前5层为卷积层,后面3层为全连接层,在两个GPU上运行,其中学习参数有大约6千万个,神经元有650000个左右,由于当时是对1000个类别进行分类,所以在网络的最后输出是1000个类别的概率值,其中AlexNet的网络结构图如下图1.3所示:
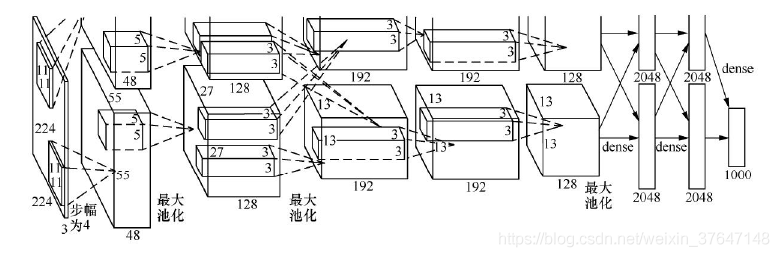
图1.3 AlexNet网络结构图
ZFNet是基于AlexNet网络的微调,其网络结构没什么改进,只是调了调参,性能较Alex提升了不少。具体只是将AlexNet第一层卷积核由11变成7,步长由4变为2,第3,4,5卷积层转变为384,384,256。使用Relu激活函数和交叉熵损失函数,TOP错误率为11.2%,是2013ImageNet分类任务的冠军,其网络结构如下图1.4所示。
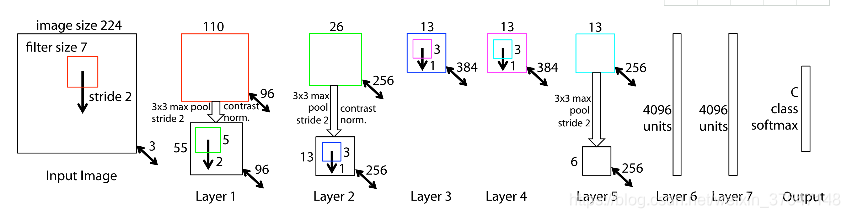
图1.4 ZFNet网络结构图
2014年,由谷歌DeepMind公司研究员与牛津大学计算机视觉组合(Visual Geometry Group)共同提出了VGGNet,它是一种深度卷积网络,研究了卷积神经网络的深度和性能之间的关系,通过反复的堆叠3×3的小型卷积核和2×2的最大池化层,成功的构建了16~19层深的卷积神经网络,比较常用的是VGGNet-16和VGGNet-19。
VGGNet把网络分成了5段,每段都把多个3×3的卷积网络串联在一起,每段卷积后面接一个最大池化层,最后面是3个全连接层和一个softmax层。是2014年ImageNet竞赛定位任务的第一名和分类任务的第二名。在top5上的错误率为7.5%,目前为止,VGGNet依然被用来提取图像的特征,和AlexNet相比只是进一步加深层数(16-19层),在结构上并没有特别的创新点。可以看成是AlexNet的加强版本。为了解决初始化(权重初始化)等问题,VGG采用的是一种Pre-training的方式,这种方式在经典的神经网络中经常见得到,就是先训练一部分小网络,然后再确保这部分网络稳定之后,再在这基础上逐渐加深。图1.5从左到右体现的就是这个过程,并且当网络处于D阶段的时候,效果是最优的,因此D阶段的网络也就是VGG-16。E阶段得到的网络就是VGG-19。VGG-16的16指的是conv+fc的总层数是16,是不包括maxpool的层数。VGGNet的网络结构如下图1.5所示。
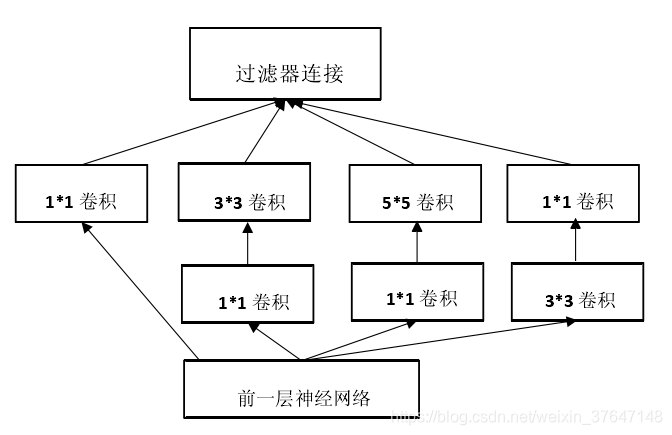
图1.5 VGGNet网络结构
GoogleNet在2014年的ImageNet分类任务上击败了VGGNets夺得冠军,GoogLeNet跟AlexNet,VGG-Nets这种单纯依靠加深网络结构层数进而改进网络性能的思路不一样,它另辟蹊径,在加深网络的同时(22层),也在网络结构上做了创新,引入Inception结构代替了单纯的卷积+激活的传统操作(这思路最早由Network in Network提出)。这是一种网中网结构,即原来的节点也是一个网络,用Inception之后整个网络结构的宽度和深度都可扩大,能带来2到3倍的性能提升,GoogLeNet基于Network in Network(网中网)的思想,对卷积核进行改进,将原来的线性卷积层(linear convolution layer)变为多层感知卷积层(multilayer perceptron),使得卷积核具有更强的特征提取能力。同时使用全局平均池化层( Average pool )(即将图片尺寸变为1X1)来取代最后全连接层,去掉了全连接层使得参数大量减少,也减轻了过拟合。Inception一直在不断发展,现在已经发展到了第四代,其中最经典是Inception-v3,Inception结构里主要做了两件事。第一:通过3×3的池化、以及1×1、3×3和5×5这三种不同尺度的卷积核,一共4种方式对输入的特征响应图做了特征提取。第二:为了降低计算量。同时让信息通过更少的连接传递以达到更加稀疏的特性,采用1×1卷积核来实现降维。其网络模块结构如下图1.6所示。
图1.6 Inception-v3模块网络结构
2015年何恺明推出的ResNet(残差网络)在ISLVRC(ImageNet大规模视觉识别挑战赛)上横扫所有选手,获得冠军。ResNet网络层数达到了152层,该框架能大大简化模型网络的训练时间,使得在可接受时间内,模型能够更深,在深度学习领域中,网络逐渐加深会对网络的反向传播提出挑战,在反向传播中每一层的梯度都是在上一层的基础上计算的,层数越多会导致梯度在多层传播时越来越小,直到梯度消失,于是表现的结果就是随着层数变多,训练的误差会越来越大。ResNet在网络结构上做了大创新,即残差网络通过引入残差单元结构解决了梯度消失这个问题,残差单元ResNet在卷积神经网络的新思路,绝对是深度学习发展历程上里程碑式的事件。残差单元结构如下图1.7所示。

图1.7 残差单元结构
从上图可以看出,数据经过了两条路线,一条是常规路线,另一条则是捷径(shortcut),直接实现单位映射的直接连接的路线,这有点类似与电路中的“短路”。通过实验,这种带有shortcut的结构确实可以很好地应对退化问题。我们把网络中的一个模块的输入和输出关系看作是y=H(x),那么直接通过梯度方法求H(x)就会遇到上面提到的退化问题如果使用了这种带shortcut的结构,那么可变参数部分的优化目标就不再是H(x),若用F(x)来代表需要优化的部分的话,则H(x)=F(x)+x,也就是F(x)=H(x)-x。因为在单位映射的假设中y=x就相当于观测值,所以F(x)就对应着残差,因而叫残差网络。
DenseNet(Dense Convolutional Network)是一种具有密集连接的卷积神经网络。在该网络中,任何两层之间都有直接的连接,也就是说,网络每一层的输入都是前面所有层输出的并集,而该层所学习的特征图也会被直接传给其后面所有层作为输入。DenseNet是CVPR(国际计算机视觉与模式识别会议)2017年的最佳论文,论文中提出的DenseNet主要还是和ResNet及Inception网络做对比,思想上有借鉴,但却是全新的结构,网络结构并不复杂,却非常有效,在CIFAR指标上全面超越ResNet。可以说DenseNet吸收了ResNet最精华的部分,并在此上做了更加创新的工作,使得网络性能进一步提升。DenseNet脱离了加深网络层数(ResNet)和加宽网络结构(Inception)来提升网络性能的定式思维,从特征的角度考虑,通过特征重用和旁路(Bypass)设置,,既大幅度减少了网络的参数量,又在一定程度上缓解了梯度消失的问题,同时加强了特征传播,鼓励特征复用。稠密连接主要由两部分组成:dense block稠密块+transition layer 过渡层。其中稠密块定义了输入输出之间的连接关系,过渡层是用来控制通道数。如图1.9是一个三个稠密块的稠密连接网络。每层之间有过渡层改变通道数大小,最后一层没有过渡层。图1.10是DenseNet的网络结构。

图1.9三个稠密块的稠密连接网络
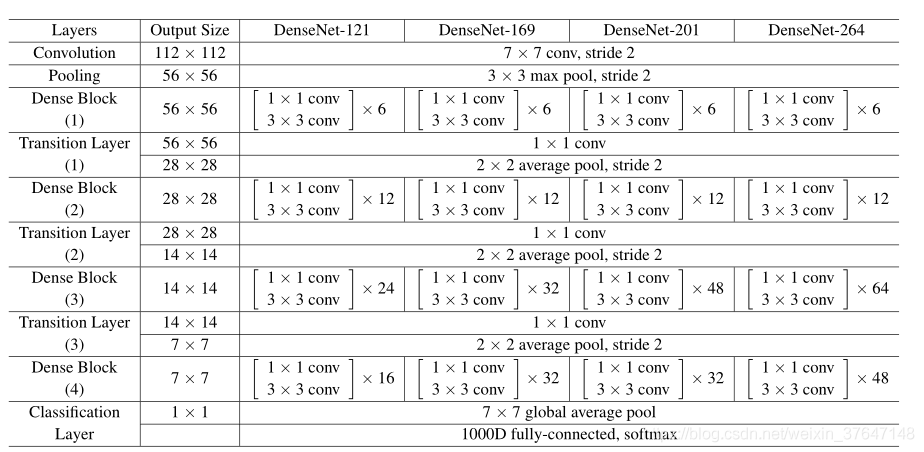
图1.10 DenseNet的网络结构
1.3深度学习技术的应用
深度学习最早兴起于图像识别,但是在短短几年内,深度学习推广到了机器学习的各个领域。如今,深度学习在很多机器学习领域都有非常出色的表现,在图像识别、自然语言处理、自动医学诊断、网络广告投放、搜索引擎、电脑游戏、金融以及机器人等各大方面都已经有了应用,例如在谷歌,图像分类、物体识别已经被广乏应用到了谷歌无人驾驶车、谷歌地图、谷歌图像搜索等产品中[4]。基于深度学习的语音识别已经被应用到了各个领域,其中大家最为熟悉的应该是苹果公司推出的Siri系统,Siri系统可以根据用户的语音输入完成相应的操作功能,这大大方便了用户的使用。如果说深度学习在图像识别领域上的突破掀起了学术界的研究浪潮,那么深度学习在人机博弈上的突破使得这个概念被全社会所熟悉,在2016年3月,由谷歌开发的围棋人工智能系统AlphaGo和来自韩国的世界第二围棋手李世石进行了一场人机博弈,AlphaGo最终以总比分为4:1的成绩打败了李世石,AlphaGo的胜利将人工智能推向了全球瞩目的焦点,是人工智能发展史上具有里程碑意义的大事。
第2章 深度学习框架介绍
2.1 TensorFlow
2015年11月谷歌(Google)出品,基于Python和C++编写,深度学习最流行的库之一,是谷歌在深刻总结了其前身DistBelief的经验教训上形成的;它不仅便携、高效、可扩展,还能在不同计算机上运行;小到智能手机,大到计算机集群;它是一款轻量级的软件,可以立刻生成你的训练模型,也能重新实现它;TensorFlow有强大的社区、企业支持,因此它广泛应用于从个人到企业、从初创公司到大公司等不同群体[1]。2019年10月已发布最新的TensorFlow2.0 版本。
2.2 tf.keras
keras是François Chollet于2014-2015年开始编写的开源高层深度学习API。所谓“高层”,是相对于“底层”运算而言(例如add,matmul,transpose,conv2d)。keras把这些底层运算封装成一些常用的神经网络模块类型(例如Dense, Conv2D, LSTM等),来增强API的易用性和代码的可读性,提高深度学习开发者编写模型的效率。keras本身并不具备底层运算的能力,所以它需要和一个具备这种底层运算能力的backend(后端)协同工作。keras的特性之一就是可以互换的后端,你在所有后端上写的keras代码都是一样的。从一个后端训练并存储的模型,可以用别的后端加载并运行。一开始,在 v1.1.0 之前,Keras 的默认后端都是 Theano。与此同时,Google发布了TensorFlow,这是一个用于机器学习和神经网络训练的符号数学库。Keras开始支持TensorFlow 作为后端。渐渐地,TensorFlow 成为最受欢迎的后端,这也就使得TensorFlow从Keras v1.1.0发行版开始成为Keras的默认后端。一般来说,一旦TensorFlow成为了Keras的默认后端,没有TensorFlow的情况下就无法使用Keras,所以如果你在系统上安装了Keras,那么你也得安装TensorFlow。同样的,TensorFlow用户也越来越被高级Keras API的简单易用所吸引。tf.keras是在TensorFlow v1.10.0中引入的,这是将keras直接集成到TensorFlow包中的第一步。tf.keras 软件包与你通过pip安装的 keras 软件包(即 pip install keras)是分开的,过去是这样,现在也是。为了确保兼容性,原始的keras包没有被包含在 tensorflow 中,因此它们的开发都很有序。然而,这种情况正在改变——当谷歌在2019年6月发布 TensorFlow2.0时,他们宣布Keras现在是 TensorFlow 的官方高级 API,用于快速简单的模型设计和训练。2016-2017年间,Google Brain组根据开源用户对TensorFlow易用性的反馈,决定采纳keras为首推、并内置支持的高层API。当时TensorFlow已经有tf.estimator、slim、sonnet、TensorLayers等诸多高层次API,选择keras主要是考虑它的优秀性以及在用户群中的受欢迎程度。所以,keras的代码被逐渐吸收进入tensorflow的代码库,那时fchollet也加入了Google Brain组。所以就产生了tf.keras:一个不强调后端可互换性和tensorflow更紧密整合、得到tensorflow其他组建更好支持且符合keras标准的高层次API。本文使用的是tf.keras软件包。
第3章 数据集
3.1数据集介绍
数据是深度学习的前提,是深度学习的重要原材料,是驱动深度学习提高识别率和精确度的核心因素。本文数据集是从这个网站http://biostat.mc.vanderbilt.edu/wiki/pub/Main/DataSets/titanic3.xls下载。此次用的数据集是一个标准的Excel表格,所以在数据预处理进行数据的相应转换的时候,应该采取不同的处理方法。在数据集中,共有1309名乘客数据,其中891是已知存活情况,剩下418则是需要进行分析预测的。在Excel表格中共有14列,分别是“pclass”、“survived”、“name”、“name”、“age”、“sibsp”、“parch”、“ticket”、“fare”、“cabin”、“embarked”、“boat”、“body”、“home.dest”。如图3.1所示。图3.2是对数据集中的关键字段的详细解释。
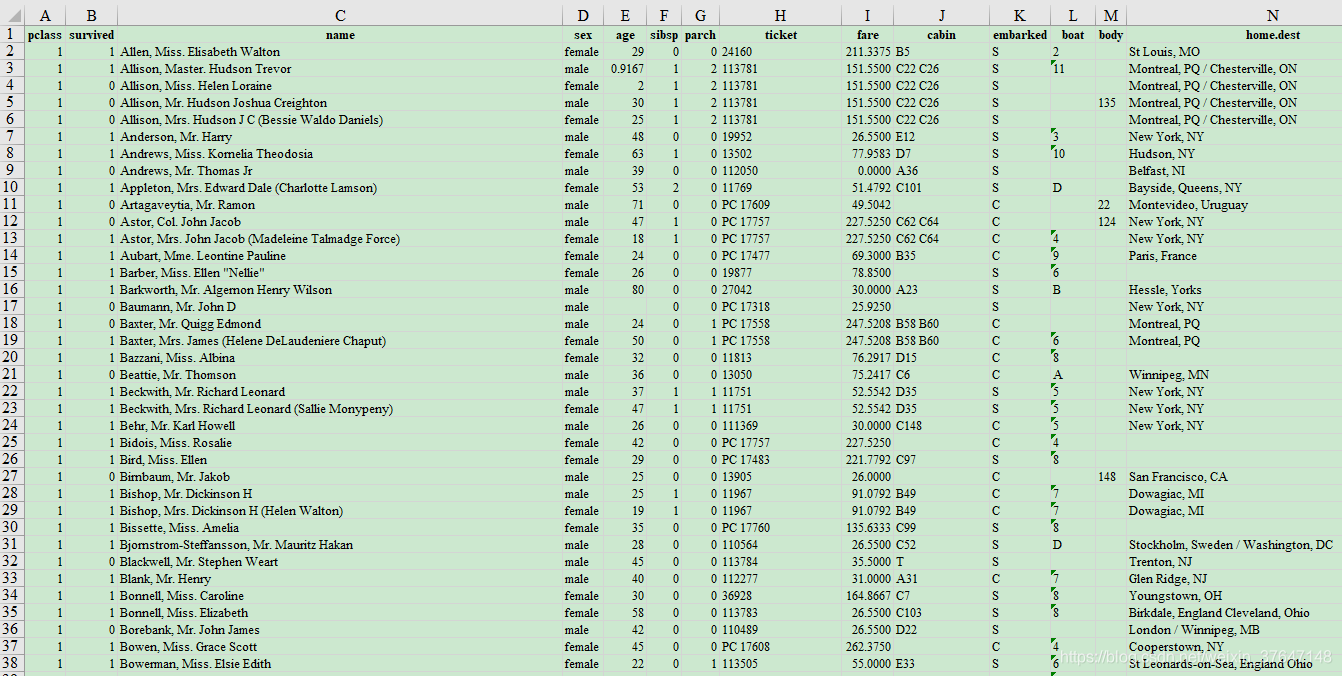
图3.1 泰坦尼克旅客数据集
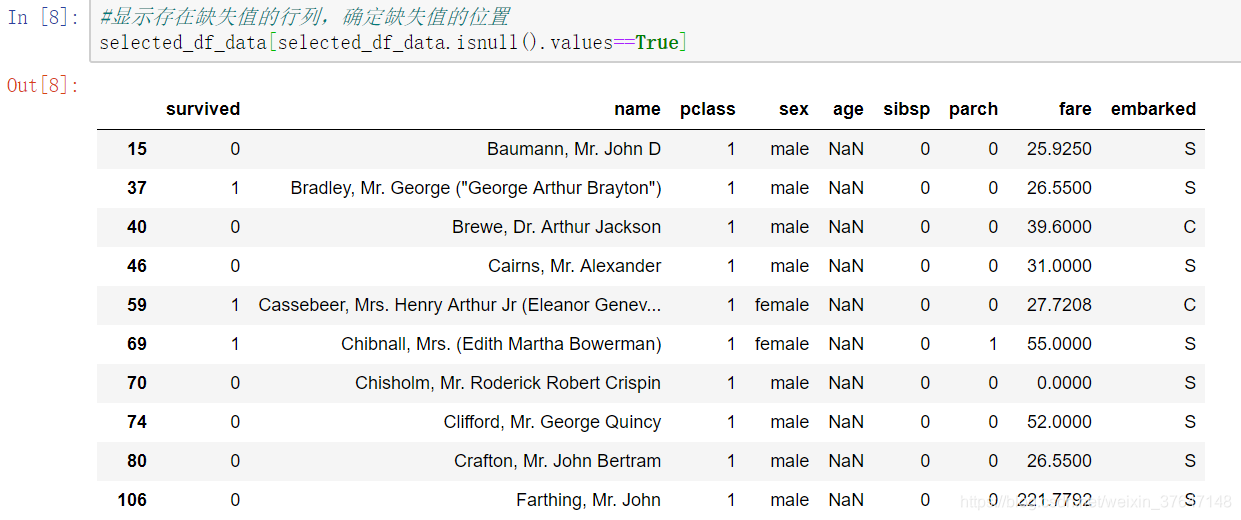
图3.2 关键字段解释
3.2 数据清洗
3.2.1 查看数据
首先把数据集中不重要的字段去掉外,仔细研究数据集会发现数据中的某些字段会有缺失的信息。比如上图3.1所示的第17行“age”列数字缺失。当然,缺失的数据不止一条。其他字段也会有缺失的。这样在后期进行建模运行的时候,要对数据做一些预处理。这里使用pandas对数据进行处理。首先对数据文件,进行读取。Pandas提供了read_excel函数可以直接读取excel表格,返回的是DataFrame格式,最后查看数据摘要。如图3.3所示。从下图中可以看出“age”这项只有1046个数据,缺失了263个数据。“fare”有1308项,缺失了1项。图3.4是显示所有数据信息,与excel表格内容差不多,共有1309行。

图3.3 数据摘要
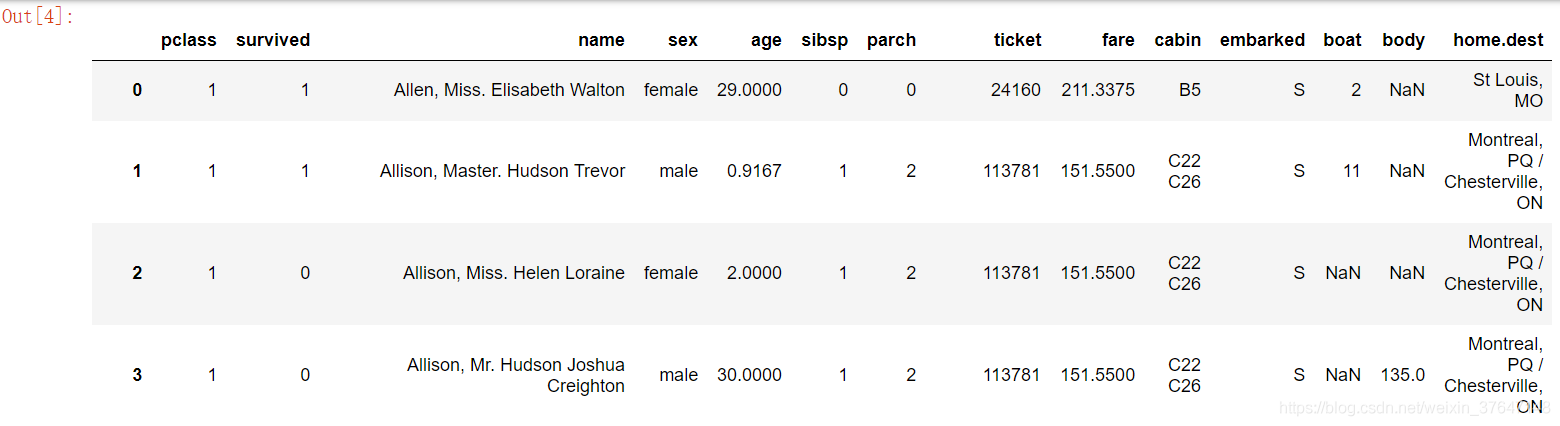

图3.4 数据信息
3.2.2 筛选提取字段
在数据集中共有14个字段,并不是所有字段对建立模型来说是有意义的,因此需要,筛选提取需要的特征字段,其中survival(是否生存)是label(标签)字段,也就是我们要预测的目标,其他都是候选特征字段,并且ticket(船票号码)和cabin(舱位号码)等与预测结果无关,将其忽略。需要注意的是name(姓名)字段在训练时不需要,但在预测阶段会使用,这里我们先暂时选用name,因为现在如果去掉name字段,我们就无法知道每一行到底是谁的信息,故最后选择的字段分别是“survival”、“name”、“pclass”、“sex”、“sibsp”、“parch”、“fare”和“embarked”共8个特征字段。如图3.5所示。
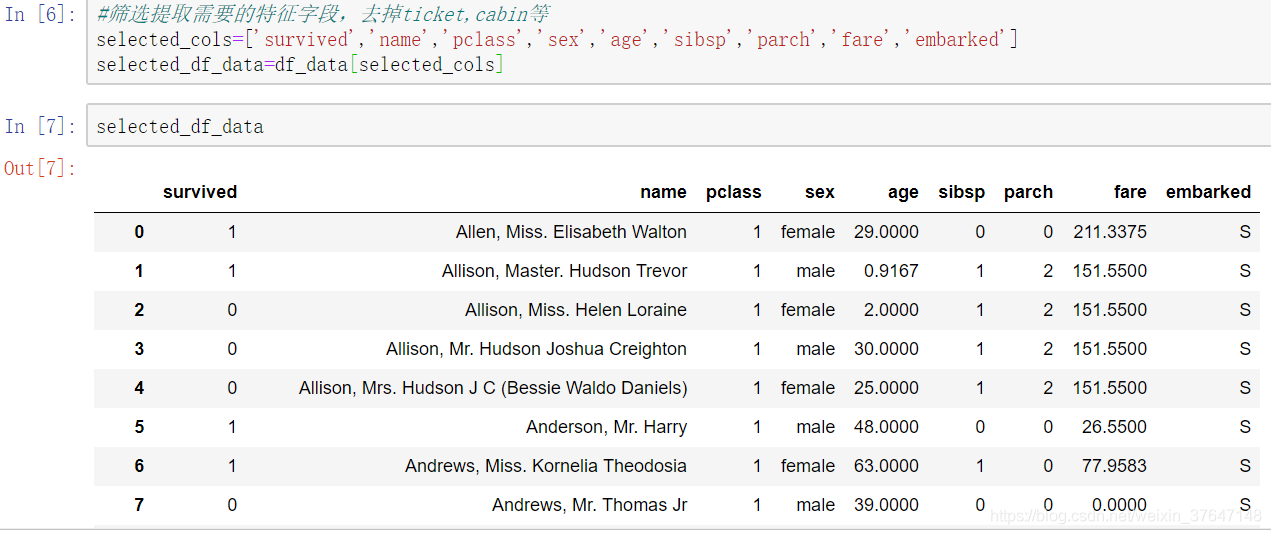
图3.5 筛选后字段信息
3.2.3 字段处理问题
还有需要注意的问题是,name字段在训练时不需要,必须先删除,但在预测阶段会使用,age 有些项的age字段是null(空值),但是在后面训练模型时,给模型喂数据的时候,是不应该存在空值的,故处理的方案是将null改为平均值,fare 同age,数据sex字段用的是“male”和“female”是文字,在模型输入的时候需要的是数字,故需转换为数字,比如0和1,另外还有embarked(登船港口),第一个问题是如果有null值,需要先改为某一个值,本文统一指定为“S”,第二个问题有三个港口也是文字,需使用One-Hot Encoding 转换为数字。具体处理方式如图3.6所示。Pandas判断缺失值一般采用isnull函数,图3.7是显示数据集中缺失值的位置。定义一个数据预处理prepare_data函数,来填充缺失值,需要说明的是,真正要训练的时候,name是不需要加入的,故在这里name字段被删除,这是通过drop来实现的,drop不改变原有的数据文件中的数据,而是返回另一个DataFrame来存放删除后的数据,axis=1表示删除列。之后,分离出特征值和标签值,由数据集知道第一列survival是标签值,后7列是特征值,但是这时候的特征值,是大大小小的范围不一样,故这里需要做对特征值进行标准化的工作,本文引入了“sklearn”这个第三方的库,这个库里面有个“preprocessing”(预处理)包是专门做这些工作的,本文把特征值的范围设置在0到1区间。预处理函数如图3.8所示。
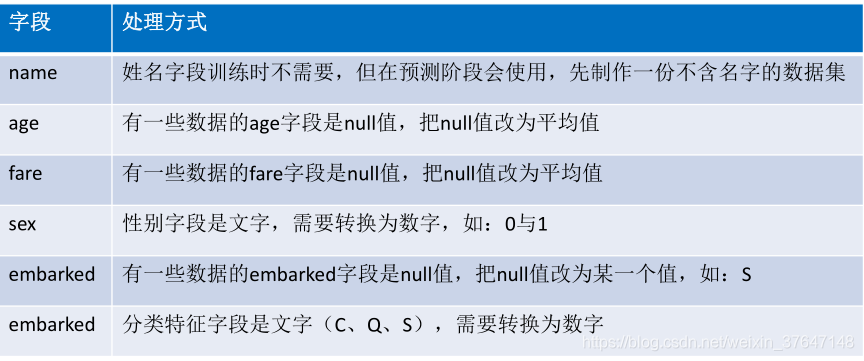
图3.6 字段处理

图 3.7 缺失值数据信息

图3.8 数据预处理函数
3.2.4 数据准备
在机器学习训练模型的时候常常需要将数据打乱,否则,假如一个数据集前半部分target是1,后半部分target是0,这样训练出来的效果很不好,很有可能模型会过拟合后半部分的样本。因此为了模型获得更好地泛化能力,常常打乱数据顺序,进行训练,这里是通过Pandas的抽样函数sample实现,得到打乱后的数据集,即满足随机排列了也方便下面一步将数据集划分为训练集和测试集两部分,本文是将数据集1309条数据中抽取前面的80%数据用于训练,后面的20%数据用于测试。如图3.9所示。
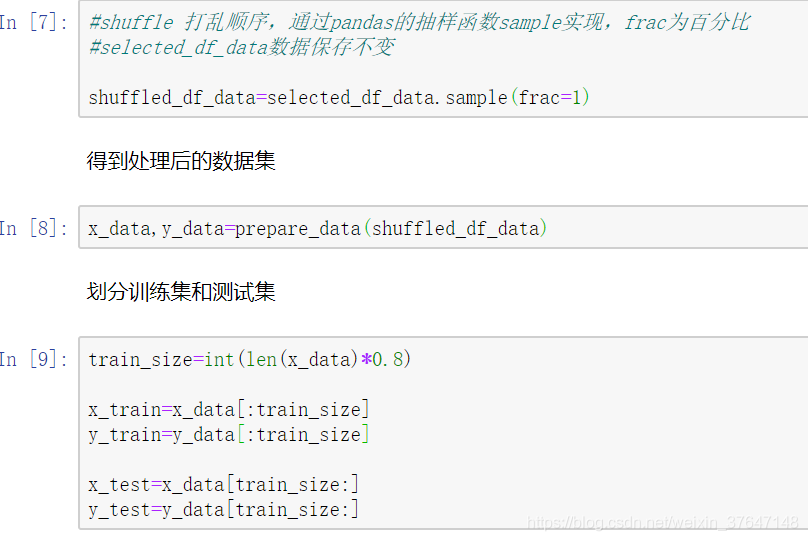
图3.9 数据划分
第4章 构建Keras神经网络模型
4.1构建网络结构
针对本文的数据集样本量并非很大,故网络结构建立三层,即2个隐藏层和一个输出层。输入层因为有7个特征字段,故输入层要有7个神经元来接收数据,第一隐藏层有64个神经元,第二个隐藏层有32个神经元,输出层输出的是0到1之间的生存概率的数值,所以只要有一个1个神经元就足够了,此外输入层和隐藏层都有一个偏置项。如图4.1所示。
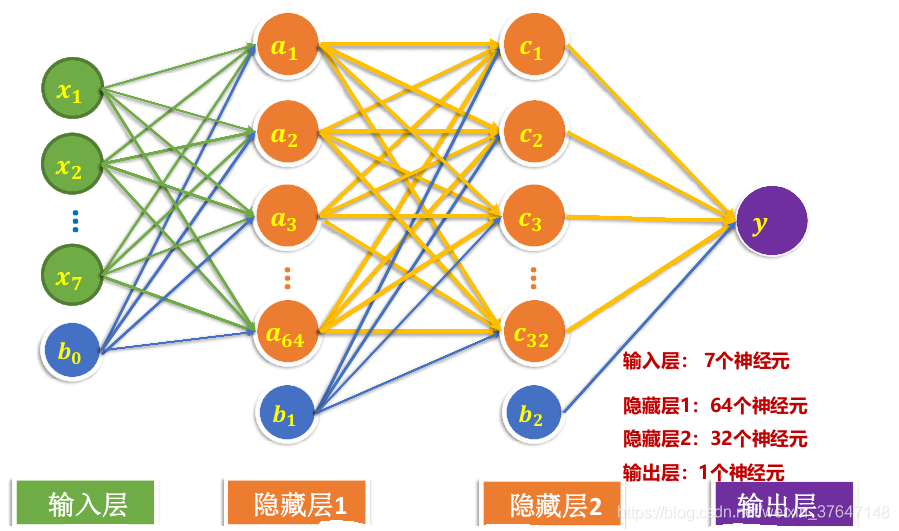
图4.1 本文采用的网络结构
4.2 Keras模型定义
因为本文用的是TensorFlow的高阶框架Keras,所以要先导入TensorFlow的库。引进后就可以用TensorFlow库的Keras包,建立一个Keras序列模型。有了Keras模型后,就可以按照图4.1设计的网络结构进行定义了。其中输入层权重初始化均使用“uniform”,偏置项初始化使用“zeros”,激活函数用“relu”。隐藏层2和输出层激活函数用“sigmoid”。如图4.2所示。其模型结构可通过summary显示如图4.3。由图4.3可以看出隐藏层1有64个输出,参数共有8x64=512个,同理知隐藏层2共有2080个参数,输出层有33个参数。

图4.2 Keras模型定义
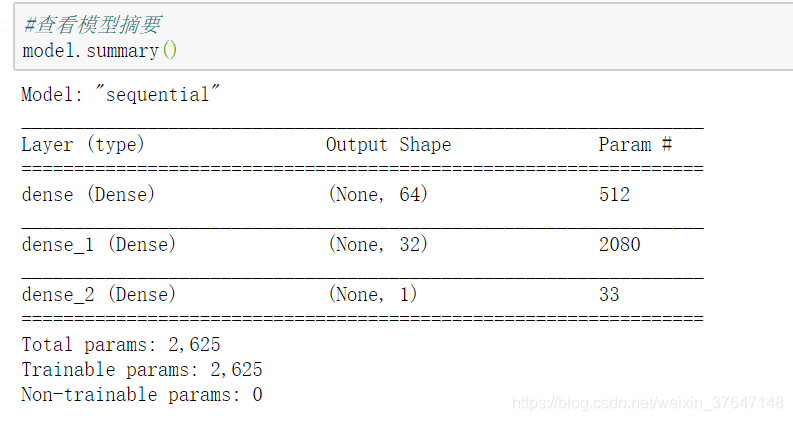
图4.3 模型结构
4.3 模型设置
优化器选择“Adam”,学习率设置为0.003.损失函数的选用原则如下:
1)若是用sigmoid作为激活函数,一般损失函数选用“binary_crossentropy”;
2)若是用softmax作为激活函数,一般损失函数选用“categorical_crossentropy”。
因为模型最终输出层输出的一个值,是一个回归模型,而不是一个多分类模型。因此本模型的损失函数,在这里使用二分交叉熵的方法,设置优化器,使得训练更加快捷和高效,同时用accuracy作为模型要训练和评估的度量值,即评估模型的方式是准确度。如图4.4所示。

图4.4 模型设置
4.4 模型训练
在Keras框架训练很简单,直接用model中的fit就可以了,把训练特征值和标签值加入fit中,进行训练。把训练数据分成两份,其中验证集所占比例为20%,迭代周期设置为100轮,每批次带入40行数据,显示方式为每一周期显示一次数据训练结果。训练过程如图4.5所示。可以看到在100轮迭代后,训练集准确率为82%,验证集准确度为81%。

图4.5 训练过程
4.5 可视化训练过程
model.fit()返回一个History对象,该对象包含一个字典,其中包括训练期间所发生的所有情况,字典模式这种,有验证集损失、验证集准确率、训练集损失和训练集4个条目对应训练和验证期间的一个受监控指标。我们可以使用这些指标绘制 训练损失与验证损失图标以进行对比,并绘制训练准确率与验证准确率图表。如图4.6,4.7所示。由图4.7可以看到,在20轮迭代后,训练集和验证集准确度就基本一致了,在往后面训练的过程中,虽然训练集的准确率还在提高,但是验证集准确度就基本不变了,直到在80轮之后,验证集准确度才有所提高。
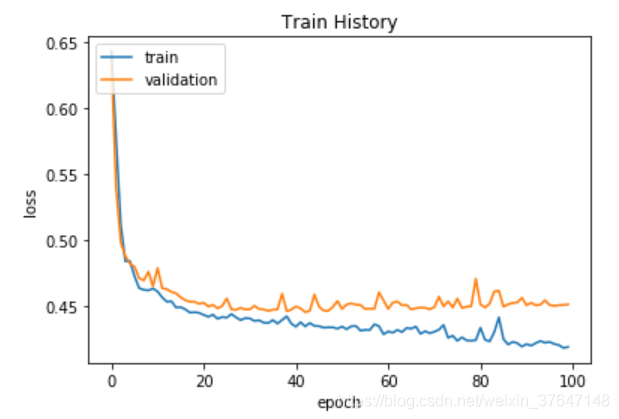
图4.6 损失值变化曲线

图4.7 准确率变化曲线
4.6 模型评估
当模型训练好后,我们就要进行模型的评估。在本次实验是用测试集上的数据来进行模型的评估。在Keras进行模型的评估很简单,Keras已经封装好了一个evaluate评估函数,这时候,只需要把测试集的数据加载进去即可。结果如图4.8所示。

图4.8 模型评估
4.7 模型应用
模型评估的准确率达到86%,基本达到我们的满意度,这时候,我们就可以应用模型来进行预测了。首先添加Jack和Rose的数据信息来进行预测。信息如下:Jack: 3等舱,男性,票价5,年龄23;Rose:头等舱,女性,票价100,年龄20。如图4.9所示。

图4.9 添加旅客
添加好数据后,再次执行数据预处理,比如把性别等转换为数字,对数据进行标准化处理等,然后使用model.predict执行预测操作。此外为了更好地查看预测结果,在数据表的最后一列插入生存概率。如图4.10显示的是后5个旅客的预测结果。
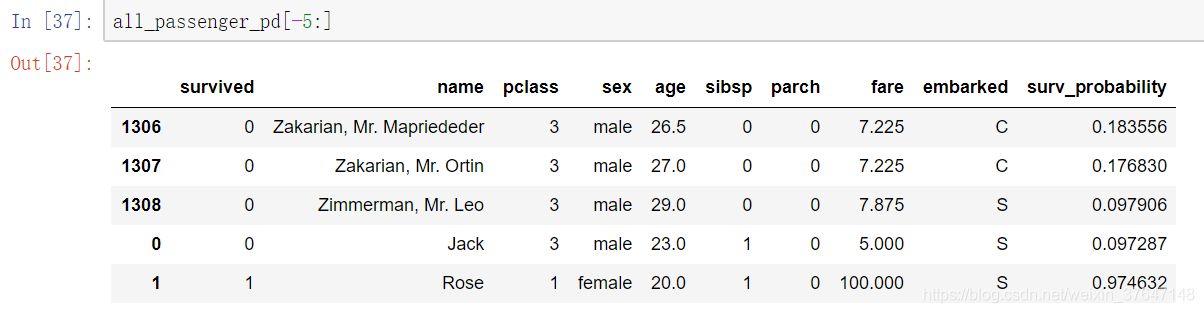
图4.10 预测结果
第5章 总结
本文研究了深度学习算法在图像分类方面的应用,简述了卷积神经网络以及经典模型。搭建神经网络结构,实现对泰坦尼克号上旅客生存概率预测。深度学习是机器学习领域内新型的学科,是近年来人工智能领域取得的最重要的突破之一。深度学习中的卷积神经网络算法效果好,适应性更强,但是它的缺点也是显而易见的,为了使神经网络具有较高的泛化能力,它需要大量数据作为训练样本,计算量也非常大。当前,随着大数据和人工智能时代的到来,基于深度学习的卷积神经网络这个课题提供了新的机遇和挑战,因此值得展开更深入的研究。
参考文献
[1] 高扬,卫峥.白话深度学习与TensorFlow[M].北京:机械工业出版社,2018.
[2] 邹伟,姚新新 译 基于TensorFlow的深度学习[M].北京:中国电力出版社,2019.
[3] 蒋子阳 TensorFlow深度学习算法原理与编程实战[M].北京:中国水利水电出版社,2019.
[4]李卫.深度学习在图像识别中的研究及应用[D].武汉:武汉理工大学,2014.
[5]丰晓流,基于深度学习的图像识别算法研究[D].太原:太原理工大学,2015.
[6]周凯龙,基于深度学习的图像识别应用研究[D].北京:北京工业大学,2016.
[7] https://www.cnblogs.com/jackhehe/p/9808368.html
[8] https://www.cnblogs.com/jackhehe/p/9808368.html
[9] http://blog.itpub.net/31509949/viewspace-2156472
[10] https://cloud.tencent.com/developer/article/1491393
[11] 胡貌男,邱康,谢本亮.基于改进卷积神经网络的图像分类方法[J].通信技术,2018,51(11):2594-2600.
[12] 卷积网络深度学习算法与实例[J].陈旭,张军,陈文伟,李硕豪.广东工业大学学报. 2017(06)
[13] 基于卷积神经网络的手写数字识别[J].李斯凡,高法钦.浙江理工大学学报(自然科学版). 2017(03)
[14] 一种改进的BP神经网络手写体数字识别方法[J].王燕.计算机工程与科学. 2008(04)
[15] 基于卷积神经网络图像分类优化算法的研究与验证[D].石琪.北京交通大学 2017
[16] https://www.jianshu.com/p/aac06d1fa626
[17] https://blog.csdn.net/hellocsz/article/details/88875304














 5610
5610











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









