







在复杂分布式系统中,需要对大量的数据和消息进行唯一标识。传统的数据库自增主键,或者单体的自增主键,已经不能满足需求。分布式ID能够快速稳定生成唯一的主键,生成ID时不依赖于数据库,完全在内存生成,高性能高可用,每秒可生成几百万ID。并且实现了多种类型的生成方式,可以根据需要自由配置使用
算法:分布式id生成算法SnowFlake
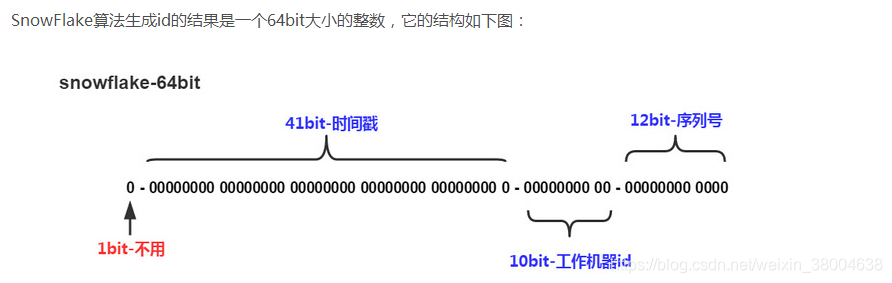
符号位说明:
第一位为不能为负的符号位:0
时间戳说明:
41位记录时间戳timeMillis,不是存储当前时间的时间截,而是存储时间截的差值,即当前系统时间 - 默认固定时间的值(开始时间截一般是我们的id生成器开始使用的时间,由我们程序来指定的)
工作机器ID说明:
10位的数据机器位id,可以部署在1024个节点,即datacenterId (5位数据id) + workerId (5位机器id)
datacenterId 与 workerId的最大值十进制值是31(不能为负数)
原因:5位数的最大二进制表示: 0001 1111 —> 十进制:31
序列号说明:
12位自增序列号sequence,毫秒内的计数,12位的计数顺序号支持每个节点每毫秒(同一机器,同一时间截)产生4096个ID序号
Sequence的最大十进制值是4095(不能为负数)
原因:12位数的最大二进制表示:1111 1111 1111 —> 十进制:4095
二进制说明:
按位或,按位与,异或计算例子:

位移说明:

计算所需默认常量:
默认固定时间twepoch: 1288834974657(毫秒)(小于当前时间即可,不能出现负数)
时间戳偏移位数 timestampLeftShift:22(给5位机器id、5位数据id、12位序列号移除位置)
数据id偏移位数 datacenterIdShift:17(给5位数据id、12位序列号移除位置)
机器id偏移位数 workerIdShift:12(给12位序列号移除位置)
开始计算:
一,需要输入的条件(以这4个数据为例):
- 当前时间 timwstamp:1563244877076(毫秒)
- 机器id workerId:6(本机ip)
- 数据id datacentId:20(当前进程Hashmap)
- 序列号sequence:0(自增序列号)
二,计算:
计算公式

步骤:
1.首先计算时间戳;即:timeMillis = timestamp(当前时间) – twepoch(固定时间)
timeMillis : 1563244877076 – 1288834974657 = 274409902419
2.再先分别计算左位移结果
timeMillis << timestampLeftShift
转换: 274409902419 << 22
二进制: 0011111111100100000110101101000101010011 << 22
//位移前
0000 0000 0000 0000 0000 0000 0011 1111 1110 0100 0001 1010 1101 0001 0101 0011
//位移22位后的结果(标记:a)
0000 1111 1111 1001 0000 0110 1011 0100 0101 0100 1100 0000 0000 0000 0000 0000
datacenterId << datacenterIdShift
转换: 20 << 17
二进制:0001 0100 << 17
//位移前
0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0001 0100
//位移17位后的结果(标记:b)
0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0010 1000 0000 0000 0000 0000
workerId << workerIdShift
转换:6 << 12
二进制:0000 0110 << 12
//位移前
0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0110
//位移12位后的结果(标记:c)
0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0110 0000 0000 0000
3.最后计算按位或的结果
计算公式带入值:
274409902419 << 22 |
20 << 17 |
6 << 12 |
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 4946
4946











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









