







python3爬虫(基于requests、BeautifulSoup4)之项目实战(三)
今天是爬取太原理工大学教务处网站新闻的最后一天,我今天将讲解如何循环嵌套爬取每一条新闻及对应的新闻详情。
1.案例分析:
这是我们要爬取的位置以及每一篇新闻对应正文,通过html代码分析,我们可以整理出如下大体思路:
1.1抓取每篇新闻的链接
1.2到对应链接抓取文章具体信息
通过思路整理,我们可以看出要实现‘自动化爬取’,首先要有一个教务处官网url,之后要抓取全部新闻url,最后用for循环到每一篇文章对应界面上抓取具体内容。
好了,废话不多说了,直接上代码了:

import requests
from bs4 import BeautifulSoup
def getallurls(url):#将主页的新闻界面url全部读取存入列表返回
result=[]
res=requests.get(url)
res.encoding = 'utf-8'
soup=BeautifulSoup(res.text,'html.parser')
urls=soup.select('.intmc a')
for a in urls:
re=url+'/'+a['href']
# print(a.text)
result.append(re)
return result
def getMaininfo(url):#读取每篇新闻的详情
res=requests.get(url)
res.encoding='utf-8'
soup=BeautifulSoup(res.text,'html.parser')
results=soup.select('.drlrimess p')
for result in results:
print(result.text)
def getTitle(url):#读取每篇新闻的标题
res = requests.get(url)
res.encoding = 'utf-8'
soup = BeautifulSoup(res.text, 'html.parser')
urls = soup.select('title')
print(urls[0].text)
def getCount(url):#获取访问量 难点!!!!涉及js
res = requests.get(url)
res.encoding = 'utf-8'
soup = BeautifulSoup(res.text, 'html.parser')
x=soup.select('table script')[0].text.replace(' ','').strip(')').split(',')
resulturl='http://jwc.tyut.edu.cn/system/resource/code/news/click/dynclicks.jsp?clickid={}&owner={}&clicktype=wbnews'.format(x[2],x[1])
count=BeautifulSoup(requests.get(resulturl).text,'html.parser')
print('访问量:',count)
if __name__ == '__main__':
url='http://jwc.tyut.edu.cn'
for i in getallurls(url):
getTitle(i)
getCount(i)
getMaininfo(i)
print('='*50)
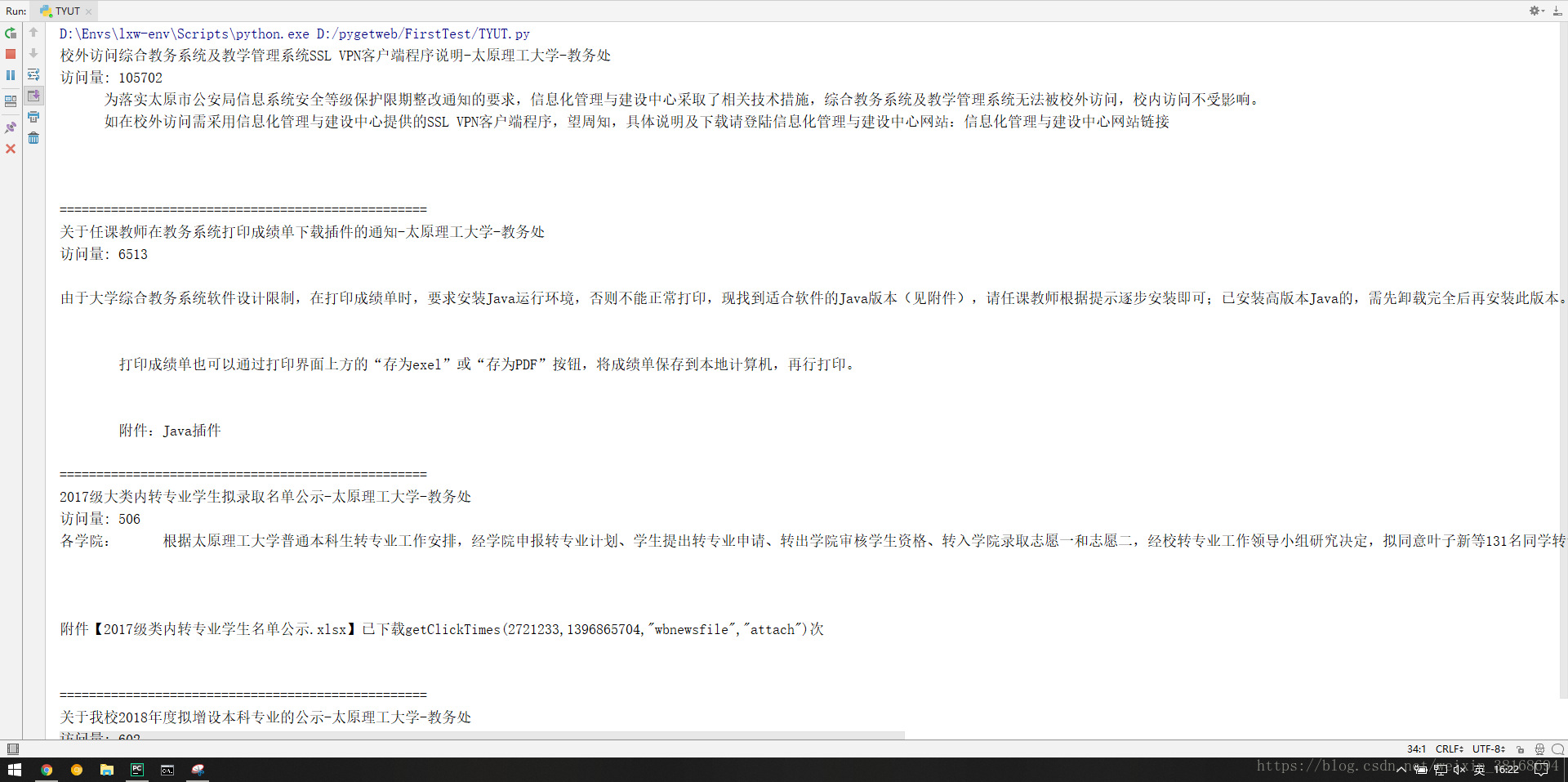
程序效果如下:














 184
184











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









