





原标题:Python之timeit模块:查看程序运行时间
本文作者:徐露露
文字编辑:张梦婷
技术总编:刘洪儒


阅读原文”下载爬虫俱乐部用户问题登记表并按要求填写后发送至邮箱statatraining@163.com,我们会及时为您解答哟~爬虫俱乐部的github主站正式上线了!我们的网站地址是:https://stata-club.github.io

在有些情况下,我们可能需要查看程序运行时间或者是通过运行时间来比较几个不同算法之间的执行效率的差异。我们一般都会想到使用时间模块time来计算,除了这个模块,timeit也同样非常好用,所以今天就给大家介绍一下timeit模块。
★ 问题导入 ★
假设现在我们有一个小问题,需要我们从一个容量非常大的字符串数组中筛选出以"foo”开头的元素。我想到了两个算法可以解决这个问题,一个是string.startswith("foo’),另一个是string[:3]==’foo’。那么在Python中到底哪个运行速度更快呢?
首先我们先针对这两种解决方法分别来编写函数:
def method1(): strings = [ 'foo', 'foobar', 'baz', 'qux', 'python', 'Guido Van Rossum'] * 100000result=[x forx instrings if x.startswith( 'foo')]
returnresultdef method2(): strings = [ 'foo', 'foobar', 'baz', 'qux', 'python', 'Guido Van Rossum'] * 100000result=[x forx instrings ifx[: 3] == 'foo']
returnresult
从这两个函数的输出结果上看,它们的功能都是一样,都是从一个非常长的列表中检索出特定特征的元素,并归结为新列表返回。如果我们采用time模块计算两种函数耗时的话,程序如下:
start_time= time.time()method1()end_time= time.time()print( 'method1所用时间:',end_time-start_time)start_time= time.time()method2()end_time= time.time()print( 'method2所用时间:',end_time-start_time)
得到结果为:
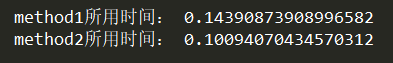
可以发现,第二种方法所用的时间更短,但是每测试一个方法我们都需要设置开始时间start_time和结束时间end_time,这似乎有些麻烦,除此之外,如果我们还想知道测试该程序运行多次所用的时间,或者整个实验重复多次分别花费的时间,我们该怎么办呢?timeit就能很好地帮助我们解决这个问题。
★ timeit模块 ★
timeit模块可以准确测量小段代码的执行时间,主要有以下这两个函数:
函数一:
timeit(stmt= 'pass', setup= 'pass',timer=, number= 1000000)
返回:
返回执行stmt这段代码number遍所用的时间,单位为秒,float型。
参数:
stmt:要执行的那段代码;
setup:执行代码的准备工作,不计入时间,一般是import之类的;
timer:在win32下是time.clock(),linux下是time.time(),为默认选项;
number:要执行stmt多少遍。
函数二:
repeat(stmt= 'pass', setup= 'pass',timer=, repeat= 3, number= 1000000)
这个函数比timeit函数多了一个repeat参数,它表示重复执行timeit这个过程多少遍,返回一个列表,表示执行每遍的时间。
★ 实战操作 ★
Step1.两种方法重复执行10次的时间
importtimeita= timeit.timeit(stmt=method1,number= 10) #method1程序重复执行 10次b= timeit.timeit(stmt=method2,number= 10)print( 'method1所用时间:',a)print( 'method2所用时间:',b)
得到:

Step2.该实验重复3次,获取其最小值
fromtimeit importrepeatt= repeat( 'method2()', 'from __main__ import method2',number= 10,repeat= 3)print(t)print( '3次试验中最小值为:',min(t))
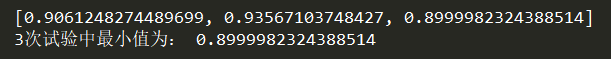
由于电脑永远都有其他程序也在占用着资源,你的程序不可能最高效的执行,所以一般都会进行多次试验,取最少的执行时间为真正的执行时间。


对爬虫俱乐部的推文累计打赏超过1000元我们即可给您开具发票,发票类别为"咨询费”。用心做事,只为做您更贴心的小爬虫!
关于我们
微信公众号"爬虫俱乐部”分享实用的stata命令,欢迎转载、打赏。爬虫俱乐部是由李春涛教授领导下的研究生及本科生组成的大数据分析和数据挖掘团队。
投稿要求:
1)必须原创,禁止抄袭;
2)必须准确,详细,有例子,有截图;
注意事项:
1)所有投稿都会经过本公众号运营团队成员的审核,审核通过才可录用,一经录用,会在该推文里为作者署名,并有赏金分成。
2)邮件请注明投稿,邮件名称为"投稿+推文名称”。
3)应广大读者要求,现开通有偿问答服务,如果大家遇到关于stata分析数据的问题,可以在公众号中提出,只需支付少量赏金,我们会在后期的推文里给予解答。返回搜狐,查看更多
责任编辑:















 1667
1667











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









