









Lecture 14 | Deep Reinforcement Learning
- What is Reinforcement Learning?
- Markov Decision Processes
- Q-Learning
- Policy Gradients

Cart-Pole Problem

Robot Locomotion

Atari Games

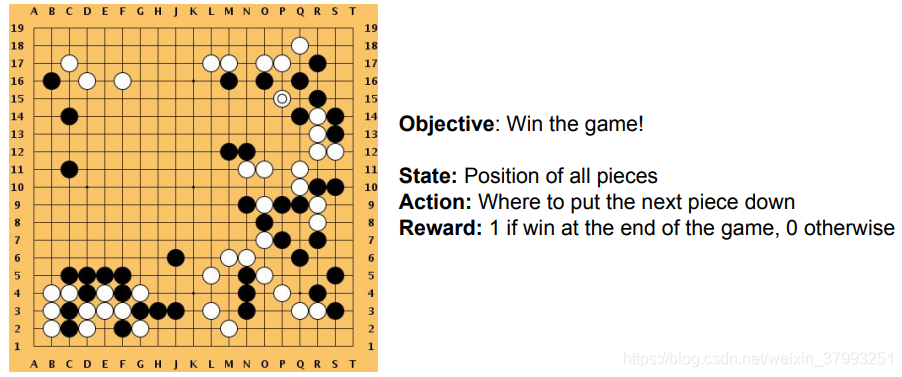
GO
Markov Decision Process


A simple MDP: Grid World


Definitions: Value function and Q-value function

Bellman equation

Solving for the optimal policy

Solving for the optimal policy: Q-learning

Case Study: Playing Atari Games

Q-network Architecture

Training the Q-network: Loss function (from before)

Training the Q-network: Experience Replay

Putting it together: Deep Q-Learning with Experience Replay

Policy Gradients


REINFORCE algorithm


Intuition

Variance reduction

Variance reduction: Baseline

How to choose the baseline?

Actor-Critic Algorithm

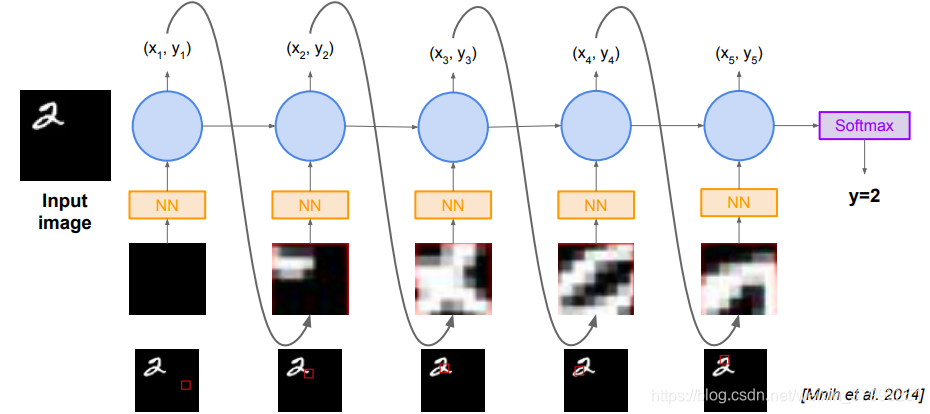
REINFORCE in action: Recurrent Attention Model (RAM)














 9万+
9万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









