






Hadoop安装主要步骤:
(1)安装运行环境
(2)修改主机名和用户名
(3)配置静态IP地址
(4)配置SSH无密码连接
(5)安装JDK
(6) 配置Hadoop
(7) 格式化 hdfs并验证安装
下面详细解释
(1)安装运行环境,本文采用的是ubuntu镜像文件,大小在1.95G.下载链接为:
https://ubuntu.com/download/desktop/thank-you?country=CN&version=18.04.3&architecture=amd64

虚拟机为Vmware,下载地址为:
https://www.virtualbox.org/wiki/Downloads

配置过程中,电脑的内存最好大于1G, 2G-4G为佳,如果低于一定数值,就会面临图形界面加载不出来的状况。
其次,磁盘分配空间大于20G。
本人分配内存2G, 磁盘64G,其它配置根据需求调整,本人全部默认。
网络配置的三种模式:(NAT是默认选择)

(2)修改主机名和用户名
在本机中,不建议直接使用管理员用户,因此我们另外创建一个独立的hadoop用户。
在terminal端口中依次执行如下命令:
首次设置权限参考我的另外一篇博文《linux ubuntu 18首次使用root权限》:
打开root
su
创建用户"hadoop":
useradd hadoop
设置密码:
passwd hadoop
我的密码设置为:123456

接下来开始正式修改主机名,修改主机名分为两种情况,一种是临时性修改(重启会消失),另外一种是永久性修改
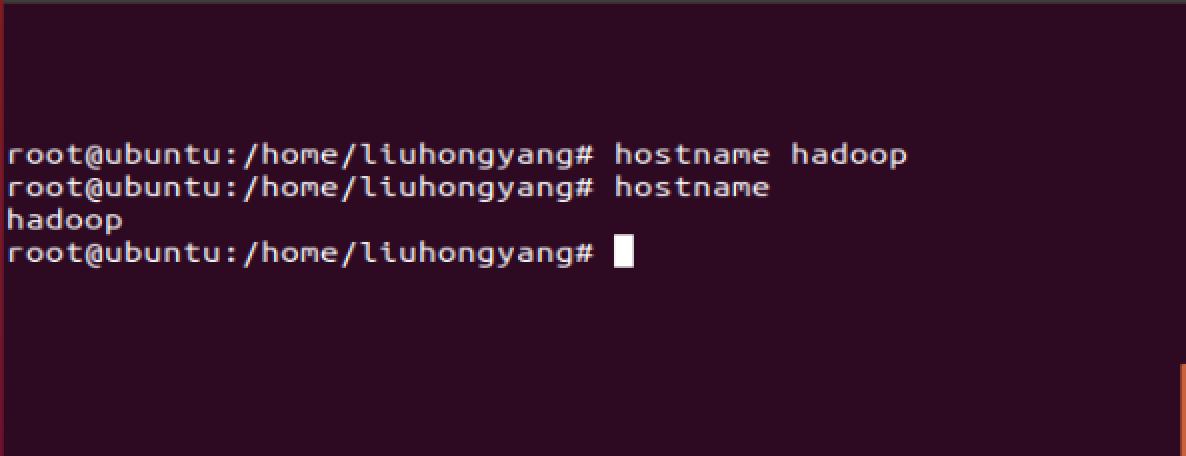
a.暂时性的
hostname <主机名>
hostname hadoop
b.永久性的(centos系统配置)
vim /etc/sysconfig/network
服务器重启
注:由于操作系统的不同,比如ubuntu下并无/etc/sysconfig路径,
查看我的另外一篇博客《Ubuntu hadoop配置之修改主机名》
本人修改文件主机名为:master
/etc/hostname修改主机名
/etc/hosts修改主机名默认ip
修改后的结果:

(3)配置静态ip
ubuntu设置静态ip有两种方式
a.通过图形化界面
在图形化界面过程中,点击右上角图标

然后找到配置选项,更改选项卡,选择IPV4,DHCP改成Manual
接下来查询配置IP信息
本机采用Shared Network

得到详细网络信息

接着在ubuntu中配置即可
b.命令行进行配置(centos)
vim /etc/sysconfig/network-scripts/ifcfg-eth0
service network restart
若想对ubuntu,命令行进行静态ip配置。参考我的另外一篇博文《ubuntu命令行配置静态IP》
最后记得设置一下,主机名与静态IP之间映射关系
vim /etc/hosts
IP地址 <主机名>

(4)配置SSH无密码登录
使用yum install ssh命令安装ssh
注:1.若无yum,则在root权限下使用apt install yum,然后再切换回hadoop用户
2.在配置过程中,若出现无法解析nameserver的情况,参考以下一条链接
https://datawookie.netlify.com/blog/2018/10/dns-on-ubuntu-18.04/
(以下操作需要以hadoop用户的名义)
安装ssh协议:
sudo apt-get install ssh
sudo apt-get install rsync
或者
yum install ssh
yum install rsync
启动ssh命令
注意,要在hadoop命令下执行
我们可以给hadoop用户添加权限,请参考我的另外一篇博文,如何《Ubuntu系统添加用户权限》
(5)安装JDK
请在如下目录下载jdk
https://www.oracle.com/technetwork/java/javase/downloads/jdk7-downloads-1880260.html
下载完成后执行如下命令:
tar -xzf <jdk>
进行解压

然后配置环境变量
gedit /etc/profile
添加JAVA_HOME和PATH

source /etc/profile
添加完成后
执行 java -version 和 javac
若出现如下命令,则意味着java环境变量配置成功

(6)配置Hadoop
1.下载hadoop文件,binary文件
http://mirror.bit.edu.cn/apache/hadoop/common/hadoop-3.1.2/hadoop-3.1.2.tar.gz
2.在/etc/profile中修改如下文件: 
按照上图配置环境变量
然后输入 source /etc/profile
3.修改hadoop-env.sh 添加如下两个变量
export /home/liuhongyang/Downloads/hadoop2.7
export /home/liuhongyang/Downloads/jdk1.8

4.配置/etc/hadoop 目录下文件
配置core-site.xml中fs.defaultFS

5.配置hdfs-site.xml中dfs.replication
由于是伪分布式,将value值改为1

6.格式化NameNode
作用:清空NameNode目录下的所有数据,生成目录结构,初始化一些信息到/tmp下
hdfs namenode -format

7.启动HDFS各个进程
直接输入命令:start-dfs.sh

若未在profile中配置sbin路径,请切换到hadoop目录下输入sbin/start-dfs.sh
或者
单个启动后台进程
sbin/hadoop-daemon.sh start namenode
sbin/hadoop-daemon.sh start datanode
sbin/hadoop-daemon.sh start secondarynamenode
8.浏览器访问
http://<主机名>:50070

表示配置成功过
9.配置yarn
配置mapred-site.xml文件,若无这个文件,将mapred-site.xml.template文件复制一份,命名为mapred-site.xml

配置yarn-site.xml文件

10. 启动yarn进程
start-yarn.sh
或者单个启动:
sbin/yarn-daemon.sh start resourcemanager
sbin/yarn-daemon.sh start nodemanager
11.浏览器访问
http://<主机名>:8088

此时表示配置成功
最后,若想查询进程输入jps
杀掉进程使用kill,用法如下
















 161
161











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









