







首先去官方网址下载源码如下:
点我点我
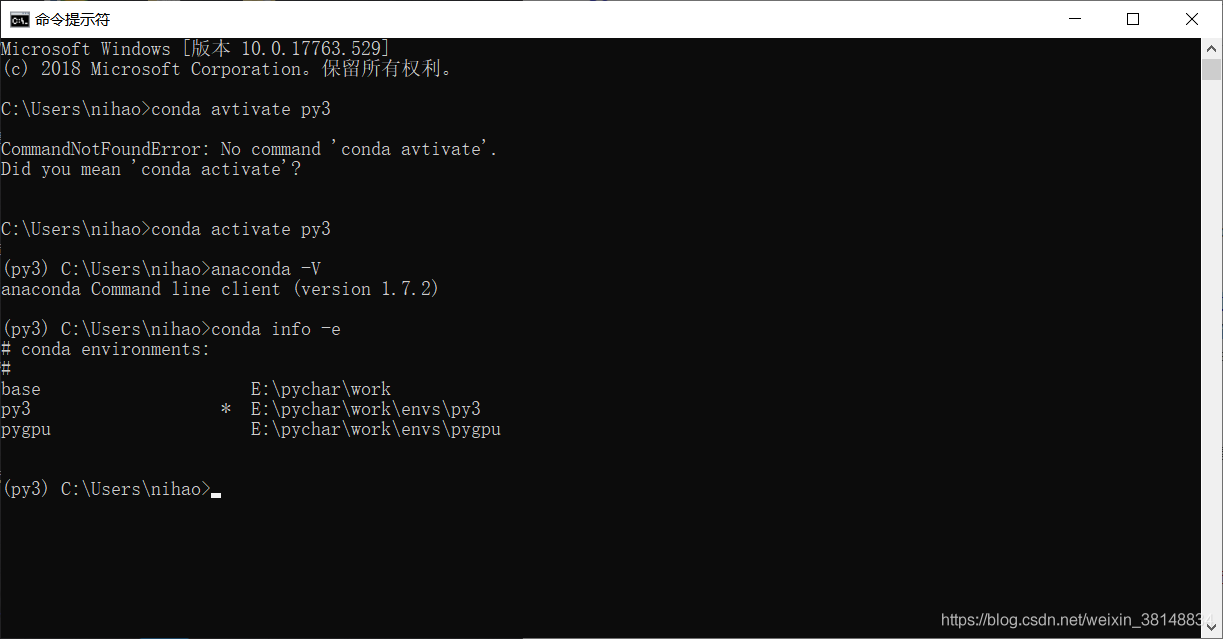
下载好了以后,在cmd安装anaconda 1.7.2,然后你们自己百度创建个环境啥的,我的环境如下:
(因为没有gpu,所以主要用基于cpu的py3环境)
- 先浏览官网的环境要求
- Python 2.7 or Python 3.3+
- Tensorflow 0.12.1
- SciPy
- pillow
- (Optional)moviepy (for visualization)
- (Optional)Align&Cropped Images.zip : Large-scale CelebFaces Dataset
然后查看自己的python是什么版本:
直接打开cmd,输入以下代码就行了,就会出现版本号,我的是3.7.0,符合要求(python3.3+)
python

然后进入虚拟环境py3:
conda activate py3
那个官网是写的tensorflow 0.12.1,但是我指定版本安装后发现不可以,这个版本不存在,于是我查看了现在我的tensorflow 版本是1.11.0,高版本应该可以兼容低版本吧,试试看。。。
pip install tensorflow==0.12.1

继续安装官方需要的包,如下图,我好像都安装过,它显示了路径。

按照官网的顺序进行输入代码1:
python download.py mnist celebA
然后它提示我缺少包,它说啥就是啥。。。安上!
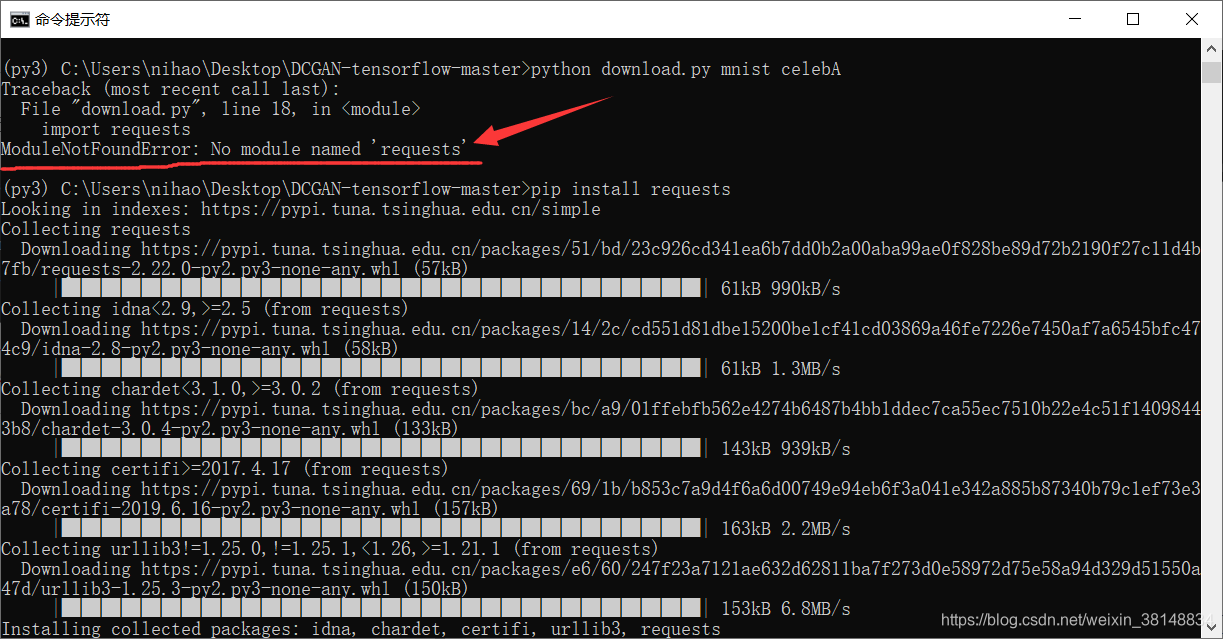
安装完再执行代码1,报错,说是链接不上,应该是源有问题:
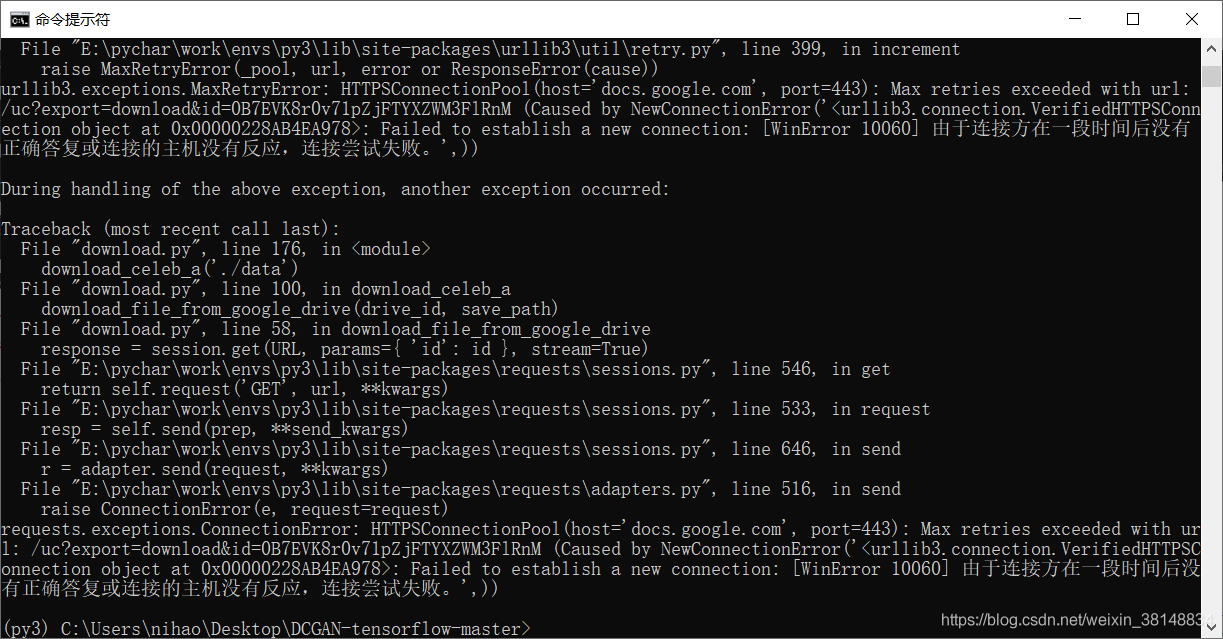
错误原因是:没有连上外网,所以下载不了。找了一台同事的台式,帮我下载好了,并且解压放在和代码同一个文件夹下面。如图:
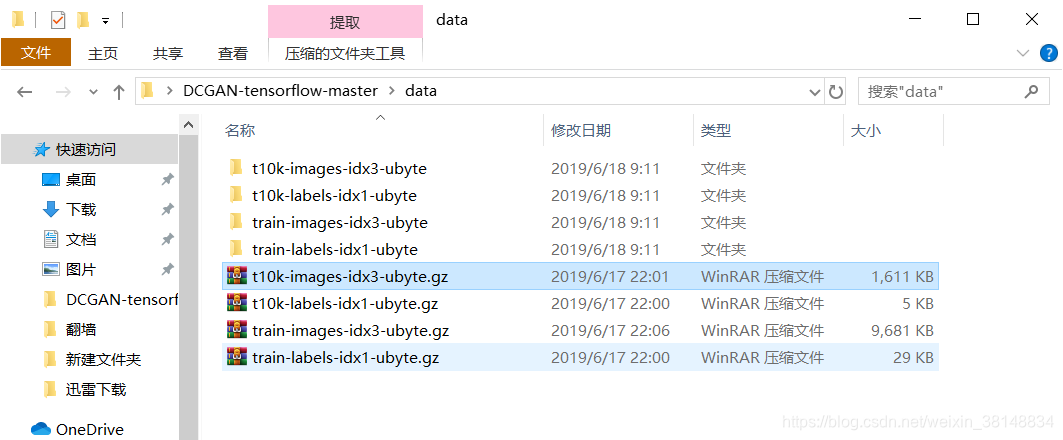
接下来执行:
python main.py --dataset mnist --input_height=28 --output_height=28 --train
报错:说这个文件不存在,于是我去打开我放有数据集的文件夹,发现是IDX1-UBYTE 文件。
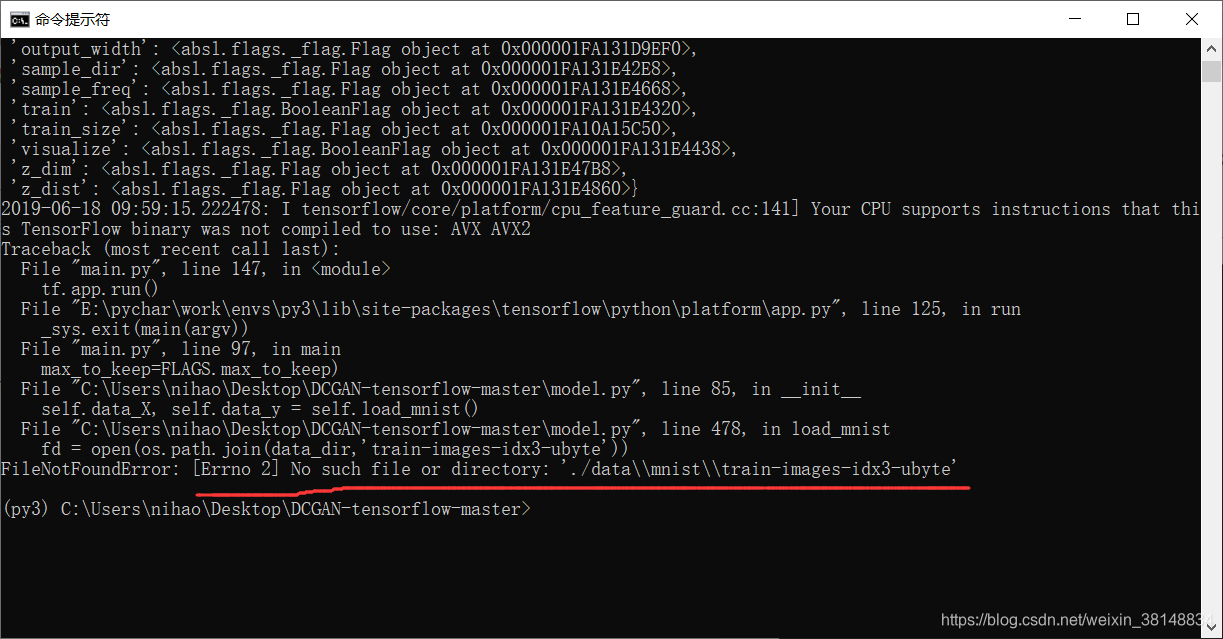
然后到这里,卡住了,因为minist原来的数据集下载下来是数字组成的,还得另外写代码编译。然后我看到了官网写的另外一段代码:
可以使用自己的数据集(吧你的数据集放在DCGAN-tensorflow-master\data目录下)
并且把DATASET_NAME换成你自己数据集的名字就可以了。
$ mkdir data/DATASET_NAME
... add images to data/DATASET_NAME ...
$ python main.py --dataset DATASET_NAME --train
$ python main.py --dataset DATASET_NAME
$ # example
$ python main.py --dataset=eyes --input_fname_pattern="*_cropped.png" --train
我随便从imagnet(train数据集)中的1000的种类中,随机选了113类,每一类一张图(大小256*256),做成新的数据集,起名small100,并且输入下面代码:
python main.py --dataset small100 --input_height=256 --output_height=256 --train
代码就开始顺利的跑起来了!如图:
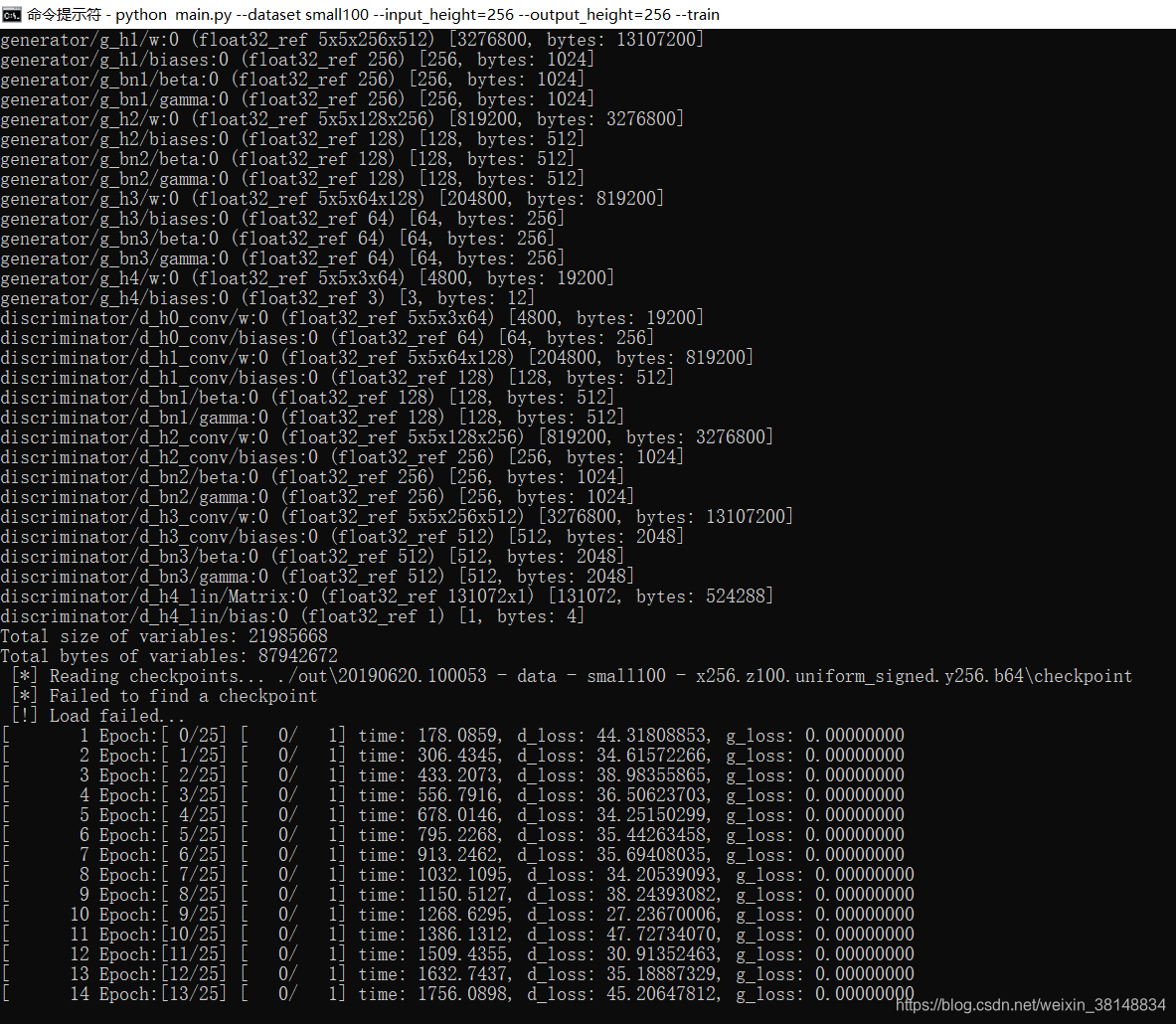
一开始它是默认25epoch,还有很多参数都是可以改的,都在main.py里面。
我的cpu已经开始燃烧了。。。。。笔记本风扇呼呼的。。。。
参考资料链接:
1、Windows下用DCGAN训练自己的数据集
http://www.pianshen.com/article/6611314207/
2、详解 MNIST 数据集
https://blog.csdn.net/simple_the_best/article/details/75267863














 4038
4038











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









