





原标题:最全攻略:数据分析师必备Python编程基础知识
导读:本文主要介绍使用Python进行数据分析时必备的编程基础知识,主要涉及Python的基本数据类型、数据结构、程序控制、读写数据等内容。
Python编写代码时,是以缩进作为代码块的标识,而不是使用花括号等字符,这与其它语言有较大差别。这种方式显示的代码可读性更高,通常使用四个空格或一个tab作缩进,如果是Python编程的新手,要注意这一点。
作者:常国珍、赵仁乾、张秋剑
本文摘编自《Python数据科学:技术详解与商业实践》,如需转载请联系大数据(ID:hzdashuju)
01 Python的基本数据类型
Python的基本数据类型包括几种,如下表:
名称
解释
示例
str
字符串
'a',"1"
float
浮点数
1.23,11.0
int
整数
3,4
bool
布尔
True,False
complex
复数
1+2j,2+0j
▲表3-1 Python基础数据类型
下面一一进行详述。
1. 字符串(str)
Python中,单引号、双引号、三引号包围的都是字符串,如下所示:
'spam eggs'
'spam eggs'
"spam eggs"
'spam eggs'
'''spam eggs'''
'spam eggs'
type( 'spam eggs')
str
此外,Python中的字符串也支持一些格式化输出,例如换行符"n”和制表符"t”:
print( 'First line.nSecond line.')
First line.
Second line.
print( '1t2')
12
当然,有时候为避免混淆,也会使用转义字符"”,用于转义"”后一位的字符为原始输出。
""Yes," he said."
'"Yes," he said.'
此外还可以通过在引号前加r来表示原始输出:
print( 'C:somename') #有换行符的输出
C:some
Ame
print( r'C:somename') #原始输出
C:somename
Python中字符串支持加运算表示字符串拼接:
'pyt'+ 'hon'
'python'
2. 浮点数和整数(float,int)
Python可以处理任意大小的整数,当然包括负整数,在程序中的表示方法和数学上的写法一模一样。
1+ 1
2
Python支持数值的四则运算,如下所示:
1+ 1#加法
2
1-1#减法
0
1* 1#乘法
1
2** 2#2的2次方
4
2/ 3#除法
0.6666666666666666
5// 2#除法(整除)
2
5% 2#余数
1
Python可以处理双精度浮点数,可以满足绝大部分数据分析的需求,要精确空值数字精度,还可以使用numpy扩展库。
此外,可以使用内置函数进行数值类型转换,例如转换数值字符为数值:
float( "1")
1.0
int( "1")
1
3. 布尔值 (Bool:True/False)
Python布尔值一般通过逻辑判断产生,只有两个可能结果:True/False
整型、浮点型的"0”和复数0+0j也可以表示False,其余整型、浮点型、复数数值都被判断为True,如下代码通过逻辑表达式创建bool逻辑值:
1== 1
True
1> 3
False
'a'is'a'
True
当然,Python中提供了逻辑值的运算即"且”、"或”、"非”运算,
TrueandFalse#且
False
TrueorFalse#或
True
notTrue#非
False
布尔逻辑值转换可以使用内置函数bool,除数字0外,其他类型用bool转换结果都为True。
bool( 1)
False
bool( "0")
True
bool( 0)
False
Python中对象类型转换可参考表3-2。
数据类型
中文含义
转换函数
Str
字符串
str()
Float
浮点类型
float()
Int
整数
Int()
Bool
逻辑
bool()
Complex
复数
complex()
▲表3-2 Python数据类型转换
4. 其他
Python中,还有一些特殊的数据类型,例如无穷值,nan(非数值),None等。可以通过以下方式创建:
float( '-inf') #负无穷
-inf
float( '+inf') #正无穷
inf
下面是无穷值的一些运算,注意正负无穷相加返回nan(not a number),表示非数值
float( '-inf')+ 1
-inf
float( '-inf')/ -1
inf
float( '+inf')+ 1
inf
float( '+inf')/ -1
-inf
float( '-inf')+float( '+inf')
nan
非数值nan在Python中与任何数值的运算结果都会产生nan,nan甚至不等于自身。如下所示。nan可用于表示缺失值。
float( 'nan') == float( 'nan')
False
此外,python中提供了None来表示空,其仅仅支持判断运算,如下所示
x = None
x isNone
True
02 Python的基本数据结构
Python的基本数据类型包括以下几种,这些数据类型表示了自身在Python中的存储形式。在Python中可以输入type(对象)查看数据类型。
1. 列表(list)
1.1 列表简介
列表list是Python内置的一种数据类型,是一种有序的集合,用来存储一连串元素的容器,列表用[]来表示,其中元素的数据类型可不相同。
list1 = [ 1, '2', 3, 4]
list1
[ 1, '2', 3, 4]
除了使用"[]”创建列表外,还可以使用list()函数:
list([ 1, 2, 3])
[ 1, 2, 3]
list( 'abc')
[ 'a', 'b', 'c']
可以通过索引对访问或修改列表相应位置的元素,使用索引时,通过”[]”来指定位置。在Python中,索引的起始位置为0,例如取list1的第一个位置的元素:
list1[ 0]
1
可以通过”:”符号选取指定序列的位置的元素,例如取第1到第3个位置的元素,注意这种索引取数是前包后不包的(包括0位置,但不包括3位置,即取0,1,2位置的元素):
list1[ 0: 3]
[ 1, '2', 3]
此外,Python中的负索引表示倒序位置,例如-1代表list1最后一个位置的元素:
list1[ -1]
4
列表支持加法运算,表示两个或多个列表合并为一个列表,如下所示:
[ 1, 2, 3]+[ 4, 5, 6]
[ 1, 2, 3, 4, 5, 6]
1.2 列表的方法
Python中,列表对象内置了一些方法。这里介绍append方法和extend方法,append方法表示在现有列表中添加一个元素,在循环控制语句中,append方法使用较多,以下是示例:
list2 = [ 1, 2]
list2.append( 3)
list2
[ 1, 2, 3]
extend方法类似于列表加法运算,表示合并两个列表为一个列表:
list2 = [ 1, 2]
list2.extend([ 3, 4, 5])
list2
[ 1, 2, 3, 4, 5]
2. 元组(tuple)
元组与列表类似,区别在于在列表中,任意元素可以通过索引进行修改。而元组中,元素不可更改,只能读取。下面展示了元组和列表的区别,列表可以进行赋值,而同样的操作应用于元组则报错。
list0 = [ 1, 2, 3]
tuple0 = ( 1, 2, 3)
list0[ 1] = 'a'
list0
[ 1, 'a', 3]
tuple0[ 1] = 'a'
TypeError Traceback (most recent call last)
in()
----> 1tuple0[ 1] = 'a'
TypeError: 'tuple'object does notsupport item assignment
这里通过”()”创建元组,python中,元组类对象一旦定义虽然无法修改,但支持加运算,即合并元组。
( 1, 2, 3)+( 4, 5, 6)
( 1, 2, 3, 4, 5, 6)
元组也支持像列表那样通过索引方式进行访问。
t1 = ( 1, 2, 3)
t1[ 0]
1
t1[ 0: 2]
( 1, 2)
3. 集合(set)
Python中,集合(set)是一组key的集合,其中key不能重复。可以通过列表、字典或字符串等创建集合,或通过"{}”符号进行创建。Python中集合主要有两个功能,一个功能是进行集合操作,另一个功能是消除重复元素。
basket = { 'apple', 'orange', 'apple', 'pear', 'orange', 'banana'}
basket
{ 'apple', 'banana', 'orange', 'pear'}
basket = set([ 'apple', 'orange', 'apple', 'pear', 'orange', 'banana'])
basket
{ 'apple', 'banana', 'orange', 'pear'}
basket = set(( 'apple', 'orange', 'apple', 'pear', 'orange', 'banana'))
basket
{ 'apple', 'banana', 'orange', 'pear'}
Python支持数学意义上的集合运算,比如差集、交集、补集、并集等,例如如下集合:
A = { 1, 2, 3}
B = { 3, 4, 5}
A,B的差集,即集合A的元素去除AB共有的元素:
A – B
{ 1, 2}
A,B的并集,即集合A与集合B的全部唯一元素:
A | B
{ 1, 2, 3, 4, 5}
A,B的交集,即集合A和集合B共有的元素:
A & B
{ 3}
A,B的对称差,即集合A与集合B的全部唯一元素去除集合A与集合B的公共元素:
A ^ B
{ 1, 2, 4, 5}
需要注意集合不支持通过索引访问指定元素。
4. 字典(dict)
Python内置了字典dict,在其他语言中也称为map,使用键-值(key-value)存储,具有极快的查找速度,其格式是用大括号{}括起来key和value用冒号":”进行对应。例如以下代码创建了一个字典:
dict1 = { 'Nick': 28, 'Lily': 28, 'Mark': 24}
dict1
{ 'Lily': 28, 'Mark': 24, 'Nick': 28}
字典本身是无序的,可以通过方法keys和values取字典键值对中的键和值,如下所示:
dict1.keys()
[ 'Nick', 'Lily', 'Mark']
dict1.values()
[ 28, 28, 24]
字典支持按照键访问相应值的形式,如下所示:
dict1[ 'Lily']
28
这里需要注意定义字典时,键不能重复,否则重复的键值会替代原先的键值,如下所示,键’Lily’产生重复,其值被替换。
dict3 = { 'Nick': 28, 'Lily': 28, 'Mark': 24, 'Lily': 33}
{ 'Lily': 33, 'Mark': 24, 'Nick': 28}
03 Python的程序控制
程序控制结构是编程语言的核心基础,Python的编程结构有3种,本节将详细地介绍这3种结构。
1. 三种基本的编程结构简介
简单来说,程序结构分为三种:顺承结构、分支结构和循环结构(图3-1)。
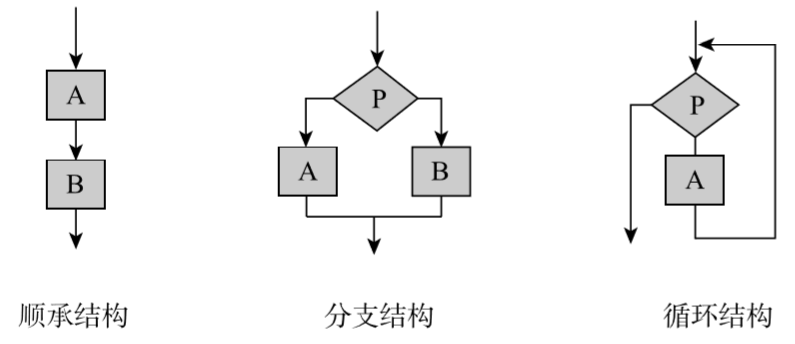
▲图3-1程序执行结构
顺承结构的程序特点是依照次序将代码一个一个地执行,并返回相应的结果,这种结构较为简单,易于理解;
分支结构的程序多出了条件判断,即满足某种条件就继续执行,否则跳转到另外的条件上进行执行;
循环结构用于处理可以迭代的对象,这种结构通过循环可迭代的对象,然后对每一个对象执行程序并产生结果。在迭代次数较多的情况下,使用顺承结构往往要写非常长的代码,而循环结构则非常简单。
这些结构中,分支结构往往需要条件判断语句进行控制,比如if、else等,而循环结构则需要循环语句for进行控制,当然分支结构与循环结构完全可以混合,这时就可以通过条件循环语句while进行控制。
下面我们具体看看这几个结构的程序。
2. 顺承结构
2.1 顺承结构
现在创建一个列表a:
a = [ 1, 2, 3, 4, 5]
需要打印列表a中的所有元素,可以有如下写法,虽然烦琐但完成了任务。这种顺序执行的编程结构就是顺承结构:
print(a[ 0])
print(a[ 1])
print(a[ 2])
print(a[ 3])
print(a[ 4])
1
2
3
4
5
2.2 逻辑行与物理行
Python中,代码是逐行提交给解释器进行编译的,这里的一行称为逻辑行,实际代码也确实是一行,那么代码的物理行就只有一行,例如上述print代码,逻辑行和物理行是统一的。
但某些情况下,编写者写入一个逻辑行的代码过长时,可以分拆为多个物理行执行,例如:
tuple(set(list([ 1, 2, 3, 4, 5, 6, 7, 8])))
( 1, 2, 3, 4, 5, 6, 7, 8)
可以写为如下方式,符号’’是换行的标识,此时代码还是一个逻辑行,但有两个物理行。
tuple(set(list([ 1, 2, 3,
4, 5, 6, 7, 8])))
( 1, 2, 3, 4, 5, 6, 7, 8)
当多个逻辑行代码过短时:
x = 1
y = 2
z = 3
print(x,y,z)
( 1, 2, 3)
可以使用分号";”将多个逻辑行转化为一个物理行执行:
x = 1;y = 2;z = 3;print(x,y,z)
( 1, 2, 3)
3. 分支结构
分支结构的分支用于进行条件判断,Python中,使用if 、elif、else、冒号与缩进表达。详细语法可见以下示例,下面的语法的判断逻辑为 :
若数值x小于0,令x等于0,若成立则打印信息'Negative changed to zero';
若第一个条件不成立,判断x是否为0,若成立打印'Zero';
若第一、第二个条件不成立,再判断x是否为1,若成立打印’single’;
若第一、第二、第三个条件都不成立,打印’more’。
以x=-2测试结果:
x = -2
ifx < 0:
x = 0
print( 'Negative changed to zero')
elifx == 0:
print( 'Zero')
elifx == 1:
print( 'Single')
else:
print( 'More')
'Negative changed to zero'
这里,if,elif,else组成的逻辑是一个完整的逻辑,即程序执行的时,任何条件成立时,会停止后面的条件判断。这里需注意,当多个if存在时的条件判断的结果:若把上述代码中的elif改为if后,程序执行的结果会发生变化,如下所示:
x = -2
ifx < 0:
x = 0
print( 'Negative changed to zero')
ifx == 0:
print( 'Zero')
ifx == 1:
print( 'Single')
else:
print( 'More')
'Negative changed to zero'
'Zero'
'More'
此时,上述程序的中任何if判断结果无论是否成立都会依次执行一遍,所以x=-2会被赋值为0后继续执行,第二个if判断为真,第三个if判断为假时,再跳到else进行执行,此时第三个if和else才是一个完整的逻辑。在写条件判断结构的程序时需要注意。
4. 循环结构
这里介绍Python中的for循环结构和while循环结构,循环语句用于遍历枚举一个可迭代对象的所有取值或其元素,每一个被遍历到的取值或元素执行指定的程序并输出。这里可迭代对象指可以被遍历的对象,比如列表、元组、字典等。
4.1 For循环
下面是一个for循环的例子, i用于指代一个可迭代对象中a中的一个元素,for循环写好条件后以冒号结束,并换行缩进,第二行是针对每次循环执行的语句,这里是打印列表a中的每一个元素。
a = [ 1, 2, 3, 4, 5]
fori ina:
print(i)
1
2
3
4
5
上述操作也可以通过遍历一个可迭代对象的索引来完成,a列表一共5个元素,range(len(a))表示生成a的索引序列,这里打印索引并打印a向量索引下的取值。
a = [ 'Mary', 'had', 'a', 'little', 'lamb']
fori inrange(len(a)):
print(i, a[i])
( 0, 'Mary')
( 1, 'had')
( 2, 'a')
( 3, 'little')
( 4, 'lamb')
4.2 while循环
while循环一般会设定一个终止条件,条件会随着循环的运行而发生变化,当条件满足时,循环终止。while循环可以通过条件制定循环次数,例如通过计数器来终止掉循环,如下所示,计数器count每循环一次自增1,但count为5时,while条件为假,终止循环。
count = 1
whilecount < 5:
count = count + 1
print(count)
2
3
4
5
以下是一个比较特殊的示例,演示如何按照指定条件循环而不考虑循环的次数,例如编写循环,使x不断减少,当x小于0.0001时终止循环,如下所示,循环了570次,最终x取值满足条件,循环终止。
x= 10
count = 0
whileTrue:
count = count + 1
x = x - 0.02*x
ifx< 0.0001:
break
print(x,count)
( 9.973857171889038e-05, 570)
4.3 break、continue、pass
上例中while循环代码中使用了break表示满足条件时终止循环。此外,也可通过continue、pass对循环进行控制。Continue表示继续进行循环,例如如下代码尝试打印10以内能够被3整除的整数,注意continue和break的区别:
count = 0
whilecount < 10:
count = count + 1
ifcount % 3== 0:
print(count)
continue
3
6
9
使用break:
count = 0
whilecount < 10:
count = count + 1
ifcount % 3== 0:
print(count)
break
3
pass语句一般是为了保持程序的完整性而作为占位符使用,例如以下代码中pass没有任何操作。
count = 0
whilecount < 10:
count = count + 1
ifcount % 3== 0:
pass
else:
print(count)
1
2
4
5
7
8
10
4.4 表达式
在Python中,诸如列表、元组、集合、字典都是可迭代对象,Python为这些对象的遍历提供了更加简洁的写法。例如如下列表对象x的遍历,且每个元素取值除以10:
x = [ 1, 2, 3, 4, 5]
[i/ 10fori inx]
[ 0.1, 0.2, 0.3, 0.4, 0.5]
上述[i/10 for i in x]的写法称为列表表达式,这种写法比for循环更加简便。此外对于元组对象、集合对象、字典对象,这种写法依旧适用,最终产生一个列表对象。
x = ( 1, 2, 3, 4, 5) #元组
[i/ 10fori inx]
[ 0.1, 0.2, 0.3, 0.4, 0.5]
x = set(( 1, 2, 3, 4, 5)) #集合
[i/ 10fori inx]
[ 0.1, 0.2, 0.3, 0.4, 0.5]
x = { 'a': 2, 'b': 2, 'c': 5} #字典
[i fori inx.keys()]
[ 'a', 'c', 'b']
[i fori inx.values()]
[ 1, 3, 2]
此外Python还支持集合表达式与字典表达式用于创建集合、字典,例如如下形式创建集合:
{i fori in[ 1, 1, 1, 2, 2]}
{ 1, 2}
字典表达式可以以如下方式创建:
{key:value forkey,value in[( 'a', 1),( 'b', 2),( 'c', 3)]}
{ 'a': 1, 'b': 2, 'c': 3}
04 Python的函数与模块
1. Python的函数
函数是用来封装特定功能的实体,可对不同类型和结构的数据进行操作,达到预定目标。像之前的数据类型转换函数入str,float等就属于函数。当然除了python的内置函数与第三方库的函数外,还可以自定义函数从而完成指定任务。
1.1 自定义函数示例
例如自定义求一个列表对象均值的函数avg,sum与len函数是python内置函数,分别表示求和与长度:
defavg(x):
mean_x = sum(x)/len(x)
return(mean_x)
运行完毕后,就可以调用该函数进行运算了:
avg([ 23, 34, 12, 34, 56, 23])
30
1.2 函数的参数
函数的参数可以分为形式参数与实际参数,形式参数,形式参数作用于函数的内部,其不是一个实际存在的变量,当接受一个具体值时(实际参数),负责将具体值传递到函数内部进行运算,例如之前定义的函数avg,形式参数为x。
defavg(x):
mean_x = sum(x)/len(x)
return(mean_x)
实际参数即具体值,通过形式参数传递到函数内部参与运算并输出结果,刚才的例子中,实际参数为一个列表:
>avg([ 23, 34, 12, 34, 56, 23])
函数参数的传递有两种方式:按位置和按关键字。当函数的形式参数过多时,一般采用按关键字传递的方式,通过形式参数名=实际参数的方式传递参数,如下所示,函数age有四个参数,可以通过指定名称的方式使用,也可按照顺序进行匹配:
defage(a,b,c,d):
print(a)
print(b)
print(c)
print(d)
age(a = 'young',b = 'teenager',c = 'median',d = 'old') #按关键字指定名称
young
teenager
median
old
age( 'young', 'teenager', 'median', 'old') #按位置顺序匹配
young
teenager
median
old
函数的参数中,亦可以指定形式参数的默认值,此时该参数称为可选参数,表示使用时可以不定义实际参数,例如如下例子,函数f有两个参数,其中参数L指定了默认值None:
deff(a, L=None):
ifL isNone:
L = []
L.append(a)
returnL
使用该函数时,只需指定a参数的值,该函数返回一个列表对象,若不给定初始列表L,则创建一个列表,再将a加入到列表中:
f( 3)
[ 3]
也可指定可选参数L的取值:
f( 3,L = [ 1, 2])
[ 1, 2, 3]
1.3 匿名函数lambda
Python中设定了匿名函数lambda,简化了自定义函数定义的书写形式。使得代码更为简洁。例如通过lambda函数定义一个函数g:
g = lambdax:x+ 1
g( 1)
2
该函数相当于如下自定义函数:
defg(x):
return(x+ 1)
g( 1)
2
2. Python的模块
为了编写可维护的代码,可以把很多函数分组,分别放到不同的文件里,这样,每个文件包含的代码就相对较少,很多编程语言都采用这种组织代码的方式。在Python中,一个.py文件就称之为一个模块(Module),其内容形式是文本,可以在IDE中或者使用常用的文本编辑器进行编辑。
自定义模块
使用文本编辑器创建一个mod.py文件,其中包含一个函数,如下所示:
# module
defmean(x):
return(sum(x)/len(x))
使用自定义模块时,将mod.py放置在工作目录下,通过"import 文件名”命令载入:
importmod
在使用该模块的函数时,需要加入模块名的信息,如下:
mod.mean([ 1, 2, 3])
2
载入模块还有很多方式,如下(注意别名的使用):
importmod asm # as后表示别名
m.mean([ 1, 2, 3])
2
frommodimport mean #从mod中载入指定函数mean
mean([ 1, 2, 3])
2
frommodimport * # 从mod中载入所有函数
mean([ 1, 2, 3])
2
载入第三方库
import命令还可以载入已经下载好的第三方库,使用方式与上面所展示的一致。例如,载入numpy模块:
importnumpyas np
此时就可以使用Numpy模块中的函数了,例如Numpy中提供的基本统计函数:
x = [ 1, 2, 3, 4, 5]
np.mean(x) # 均值
3.0
np.max(x) # 最大值
5
np.min(x) # 最小值
1
np.std(x) # 标准差
1.41421356237
np.median(x) # 中位数
3.0
Numpy提供了强大的多维数组、向量、稠密矩阵、稀疏矩阵等对象,支持线性代数、傅里叶变换等科学运算,提供了C/C++及Fortron代码的整合工具。
Numpy的执行效率要比Python自带的数据结构要高效的多,在Numpy的基础上,研究者们开发了大量用于统计学习、机器学习等科学计算的框架,基于Numpy的高效率,这些计算框架具备了较好的实用性。可以说, Numpy库极大地推动了Python在数据科学领域的流行。
若不太清楚如何使用Python 中(含第三方包和库)的方法和对象,可以查阅相关文档或使用帮助功能,代码中获取帮助信息的方式有多种,比如如下几种:
?np.mean
??np.mean
help(np.mean)
np.mean??
05 pandas 读取结构化数据
Numpy中的多维数组、矩阵等对象具备极高的执行效率,但是在商业数据分析中,我们不仅需要一堆数据,还需要了解各行、列的意义,同时会有针对结构化数据的相关计算,这些是Numpy不具备的。为了方便分析,研究者们开发了Pandas用于简化对结构化数据的操作。
Pandas是一个基于Numpy开发的更高级的结构化数据分析工具,提供了Series、DataFrame、Panel等数据结构,可以很方便地对序列、截面数据(二维表)、面板数据进行处理。
DataFrame即是我们常见的二维数据表,包含多个变量(列)和样本(行),通常称为数据框;Series是一个一维结构的序列,会包含指定的索引信息,可以视作是DataFrame中的一列或一行,操作方法与DataFrame十分相似;Panel是包含序列及截面信息的三维结构,通常称为面板数据,通过截取会获得对应的Series和DataFrame。
由于这些对象的常用操作方法是十分相似的,本节读取与保存数据以及后续章节进行的数据操作,都主要使用DataFrame进行演示。
1. 读取数据
1.1 使用Pandas读取文件
Python的Pandas库提供了便捷读取本地结构化数据的方法,这里主要以csv数据为例。pandas.read_csv函数可以实现读取csv数据,读取方式见以下代码,其中'data/sample.csv'表示文件路径:
importpandas aspd
csv = pd.read_csv( 'data/sample.csv')
csv
id name scores
01小明 78.0
12小红 87.0
23小白 99.0
34小青 99999.0
45小兰 NaN
按照通常的惯例,Pandas会以pd做为别名,pd.read_csv读取指定路径下的文件,然后返回一个DataFrame对象。在命令行中打印DataFrame对象其可读性可能会略差一些,如果在jupyter notebook 中执行的话,则DataFrame的可读性会大幅提升:
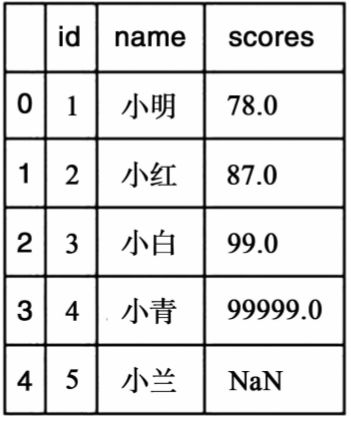
▲图3-2 jupyter notebook中的DataFrame展现
打印出来的DataFrame包含了索引(index,第一列),列名(column,第一行)及数据内容(values,除第一行和第一列之外的部分)。
此外,read_csv函数有很多参数可以设置,这里列出常用参数,如表3-3所示。
参数
说明
filepath_or_buffer
csv文件的路径
sep = ','
分隔符,默认逗号
header = 0
int或list of ints类型,0代表第一行为列名,若设定为None将使用数值列名
names = [...]
list,重新定义列名,默认None
usecols = [...]
list,读取指定列,设定后将缩短读取数据的时间与内存消耗,适合大数据量读取,默认None
dtype = {...}
dict,定义读取列的数据类型,默认None
nrows = None
int类型,指定读取大数据量的前多少行,默认None
na_values = ...
str类型,list或dict,指定读取为缺失值的值
na_filter = True
bool类型,自动发现数据中的缺失值功能,默认打开(True),若确定数据无缺失可以设定为False以提高数据载入的速度
chunksize = 1000
int类型,分块读取,当数据量较大时可以设定分块读取的行数,默认为None,若设定将返回一个迭代器
encoding = 'utf-8'
str类型,数据的编码,python3默认为'utf-8',python2默认为'ascii'
▲表3-3 pandas.read_csv参数一览
Pandas除了可以直接读取csv、Excel、Json、html等文件生成DataFrame,也可以从列表、元组、字典等数据结构创建DataFrame,
1.2 读取指定行和指定列
使用参数usecol和nrows读取指定的列和前n行,这样可以加快数据读取速度。如下所示,读取原数据的两列、两行:
csv = pd.read_csv( 'data/sample.csv',
usecols=[ 'id', 'name'],
nrows= 2) #读取'id'和'name'两列,仅读取前两行
csv
id name
01小明
12小红
1.3 使用分块读取
参数chunksize可以指定分块读取的行数,此时返回一个可迭代对象,这里big.csv是一个4500行4列的csv数据,这里设定chunksize=900,分5块读取数据,每块900行,4个变量,如下所示:
csvs = pd.read_csv( 'data/big.csv',chunksize= 900)
fori incsvs:
print(i.shape)
( 900, 4)
( 900, 4)
( 900, 4)
( 900, 4)
( 900, 4)
可以使用pd.concat函数再读取全部数据。
csvs = pd.read_csv( 'data/big.csv',chunksize= 900)
dat = pd.concat(csvs,ignore_index= True)
dat.shape
( 4500, 4)
1.4 缺失值操作
使用na_values参数指定预先定义的缺失值,数据sample.csv中,"小青”的分数有取值为99999的情况,这里令其读取为缺失值,操作如下
csv = pd.read_csv( 'data/sample.csv',
na_values= '99999')
csv
id name scores
01小明 78.0
12小红 87.0
23小白 99.0
34小青 NaN
45小兰 NaN
1.5 文件编码
读取数据时,常遇到乱码的情况,这里需要先弄清楚原始数据的编码形式是什么,再以指定的编码形式进行读取,例如sample.csv编码为'utf-8',这里以指定编码(参数encoding)读取。
csv = pd.read_csv( 'data/sample.csv',
encoding= 'utf-8')
csv
id name scores
01小明 78.0
12小红 87.0
23小白 99.0
34小青 99999.0
45小兰 NaN
2. 写出数据
pandas的数据框对象有很多方法,其中方法"to_csv”可以将数据框对象以csv格式写入到本地中。to_csv方法的常见参数见表3-4:
参数
解释
path_or_buf
写到本地csv文件的路径
sep = ','
分隔符,默认逗号
na_rep = ''
缺失值写入代表符号,默认''
header = True
bool,是否写入列名,默认True
cols = [...]
list,写入指定列,默认None
index = True
bool,是否将行数写入指定列,默认true
encoding = str
str,以指定编码写入
▲表3-4 pandas.to_csv参数一览
例如以以下方式写出,'data/write.csv'表示写出的路径,encoding = 'utf-8'表示以'utf-8'编码方式输出,index=False表示不写出索引列。
csv.to_csv( 'data/write.csv',encoding= 'utf-8',ind
关于作者:常国珍,数据科学专家和金融技术专家。北京大学会计学博士,中国大数据产业生态联盟专家委员会委员。
赵仁乾,数据科学家,在电信大数据和机器学习领域有丰富的实践经验。
张秋剑,大数据专家和金融行业技术专家,上海师范大学计算机科学技术硕士。
本文摘编自《Python数据科学:技术详解与商业实践》,经出版方授权发布。
延伸阅读《Python数据科学》
点击上图了解及购买
转载请联系微信:togo-maruko
推荐语:本书从3个维度展开,技术维度:全面讲解数据分析、数据挖掘和机器学习的核心技术;业务维度,围绕具体的业务生命周期展开技术知识点的讲解;实践维度,列举的全部是商业案例,通过案例为数据科学从业者提供工作模板。
▼
Q:最基础的编程技巧你都搞定了吗?
转载 / 投稿请联系:baiyu@hzbook.com返回搜狐,查看更多
责任编辑:
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









