







基于可识别训练的部件模型的目标检测
Object Detection with Discriminatively Trained Part Based Models
摘要
基于多尺度可变形的部件模型我们来描述一个目标检测系统。我们的系统能够表示高度可变的对象类并在PASCAL目标检测挑战达到最先进的结果。虽然可变形部件模型变得十分流行,但是它们的值至今没有在诸如PASCAL数据库这种困难的基准上证明。对于可区分训练,我们的系统依赖于使用部分标记的数据这种新方法。我们结合了一种对数据挖掘反例的高灵敏度的方法,使用一种我们称之为潜在支持向量机的形式。潜在的支持向量机是一种基于潜在变量的MI-SVM的重新生成。一个潜在的支持向量机是半凸的,一旦潜在的信息指定为正面例子,训练问题就会变成凸形。这就引出了一种迭代训练算法,该算法可以在为正例修正潜在值和优化潜在的SVM目标函数之间进行交替。。
目的:检测目标并给定类别考虑从静态图像中的人或汽车等类别检测和定位一般对象的问题。
难点:视角变化、光照因素、非刚性的形变、类内形变等。
多尺度可变形部件模型使用一个可区分的程序进行训练,仅需要一系列图像中目标的边界框。结果非常高效,在PASCAL VOC基准和INRIA行人数据集取得最好的效果。
图形结构框架
图形结构通过一个可变形配置中排列的部分集合来表示对象。每个部分都捕获一个对象的局部外观属性,而可变形的配置则以某些对部分之间的弹簧式连接为特征。
可变形模型抓取表面有意义的变量,可是单一的可变形模型在图像出现多个目标时表现得不够好。解决:混合模型处理多个有意义的变量信息
视觉语法
视觉语法是基于可变形模型的推广,用变量等级结构表示目标。基于模型中的语法的每一部分都能直接或间接被其他部分表示。模型间能共享不同类的信息。
简单的模型能够在实际中效果优于复杂的模型,因为后者在训练期间存在困难。对于目标检测来说,精确的模板和特征袋模型可以容易的使用SVM这样的可区分的方法实现。更丰富的模型却是比较难训练的,尤其是因为他们经常利用潜在的信息。因为部分未被标记,所以视为潜在的信息,但是利用标记的部分信息又会出现较差的训练结果(一旦标记的是次优的部分) 自动部分标记
DPM(Deformable Part Model,可变形部件模型)
DPM,一种基于组件的检测方法。该模型是由Felzenszwalb在2008年提出,以下是算法思想:
(1)Root filter+ Part filter
该模型包含了一个8*8分辨率的根滤波器(Root filter)(左)和4*4分辨率的组件滤波器(Part filter)(中)。其中,中图的分辨率为左图的2倍,并且Part filter的大小是Root filter的2倍,因此,看的梯度会更加精细。右图为其高斯滤波后的2倍空间模型。

Root filter Part filter 高斯滤波后的模型
(2)响应值score的计算
计算公式:
其中,分别为锚点的横坐标、纵坐标和尺度;
为根模型的响应分数;
为部件模型的响应分数;
为不同模型组件之间的偏移系数,加上这个偏移量使其与跟模型进行对齐;
表示组件模型的像素为原始的2倍,所以,锚点*2;
为锚点和理想检测点之间的偏移系数。
其部件模型的详细响应得分公式如下:
其中,为训练的理想模型的位置;
为组件模型的匹配得分;
为组件的偏移损失得分;
为偏移损失系数;
为组件模型的锚点和组件模型的检测点之间的距离;
简单的说,这个公式表明,组件模型的响应越高,各个组件和其相应的锚点距离越小,则响应分数越高,越有可能是待检测的物体。
(3)DPM特征定义
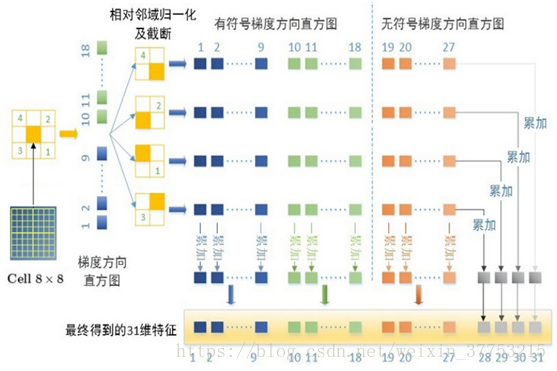
DPM首先采用的是HOG进行特征的提取,但是又有别于HOG。DPM中,只保留了HOG中的Cell。如上图所示,假设,一个8*8的Cell,将该细胞单元与其对角线邻域的4个细胞单元做归一化操作。
提取有符号的HOG梯度,0-360度将产生18个梯度向量,提取无符号的HOG梯度,0-180度将产生9个梯度向量。因此,一个8*8的细胞单元将会产生,(18+9)*4=108,维度有点高,Felzenszwalb给出了其优化思想。
首先,只提取无符号的HOG梯度,将会产生4*9=36维特征,将其看成一个4*9的矩阵,分别将行和列分别相加,最终将生成4+9=13个特征向量,为了进一步提高精度,将提取的18维有符号的梯度特征也加进来,这样,一共产生13+18=31维梯度特征。实现了很好的目标检测。
(4)检测流程
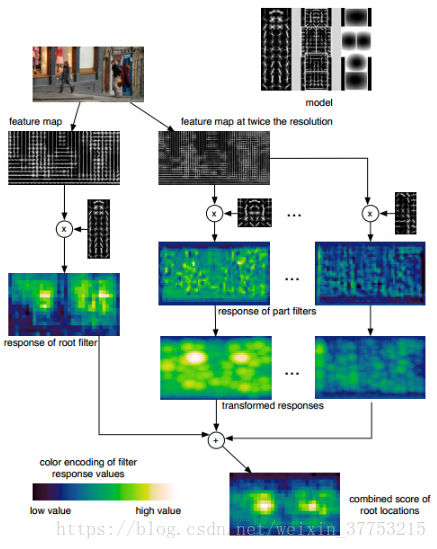
如上图所示,对于任意一张输入图像,提取其DPM特征图,然后将原始图像进行高斯金字塔上采样,然后提取其DPM特征图。对于原始图像的DPM特征图和训练好的Root filter做卷积操作,从而得到Root filter的响应图。对于2倍图像的DPM特征图,和训练好的Part filter做卷积操作,从而得到Part filter的响应图。然后对其精细高斯金字塔的下采样操作。这样Root filter的响应图和Part filter的响应图就具有相同的分辨率了。然后将其进行加权平均,得到最终的响应图。亮度越大表示响应值越大。
(5)Latent SVM

传统的HOG+SVM和DPM+ Latent SVM的区别如上面公式所示。
由于,训练的样本中,负样本集肯定是100%的准确的,而正样本集中就可能有噪声。因为,正样本的标注是人工进行的,人是会犯错的,标注的也肯定会有不精确的。因此,需要首先去除里面的噪声数据。而对于剩下的数据,里面由于各种角度,姿势的不一样,导致训练的模型的梯度图也比较发散,无规则。因此需要选择其中的具有相同的姿势的数据,即离正负样本的分界线最近的那些样本,将离分界线很近的样本称为Hard-examples,相反,那些距离较远的称为Easy-examples。
作者官网:http://www.rossgirshick.info/latent/
内有四个版本的DPM代码(最下方),我是运行了其中两个版本的代码
实验效果:
Version3: windows7+vs2013+matlab2015a
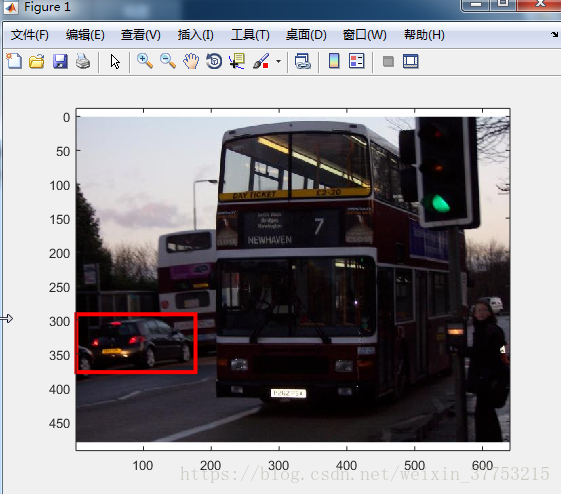
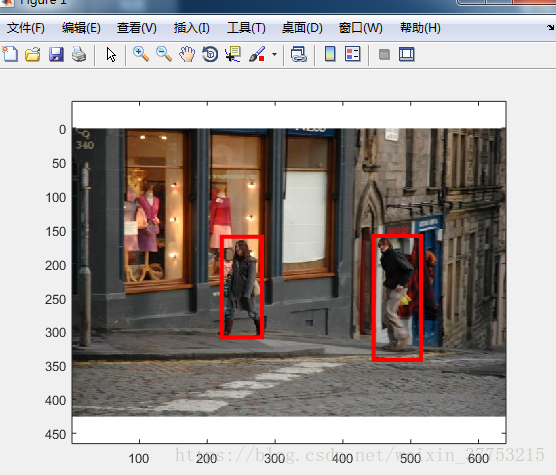
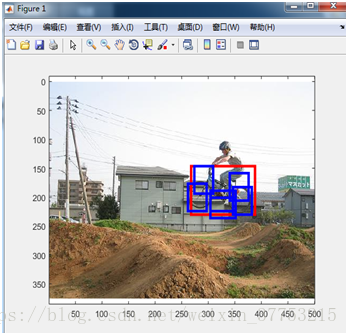
Version5: ubuntu16.04+vscode+matlab2015b
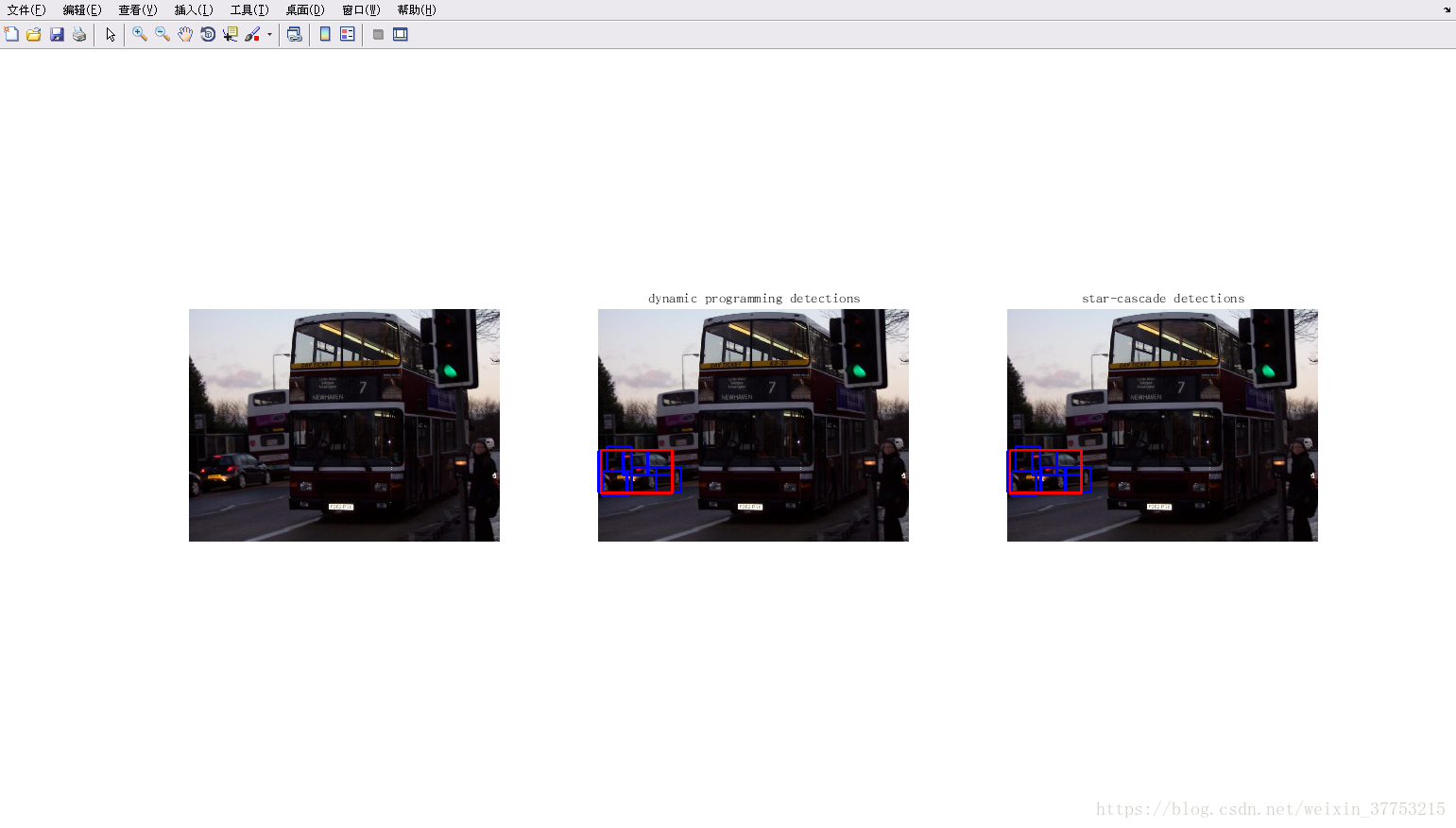
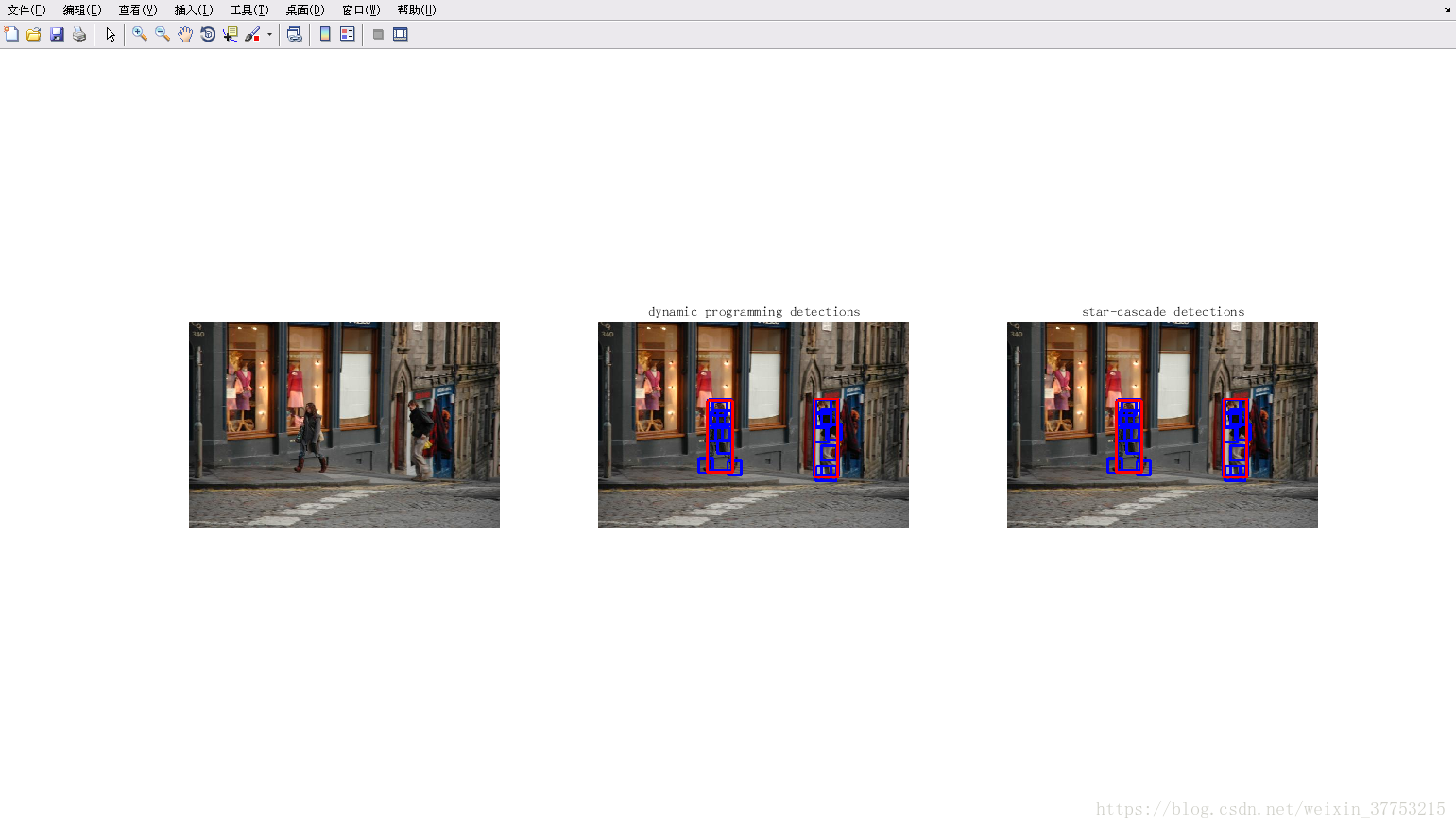
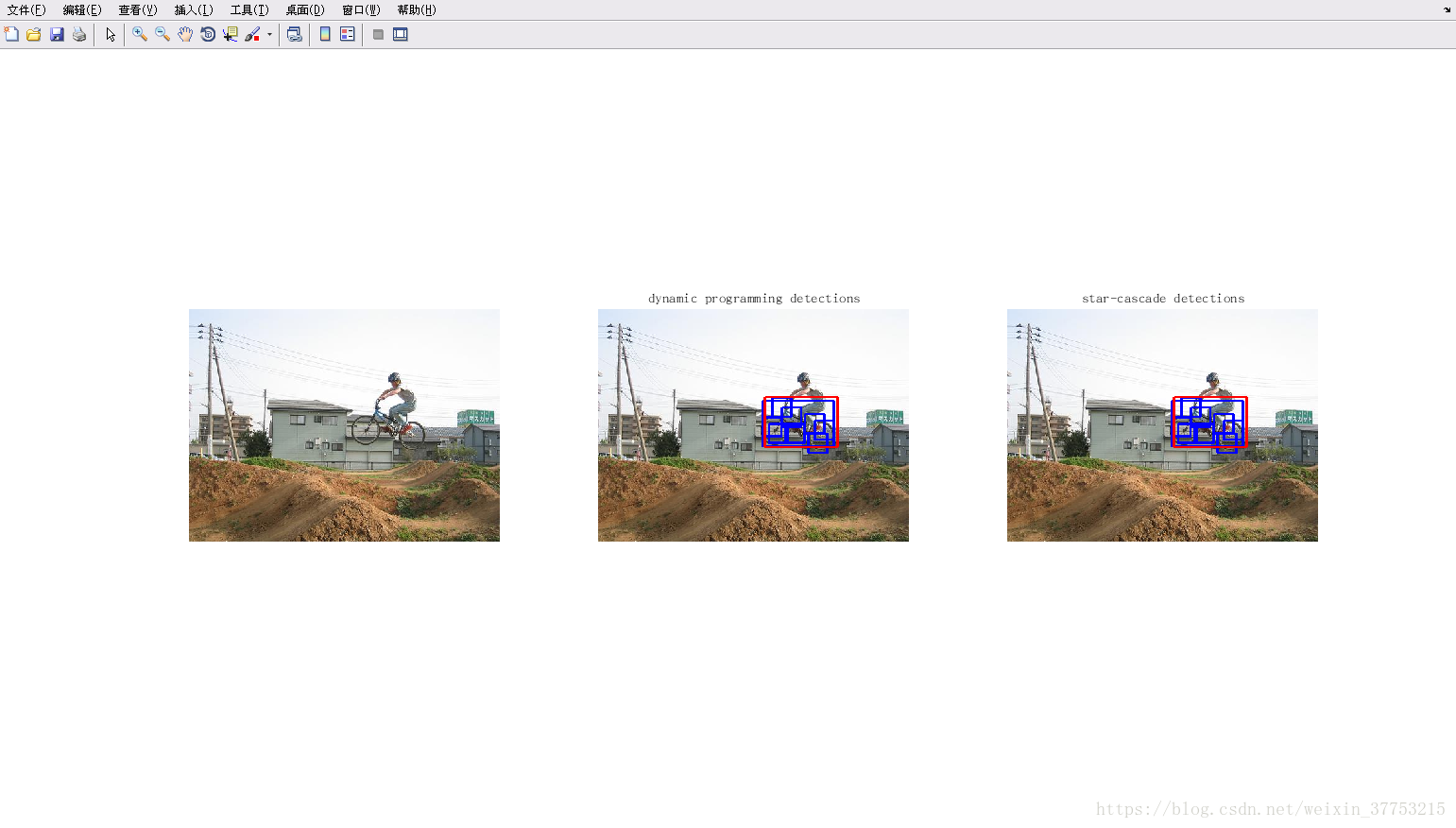
参考博客:http://blog.csdn.net/carson2005/article/details/22499565














 7万+
7万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









