







目录
1. 创建数组的几种方式
本文技术工具来自技术群小伙伴的分享,想加入按照如下方式
目前开通了技术交流群,群友已超过3000人,添加时最好的备注方式为:来源+兴趣方向,方便找到志同道合的朋友
方式①、添加微信号:dkl88191,备注:来自CSDN+技术交流
方式②、微信搜索公众号:Python学习与数据挖掘,后台回复:加群+CSDN
1.0. 引入Numpy库
#引入numpy库
import numpy as np
1.1. 使用np.array创建数组
# 1. 使用np.array创建数组
a = np.array([1,2,3,4])
#打印数组
print(a)
#查看类型
print(type(a))
1.2. 使用np.arange创建数组
#2. 使用np.arange创建数组
#创建0-10步数为2的数组 结果为[0,2,4,6,8]
b = np.arange(0,10,2)
1.3. np.random.random创建数组
#3. np.random.random创建一个N行N列的数组
# 其中里面的值是0-1之间的随机数
# 创建2行2列的数组
c = np.random.random((2,2))
1.4. np.random.randint创建数组
#4. np.random.randint创建一个N行N列的数组
# 其中值的范围可以通过前面2个参数来指定
# 创建值的范围为[0,9)的4行4列数组
d = np.random.randint(0,9,size=(4,4))
1.5. 特殊函数
#5. 特殊函数
#5.1 zeros
## N行N列的全零数组
### 例如:3行3列全零数组
array_zeros = np.zeros((3,3))
#5.2 ones
## N行N列的全一数组
### 例如:4行4列全一数组
array_ones = np.ones((4,4))
#5.3 full
## 全部为指定值的N行N列数组
### 例如:值为0的2行3列数组
array_full = np.full((2,3),9)
#5.4 eye
## 生成一个在斜方形上元素为1,其他元素都为0的N行N列矩阵
### 例如:4行4列矩阵
array_eye = np.eye(4)
1.6. 注意
数组中的数据类型必须一致,要么全部为整型,要么全部为浮点类型,要么全部为字符串类型
不能同时出现多种数据类型
2. 数组数据类型
2.1 数据类型
| 数据类型 | 描述 | 唯一标识符 |
|---|---|---|
| bool | 用一个字节存储的布尔类型(True或False) | b |
| int8 | 一个字节大小,-128 至 127 | i1 |
| int16 | 整数,16 位整数(-32768 ~ 32767) | i2 |
| int32 | 整数,32 位整数(-2147483648 ~ 2147483647) | i4 |
| int64 | 整数,64 位整数(-9223372036854775808 ~ 9223372036854775807) | i8 |
| uint8 | 无符号整数,0 至 255 | u1 |
| uint16 | 无符号整数,0 至 65535 | u2 |
| uint32 | 无符号整数,0 至 2 ** 32 - 1 | u4 |
| uint64 | 无符号整数,0 至 2 ** 64 - 1 | u8 |
| float16 | 半精度浮点数:16位,正负号1位,指数5位,精度10位 | f2 |
| float32 | 单精度浮点数:32位,正负号1位,指数8位,精度23位 | f4 |
| float64 | 单精度浮点数:64位,正负号1位,指数11位,精度52位 | f8 |
| complex64 | 复数,分别用两个32位浮点数表示实部和虚部 | c8 |
| complex128 | 复数,分别用两个64位浮点数表示实部和虚部 | c16 |
| object_ | python对象 | O |
| string_ | 字符串 | S |
| unicode_ | unicode类型 | U |
2.2 创建数组指定数据类型
import numpy as np
a = np.array([1,2,3,4,5],dtype='i1')
a = np.array([1,2,3,4,5],dtype=int32)
2.3 查询数据类型
class Person:
def __init__(self,name,age):
self.name = name
self.age = age
d = np.array([Person('test1',18),Person('test2',20)])
print(d)
print(d.dtype)
2.4 修改数据类型
f = a.astype('f2')
2.5 总结
(1) Numpy是基于C语言编写,引用了C语言的数据类型,所以Numpy的数组中数据类型多样
(2) 不同的数据类型有利于处理海量数据,针对不同数据赋予不同数据类型,从而节省内存空间
3. 多维数组
3.1 数组维度查询
import numpy as np
# 数组维度
## 维度为1
a1 = np.array([1,2,3])
print(a1.ndim)
## 维度为2
a2 = np.array([[1,2,3],[4,5,6]])
print(a2.ndim)
## 维度为3
a3 = np.array([
[
[1,2,3],
[4,5,6]
],
[
[7,8,9],
[10,11,12]
]
])
print(a3.ndim)
3.2 数组形状查询
a1 = np.array([1,2,3])
# 结果为(3,)
print(a1.shape)
a2 = np.array([[1,2,3],[4,5,6]])
# 结果为(2,3)
print(a2.shape)
a3 = np.array([
[
[1,2,3],
[4,5,6]
],
[
[7,8,9],
[10,11,12]
]
])
# 结果为(2,2,3)
print(a3.shape)
3.3 修改数组形状
a1 = np.array([
[
[1,2,3],
[4,5,6]
],
[
[7,8,9],
[10,11,12]
]
])
a2 = a1.reshape((2,6))
print(a2)
#结果为(2, 6)
print(a2.shape)
# 扁平化 (多维数组转化为一维数组)
a3 = a2.flatten()
print(a3)
print(a3.ndim)
3.4 数组元素个数与所占内存
a1 = np.array([
[
[1,2,3],
[4,5,6]
],
[
[7,8,9],
[10,11,12]
]
])
#数组的元素个数
count = a1.size
print(count)
#各元素所占内存
print(a1.itemsize)
#各元素数据类型
print(a1.dtype)
#数组所占内存
print(a1.itemsize * a1.size)
3.5 总结
(1)一般情况下,数组维度最大到三维,一般会把三维以上的数组转化为二维数组来计算
(2)ndarray.ndmin查询数组的维度
(3)ndarray.shape可以看到数组的形状(几行几列),shape是一个元组,里面有几个元素代表是几维数组
(4)ndarray.reshape可以修改数组的形状。条件只有一个,就是修改后的形状的元素个数必须和原来的个数一致。比如原来是(2,6),那么修改完成后可以变成(3,4),但是不能变成(1,4)。reshape不会修改原来数组的形状,只会将修改后的结果返回。
(5)ndarray.size查询数组元素个数
(6)ndarray.itemsize可以看到数组中每个元素所占内存的大小,单位是字节。(1个字节=8位)
4. 数组索引和切片
4.1 一维数组
import numpy as np
# 1. 一维数组的索引和切片
a1 = np.arange(10)
## 结果为:[0 1 2 3 4 5 6 7 8 9]
print(a1)
# 1.1 进行索引操作
## 结果为:4
print(a1[4])
# 1.2 进行切片操作
## 结果为:[4 5]
print(a1[4:6])
# 1.3 使用步长
## 结果为:[0 2 4 6 8]
print(a1[::2])
# 1.4 使用负数作为索引
## 结果为:9
print(a1[-1])
4.2 二维数组
# 2. 多维数组
# 通过中括号来索引和切片,在中括号中使用逗号进行分割
#逗号前面的是行,逗号后面的是列,如果多维数组中只有一个值,那么这个值就是行
a2 = np.random.randint(0,10,size=(4,6))
print(a2)
#获取第0行数据
print(a2[0])
#获取第1,2行数据
print(a2[1:3])
#获取多行数据 例0,2,3行数据
print(a2[[0,2,3]])
#获取第二行第一列数据
print(a2[2,1])
#获取多个数据 例:第一行第四列、第二行第五列数据
print(a2[[1,2],[4,5]])
#获取多个数据 例:第一、二行的第四、五列的数据
print(a2[1:3,4:6])
#获取某一列数据 例:第一列的全部数据
print(a2[:,1])
#获取多列数据 例:第一、三列的全部数据
print(a2[:,[1,3]])
4.3 总结
1. 如果数组是一维的,那么索引和切片就是和python的列表是一样的
2. 如果是多维的(这里以二维为例),那么在中括号中,给两个值,两个值是通过逗号分隔的,逗号前面的是行,逗号后面的是列。如果中括号中只有一个值,那么就是代表行。
3. 如果是多维数组(以二维为例),那么行的部分和列的部分,都是遵循一维数组的方式,可以使用整型、切片,还可以使用中括号的形式代表连续的。比如a[[1,2],[3,4]],那么返回的就是第一行第三列、第二行第四列的两个值。
5. 布尔索引
#生成1-24的4行6列的二维数组
a2 = np.arange(24).reshape((4,6))
#array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
a2[a2<10]
#array([ 0, 1, 2, 3, 4, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22,23])
a2[(a2<5) | (a2>10)]
5.1总结
(1) 布尔索引是通过相同数据上的True还是False来进行提取的。
(2) 提取条件可以为一个或多个,当提取条件为多个时使用&代表且,使用|代表或
(3) 当提取条件为多个时,每个条件要使用圆括号括起来
6. 数组元素值的替换
6.1 方式一:索引
#利用索引可以做值的替换,把满足条件的位置的值替换成其他值
#创建数组元素值为[0,10)随机数的3行5列数组
a3 = np.random.randint(0,10,size=(3,5))
print(a3)
#将a3数组第一行数据全部更换为0
a3[1] = 0
print(a3)
#将a3数组第一行数据更换为[1,2,3,4,5] -- 数据个数要对应
a3[1] = np.array([1,2,3,4,5])
print(a3)
6.2 方式二:条件索引
#数组中值小于3的元素全部替换为1
a3[a3 < 3] = 1
print(a3)
6.3 方式三:函数
#将a3数组中小于5的值替换为0,剩余值替换为1
result = np.where(a3<5,0,1)
result
6.4 总结
(1)使用索引或者切片来替换值
(2)使用条件索引来替换值
(3)使用where函数来实现替换值
7. 数组的广播机制
7.0. 数组的广播原则
如果两个数组的后缘维度(即从末尾开始算起的维度)的轴长度相符或其中一方的长度为1,则认为他们是广播兼容的。广播会在全是和(或)长度为1的维度上进行。
案例分析:
-
shape为(3,8,2)的数组能和(8,3)的数组进行运算吗?分析:不能,因为安装广播原则,从后面网前面数,(3,8,2)和(8,3)中的2和3不相等,所以不能进行运算
-
shape为(3,8,2)的数组能和(8,1)的数组进行运算吗?分析:能,因为按照广播原则,从后面往前面数,(3,8,2)和(8,1)中的2和1虽然不相等,但因为有一方的长度为1,所以能参加运算
-
shape为(3,1,8)的数组能和(8,1)的数组进行运算吗?分析:能,因为按照广播原则,从后面往前面数,(3,1,8)和(8,1)中的4和1虽然不相等且1和8不相等,但是因为这两项中有一方的长度为1,所以能参加运算
7.1. 数组与数字运算
import numpy as np
#生成3行5列 值为0-5随机整数的数组
a1 = np.random.randint(0,5,size=(3,5))
#数组中的所有元素都乘2
print(a1*2)
#数组中所有的元素只保留2位小数
print(a1.round(2))
7.2. 数组与数组运算
#数组形状一致时 各个元素相加减(满足数组广播机制)
a2 = np.random.randint(0,5,size=(3,5))
a1+a2
#形状不一致的数组不能相加减(不满足数组广播机制)
a3 = np.random.randint(0,5,size=(3,4))
# a1+a3 报错
#两个数组行数相同 ,其中一个数组列数为1(满足数组广播机制)
a4 = np.random.randint(0,5,size=(3,1))
a1+a4
#两个数组列数相同 ,其中一个数组行数为1(满足数组广播机制)
a5 = np.random.randint(0,5,size=(1,5))
a1+a5
7.3总结
(1) 数组和数字直接进行运算是没有问题的
(2) 两个shape想要的数组是可以进行运算的
(3) 如果两个shape不同的数组,想要进行运算,那么需要看他们是否满足广播原则
8. 数组形状的操作
8.1. 数组形状的改变
8.1.1 reshape与resize
import numpy as np
# reshape与resize都是用来修改数组形状的,但是存在不同
a1 = np.random.randint(0,10,size=(3,4))
# reshape是将数组转换成指定的形状,然后返回转换后的结果,对于原数组的形状是不会发生改变的
a2 = a1.reshape((2,6))
# resize是将数组转换成指定的形状,会直接修改数组本身,并且不会返回任何值
a1.resize((4,3))
print(a1)
8.1.2 flatten与ravel
# faltten与ravel都是将多维数组转换为一维数组,但是存在不同
a3 = np.random.randint(0,10,size=(3,4))
# flatten是将数组转换为一维数组后,然后将这个拷贝返回回去,然后后续对这个返回值进行修改不会影响之前的数组
a4 = a3.flatten()
a4[0] = 100
# 结果为:2
print(a3[0,0])
# 结果为:100
print(a4[0])
# ravel是将数组转换为一维数组后,将这个视图(引用)返回回去,后续对这个返回值进行修改会影响之前的数组
a5 = a3.ravel()
a5[0] = 100
# 结果为:100
print(a3[0,0])
# 结果为:100
print(a5[0])
8.2 数组的叠加
#vstack代表在垂直方向叠加,如果想要叠加成功,那么列数必须一致
#hstack代表在水平方向叠加,如果想要叠加成功,那么行数必须一致
#concatenate可以手动的指定axis参数具体在哪个方向叠加
##(1)如果axis=0,代表在水平方向叠加
##(2)如果axis=1,代表在垂直方向叠加
##(3)如果axis=None,会先进行叠加,再转化为1维数组
vstack1 = np.random.randint(0,10,size=(3,4))
print(vstack1)
vstack2 = np.random.randint(0,10,size=(2,4))
print(vstack2)
#垂直方向叠加的两种方式
vstack3 = np.vstack([vstack1,vstack2])
print(vstack3)
vstack4 = np.concatenate([vstack1,vstack2],axis=0)
print(vstack4)
h1 = np.random.randint(0,10,size=(3,4))
print(h1)
h2 = np.random.randint(0,10,size=(3,1))
print(h2)
#水平方向叠加的两种方式
h3 = np.hstack([h2,h1])
print(h3)
h4 = np.concatenate([h2,h1],axis=1)
print(h4)
#先识别垂直叠加或水平叠加 后转换为一维数组
h5 = np.concatenate([h2,h1],axis=None)
print(h5)
8.3. 数组的切割
#hsplit代表在水平方向切割,按列进行切割。
#hsplit切割方式两种,第一种直接指定平均切割成多少列,第二种是指定切割的下标值
#vsplit代表在垂直方向切割,按行进行切割。切割方式与hsplit相同
#split/array_split是手动的指定axis参数,axis=0代表按行进行切割,axis=1代表按列进行切割
hs1 = np.random.randint(0,10,size=(3,4))
print(hs1)
#水平方向平均分为2份 (要求列数可被此数整除)
np.hsplit(hs1,2)
#水平方向分为1,1,2列(在下标为1,2处切割)
np.hsplit(hs1,(1,2))
vs1 = np.random.randint(0,10,size=(4,5))
print(vs1)
#垂直方向平均分为4份
np.vsplit(vs1,4)
#垂直方向分为1,2,1
np.vsplit(vs1,(1,3))
#split/array_split(array,indicate_or_section,axis):用于指定切割方式,在切割的时候需要指定按照行还是列,axis=1代表按照列,axis=0代表按照行
#按列平均切割
np.split(hs1,4,axis=1)
#按行平均切割
np.split(vs1,4,axis=0)
8.4. 矩阵转置
#通过ndarray.T的形式进行转置
t1 = np.random.randint(0,10,size=(3,4))
print(t1)
#数组t1转置
t1.T
#矩阵相乘
t1.dot(t1.T)
#通过ndarray.transpose()进行转置
#transpose返回的是一个View,所以对返回值上进行修改会影响到原来的数组。
t2 = t1.transpose()
t2
8.5 总结
1. 数据的形状改变
(1)reshape和resize都是重新定义形状的,但是reshape不会修改数组本身,而是将修改后的结果返回回去,而resize是直接修改数组本身的
(2)flatten和ravel都是用来将数组变成一维数组的,并且他们都不会对原数组造成修改,但是flatten返回的是一个拷贝,所以对flatten的返回值的修改不会影响到原来数组,而ravel返回的是一个View,那么对返回值的修改会影响到原来数组的值
2. 数据的叠加
(1)hstack代表在水平方向叠加,如果想要叠加成功,那么他们的行必须一致
(2)vastack代表在垂直方向叠加,如果想要叠加成功,那么他们的列必须一致
(3)concatenate可以手动指定axis参数具体在哪个方向叠加,如果axis=0,代表在水平方向叠加,如果axis=1,代表在垂直方向叠加,如果axis=None,那么会先进行叠加,再转化成一维数组
3. 数组的切割
(1)hsplit代表在水平方向切割,按列进行切割。切割方式有两种,第一种就是直接指定平均切割成多少列,第二种就是指定切割的下标值
(2)vsplit代表在垂直方向切割,按行进行切割。切割方式与hsplit一致。
(3)split/array_split是手动的指定axis参数,axis=0代表按行进行切割,axis=1代表按列进行切割
4. 矩阵转置
(1)可以通过ndarray.T的形式进行转置
(2)也可以通过ndarray.transpose()进行转置,这个方法返回的是一个View,所以对返回值上进行修改,会影响到原来的数组
9. View或者浅拷贝
9.1 不拷贝
如果只是简单的赋值,那么就不会进行拷贝
import numpy as np
a = np.arange(12)
#这种情况不会进行拷贝
b = a
#返回True,说明b和a是相同的
print(b is a)
9.2 浅拷贝
有些情况,会进行变量的拷贝,但是他们所指向的内存空间都是一样的,那么这种情况叫做浅拷贝,或者叫做View(视图)
c = a.view()
#返回false,说明c与a在栈区空间不同,但是所指向的内存空间是一样的
print(c is a)
#对c的值修改 同时也会对a进行修改
c[0] = 100
#array([100,1,2,3,4,5,6,7,8,9,10,11])
print(a)
9.3 深拷贝
将之前数据完完整整的拷贝一份放到另外一块内存空间中,这样就是两个完全不同的值了
d = a.copy()
#返回False 说明在不同栈区
print(d is a)
#数组d值被修改,数组a值不会被修改 说明内存空间不同
d[1]=200
9.4 总结
在数组操作中分成三种拷贝:
(1)不拷贝:直接赋值,那么栈区没有拷贝,只是用同一个栈区定义了不同的名称
(2)浅拷贝:只拷贝栈区,栈区指定的堆区并没有拷贝
(3)深拷贝:栈区和堆区都拷贝
10. 文件操作
10.1 操作CSV文件
10.1.1 文件保存
np.savetxt(frame,array,fmt=“%.18e”,delimiter=None)
函数功能:将数组保存到文件中
参数说明:
· frame:文件、字符串或产生器,可以是.gz或.bz2的压缩文件
· array:存入文件的数组
· fmt:写入文件的格式,例如:%d %.2f %.18e
· delimter:分割字符串,默认是空格
import numpy as np
scores = np.random.randint(0,100,size=(10,2))
#保存csv文件
np.savetxt("score.csv",scores,fmt="%d",delimiter=",",header="英语,数学",comments="")
10.1.2 读取文件
np.loadtxt(frame,dtype=np.float,delimiter=None,unpack=False)
函数功能:将数组保存到文件中
参数说明:
· frame:文件、字符串或产生器,可以是.gz或.bz2的压缩文件
· dtype:数据类型,可选
· delimiter:分割字符串,默认是任何空格
· skiprows:跳过前面x行
· usecols:读取指定的列,用元组组合
· unpack:如果True,读取出来的数组是转置后的
#读取csv文件 跳过第一行的表头
b = np.loadtxt("score.csv",dtype=np.int,delimiter=",",skiprows=1)
b
10.2 np独有的存储解决方案
numpy中还有一种独有的存储解决方案。文件名是以.npy或者npz结尾的。以下是存储和加载的函数:
1. 存储
np.save(fname,a rray)
或np.savez(fname,array)
其中,前者函数的扩展名是.npy,后者的扩展名是.npz,后者是经过压缩的。
2.加载
np.load(fname)
c = np.random.randint(0,10,size=(2,3))
#存储
np.save("c",c)
#读取
c1 = np.load("c.npy")
c1
10.3 总结
1. np.savetxt和np.loadtxt一般用来操作CSV文件,可以设置header,但是不能存储3维以上的数组。
2. np.save和np.load一般用来存储非文本类型的文件,不可以设置header,但是可以存储3维以上的数组
3. 如果想专门的操作csv文件,还存在另一个模块叫做csv,这个模块是python内置的,不需要安装
11. NAN和INF值处理
11.1 介绍
NAN:Not A number,不是一个数字的意思,但是他是浮点类型的,所以想要进行数据操作的时候需要注意他的类型
import numpy as np
data = np.random.randint(0,10,size=(3,5))
data = data.astype(np.float)
#将数组中某个位置的值设置为NAN
data[0,1]=np.NAN
data
INF:Infinity,代表的是无穷大的意思,也是属于浮点类型。np.inf表示正无穷大,-np.inf表示负无穷大,一般在出现除数为0的时候为无穷大。比如2/0
11.2 NAN特点
-
NAN和NAN不相等。比如 np.NAN != np.NAN 这个条件是成立的
-
NAN和任何值做运算,结果都是NAN
11.3 处理缺失值的方式
11.3.1 删除缺失值
有时候,我们想要将数组中的NAN删掉,那么我们可以换一种思路,就是只提取不为NAN的值
#第一种方式: 删除所有NAN的值,因为删除了值后数组将不知道该怎么变化,所以会被变成一维数组
data[~np.isnan(data)]
#第二种方式: 删除NAN所在行
## 获取哪些行有NAN
lines = np.where(np.isnan(data))[0]
## 使用delete方法删除指定的行,lines表示删除的行号,axis=0表示删除行
np.delete(data,lines,axis=0)
11.3.2 用其他值进行替代
#从文件中读取数据
scores = np.loadtxt("scores.csv",delimiter=",",skiprows=1,dtype=np.str)
#将空数据转换成NAN
scores[scores == ""] = np.NAN
#转化成float类型
scores1 = scores.astype(np.float)
#将NAN替换为0
scores1[np.isnan(scores1)]=0
#除了delete用axis=0表示行以外,其他的大部分函数都是axis=1来表示行
#对指定轴求和 axis=1按行
scores1.sum(axis=1)
#将空值替换为均值
#对scores进行深拷贝
scores2 = scores.astype()
#循环遍历每一列
for x in range(score2.shape[1]):
col = scores2[:,x]
#去除该列中值为NAN
non_nan_col = col[~np.isnan(col)]
#求平均值
mean = non_nan_col.mean()
#将该列中值为NAN的数值替换为平均值
col[np.isnan(col)] = mean
scores2
11.4 总结
(1)NAN:Not A Number的简写,不是一个数字,但是是属于浮点类型
(2)INF:无穷大,在除数为0的情况下会出现INF
(3)NAN和所有的值进行计算结果都是等于NAN
(4)NAN != NAN
(5)可以通过np.isnan来判断某个值是不是NAN
(6)处理值的时候,可以通过删除NAN的形式进行处理,也可以通过值的替换进行处理
(7)np.delete比较特殊,通过axis=0来代表行,而其他大部分函数通过axis=1来代表行
12. random模块
12.1 np.random.seed
用于指定随机数生成时所用算法开始的整数值,如果使用相同的seed()值,则每次生成的随机数都相同,如果不设置这个值,则系统根据时间来自己选择这个值,此时每次生成的随机数因时间差异不同。一般没有特殊要求不用设置。
np.random.seed(1)
#打印0.417022004702574
np.random.rand()
#打印其他的值,因为随机数种子支队下一次随机数的产生会有影响
np.random.rand()
12.2 np.random.rand
生成一个值为 [0,1) 之间的数组,形状由参数指定,如果没有参数,那么将返回一个随机值
#产生随机数
np.random.rand()
#产生随机数组 两行三列
np.random.rand(2,3)
12.3 np.random.randn
生成均值(μ)为0,标准差(σ)为1的标准正态分布的值
#生成一个2行3列的数组,数组中的值都满足标准正态分布
data = np.random.randn(2,3)
data
12.4 np.random.randint
生成指定范围内的随机数,并且可以通过size参数指定维度
#生成值在0-10之间,3行5列的数组
data1 = np.random.randint(10,size=(3,5))
#生成值在1-20之间,3行6列的数组
data2 = np.random.randint(1,20,size=(3,6))
12.5 np.random.choice
从一个列表或者数组中,随机进行采样。或者是从指定的区间中进行采样,采样个数可以通过参数
#从数组中随机选择三个值
np.random.choice(data,3)
#从数组中获取值组成新的数组
np.random.choice(data,size=(3,4))
#从指定值随机取值 (示例:从0-10之间随机取3个值)
np.random.choice(10,3)
12.6 np.random.shuffle
把原来数组的元素的位置打乱
a = np.arange(10)
#将数组a的元素的位置都会进行随机更换
#shuffle没有返回值,直接打乱原数组位置
np.random.shuffle(a)
a
13. Axis理解
13.1 Axis
简单来说,最外面的括号代表着axis=0,依次往里的括号对应的axis的计数就依次加1
如下图,最外面的括号就是axis=0,里面两个子括号axis=1
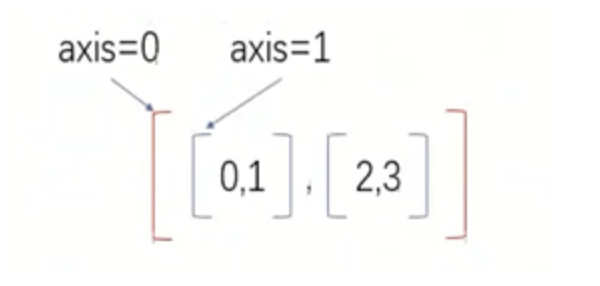
操作方式:如果指定轴进行相关的操作,那么他会使用轴下的每一个直接子元素的第0个,第1个,第2个…分别进行相关的操作
示例:
x = np.array([[0,1],[2,3]])
1.求 x 数组在axis = 0 和 axis=1 两种情况下的和
#结果为[2,4]
x.sum(axis=0)
分析:按照axis=0的方式相加,那么就会把最外面轴下的所有直接子元素的第0个位置进行相加,第1个位置进行相加…依次类推,得到的就是 0+2 以及 2+3 ,然后进行相加,得到的结果就是 [2,4]
2.用np.max求 axis=0 和 axis=1 两种情况下的最大值
np.random.seed(100)
x = np.random.randint(1,10,size=(3,5))
#输出结果为:
#[[9 9 4 8 8]
# [1 5 3 6 3]
# [3 3 2 1 9]]
print(x)
#结果为[9, 9, 4, 8, 9]
x.max(axis=0)
#结果为[9, 6, 9]
x.max(axis=1)
分析:按照axis=0进行求最大值,那么就会在最外面轴里面找直接子元素,然后将每个子元素的第0个值放在一起求最大值,将第1个值放在一起求最大值,以此类推。而如果axis=1,那么就是拿到每个直接子元素,然后求每个子元素中的最大值
3.用 np.delete 在 axis=0 和 axis=1 两种情况下删除元素
np.random.seed(100)
x = np.random.randint(1,10,size=(3,5))
#输出结果为:
#[[9 9 4 8 8]
# [1 5 3 6 3]
# [3 3 2 1 9]]
print(x)
#删除第0行
#结果为:
#[[1, 5, 3, 6, 3],
# [3, 3, 2, 1, 9]]
np.delete(x,0,axis=0)
分析:np.delete是个例外,按照 axis=0 的方式进行删除,那么会首先找到最外面的括号下的直接子元素的第0个,然后直接删掉,剩下最后一行的数据。同理,如果我们按照 axis=1 进行删除,那么会把第一列的数据删掉
13.2 三维数组及多维数组
#生成一个三维数组
#[[[ 0, 1, 2, 3, 4, 5],
# [ 6, 7, 8, 9, 10, 11]],
# [[12, 13, 14, 15, 16, 17],
# [18, 19, 20, 21, 22, 23]]]
y = np.arange(24).reshape(2,2,6)
#取最大值
#结果为:
#[[12, 13, 14, 15, 16, 17],
# [18, 19, 20, 21, 22, 23]]
y.max(axis=0)
13.3 总结
(1)最外面的括号代表着 axis=0,依次往里的括号对应的 axis 的计数就依次加1
(2)操作方式:如果指定轴进行相关的操作,那么他会使用轴下面的每个直接子元素的第0个,第1个,第2个...分别进行相关的操作
(3)np.delete是直接删除指定轴下的第几个直接子元素
14. 通用函数
14.1 一元函数
| 函数 | 描述 |
|---|---|
| np.abs | 绝对值 |
| np.sqrt | 开方(负数开方结果为NAN) |
| np.square | 平方 |
| np.exp | 计算指数(e^x) |
| np.log,np.log10,np.log2,np.log1p | 求以e为底,以10为底,以2为底,以(1+x为底的对数 |
| np.sign | 将数组中的值标签化,大于0的变成1,等于0的变成0,小于0的变成-1 |
| np.ceil | 朝着无穷大的方向取整,比如5.1会变成6,-6.3会变成-6 |
| np.floor | 朝着负无穷大的方向取整,比如5.1会变成5,-6.3会变成-7 |
| np.rint,np.round | 返回四舍五入后的值 |
| np.modf | 将整数和小数分割开来形成两个数组 |
| np.isnan | 判断是否是nan |
| np.isinf | 判断是否是inf |
| np.cos,np.cosh,np.sinh,np.tan,np.tanh | 三角函数 |
| np.arccos,np.arcsin,np.arctan | 反三角函数 |
14.2 二元函数
| 函数 | 描述 |
|---|---|
| np.add | 加法运算(即1+1=2),相当于+ |
| np.subtract | 减法运算(即3-2=1),相当于- |
| np.negative | 复数运算(即-2)。相当于加个负号 |
| np.multiply | 乘法运算(即2_3=6),相当于_ |
| np.divide | 除法运算(即3/2=1.5),相当于/ |
| np.floor_divide | 取整运算,相当于// |
| np.mod | 取余运算,相当于% |
| greater,greater_equal,less,less_equal,equal,not_equal | >,>=,<,<=,=,!=的函数表达式 |
| logical_and | 且运算符函数表达式 |
| logical_or | 或运算符函数表达式 |
14.3 聚合函数
| 函数名称 | NAN安全版本 | 描述 |
|---|---|---|
| np.sum | np.nansum | 计算元素的和 |
| np.prod | np.nanprod | 计算元素的积 |
| np.mean | np.nanmean | 计算元素的平均值 |
| np.std | np.nanstd | 计算元素的标准差 |
| np.var | np.nanvar | 计算元素的方差 |
| np.min | np.nanmin | 计算元素的最小值 |
| np.max | np.nanmax | 计算元素的最大值 |
| np.argmin | np.nanargmin | 找出最小值的索引 |
| np.argmax | np.nanargmax | 找出最大值的索引 |
| np.median | np.nanmedian | 计算元素的中位数 |
补充:使用np.sum或者是a.sum即可实现。并且在使用的时候,可以指定具体哪个轴。同样python中也内置了sum函数,但是python内置的sum函数执行效率没有np.sum那么高。
14.4 布尔数组的函数
| 函数名称 | 描述 |
|---|---|
| np.any | 验证任何一个元素是否为真 |
| np.all | 验证所有元素是否为真 |
#查看数组中是不是所有元素都为0
#方式一
np.all(a==0)
#方式二
(a==0).all()
#查看数组中是否有等于0的数
#方式一
np.any(a==0)
#方式二
(a==0).any()
14.5 排序
14.5.1 np.sort
函数说明:指定轴进行排序。默认是使用数组的最后一个轴进行排序。
还有ndarray.sort(),这个方法会直接影响到原来的数组,而不是返回一个新的排序后的数组
#生成数组
a = np.random.randint(0,10,size=(5,5))
#按照行进行排序,因为最后一个轴是1,那么就是将最里面的元素进行排序
np.sort(a)
#按照列进行排序,因为指定了axis=0
np.sort(a,axis=0)
#该方法进行排序会影响原数组
a.sort()
14.5.2 np.argsort
函数说明:返回排序后的下标值。
#返回排序后的下标值
np.argsort(a)
14.5.3 np.sort (降序)
np.sort()默认会采用升序排序,用一下方案来实现降序排序
#方式一:使用负号
-np.sort(-a)
#方式二:使用sort和argsort以及take
#排序后的结果就是降序的
indexes = np.argsort(-a)
#从a中根据下标提取相应的元素
np.take(a,indexes)
14.6 其他函数
14.6.1 np.apply_along_axis
函数说明:沿着某个轴执行指定的函数
#求数组a按行求平均值,并且要去掉最大值和最小值
#函数
def get_mean(x):
#排除最大值和最小值后求平均值
y=x[np.logical_and(x!=x.max,x!=x.min)].mean()
return y
#方式一:调用函数
np.apply_along_axis(get_mean,axis=1,arr=c)
#方式二:lambda表达式
np.apply_along_axis(lambda x:x[np.logical_and(x!=x.max,x!=x.min)].mean(),axis=1,arr=c)
14.6.2 np.linspace
函数说明:用来将指定区间内的值平均分成多少份
#将0-10分成12份,生成一个数组
np.linspace(0,10,12)
14.6.3 np.unique
函数说明:返回数组中的唯一值
#返回数组a中的唯一值
np.unique(d)
#返回数组a中的唯一值,并且会返回每个唯一值出现的次数
np.unique(d,return_counts=True)














 536
536











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









