






DBSCAN聚类算法学习及实践
一、 原理学习
DBSCAN聚类算法是基于密度的聚类算法。该算法适合稠密的数据集的分类,但是对于密度不均匀聚类间距大的数据集聚类的质量较差。该算法可以自行对数据集的聚类数量做出判断,同时对于异常点可以在聚类的时候发现。
二、实验结果
a、使用sklearn的datasets.make_circles生成的随机二维数据。
初始参数设置为ϵ=0.4, MinPts =3,发现如图1-1所示,只有一个类。想要增加类别可通过降低参数ϵ或者增大参数MinPts。首先通过降低ϵ值,一直试验到0.1发现已经最好了出现如图1-2所示结果,但是中间应当是两个类,故再次通过增大MinPts值,最终发现将值设置为6时出现三个类,如图1-3所示。得到最终参数设置e ϵ=0.1, MinPts =6。
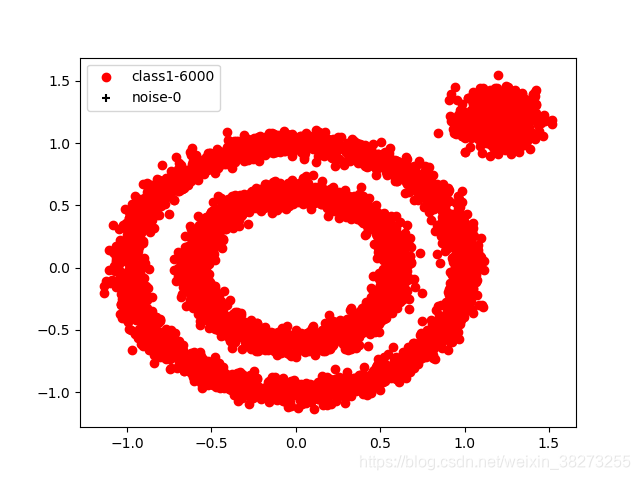
图1-1 ϵ=0.4, MinPts =3
图1-1 ϵ=0.4, MinPts =3
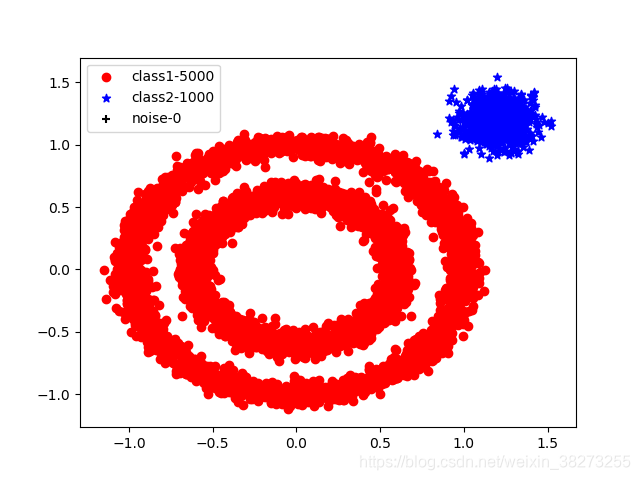
图1-1 ϵ=0.1, MinPts =3
图1-1 ϵ=0.1, MinPts =3
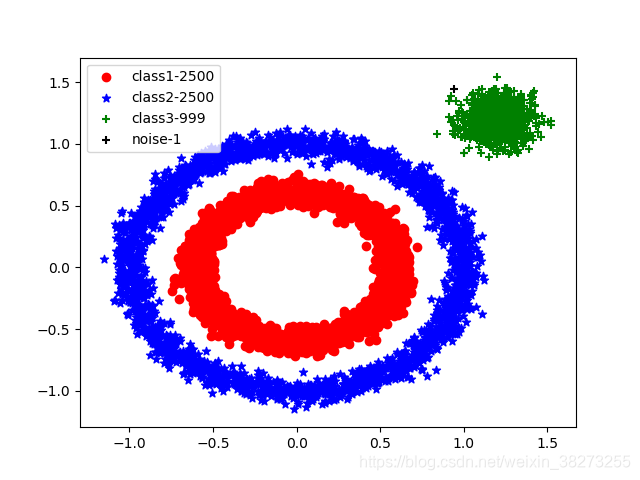
图1-3 ϵ=0.1, MinPts =6
图1-3 ϵ=0.1, MinPts =6
b、对iris数据集试验
对数据集的三四两个维度的特征属性进行调参(降低ϵ值或者增大MinPts值可增加类别),得到图1-1和图1-2所示的结果。图1-1显示为ϵ=0.4, MinPts =5的结果,可以看出分为两个类时聚类效果很好,但是数据集是三个类的数据。故将参数调整到ϵ=0.2, MinPts =5,得到图1-2所示的结果,这时因为后两个类的间距和第一个类的间距差别较大,也就是密度不均匀因而聚类的效果不好。
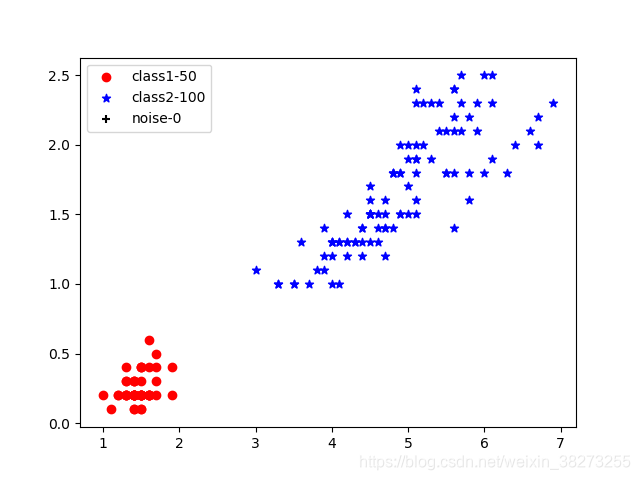
图2-1 ϵ=0.4, MinPts =5
图2-1 ϵ=0.4, MinPts =5
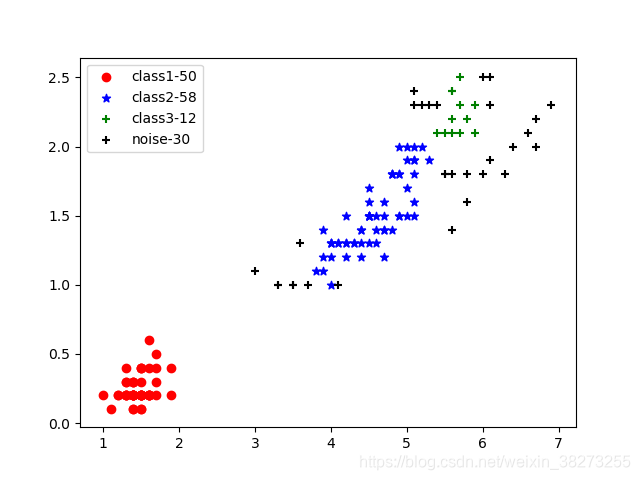
图2-2 ϵ=0.2, MinPts=5
图2-2 ϵ=0.2, MinPts=5
对数据集的一二两个维度的特征属性进行调参,得到图1-3所示的结果。从图中可以看出所得聚类结果还算可以,但是在红色的聚类附近大量的噪音点肉眼感觉可将其归入,这就是密度的不均匀造成的。对一到四这四个维度的特征值进行聚类得到了图1-4所示的结果,结果为47/38/36。此效果图是通过三四两个维度绘制,所以看起来可能会有些出入,总体效果还是相对较好的。
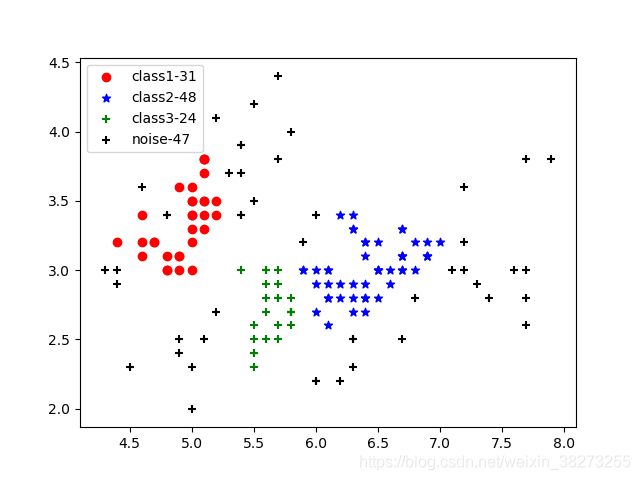
图2-3 ϵ=0.2, MinPts =5
图2-3 ϵ=0.2, MinPts =5
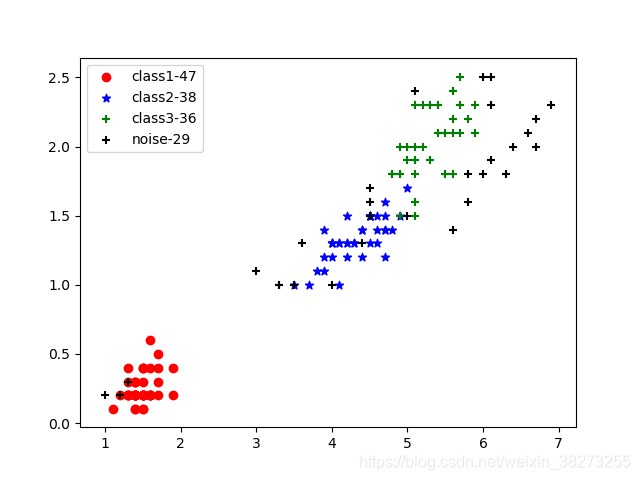
图2-4 ϵ=0.4, MinPts=4
图2-4 ϵ=0.4, MinPts=4
P.S.代码参考及使用sklearn实现。
import matplotlib.pyplot as plt
import numpy as np
from sklearn.cluster import KMeans
from sklearn import datasets
from sklearn.cluster import DBSCAN
# wine = datasets.load_wine()
# X = wine.data[:, :13] # #表示我们只取特征空间中的4个维度
iris = datasets.load_iris()
X = iris.data[:,:4]
# X1, y1=datasets.make_circles(n_samples=5000, factor=.6,
# noise=.05)
# X2, y2 = datasets.make_blobs(n_samples=1000, n_features=2, centers=[[1.2,1.2]], cluster_std=[[.1]],
# random_state=9)
# X = np.concatenate((X1, X2))
print(X.shape)
# 绘制数据分布图
# plt.scatter(X[:, 0], X[:, 1], c="red", marker='o', label='see')
# plt.xlabel('petal length')
# plt.ylabel('petal width')
# plt.legend(loc=2)
# plt.show()
# :2 0.2,5
# 2:4 0.4,5 0.2 5
# :4 0.4,4
# datasets.make_circles eps=0.1, min_samples=6
dbscan = DBSCAN(eps=0.4, min_samples=4)
dbscan.fit_predict(X)
#fit_predict
label_pred = dbscan.labels_
color = ["red","blue","green","gray","black"]
marker = ['o','*','+',]
for i in range(max(label_pred)):
x = X[label_pred == i]
print(len(x))
plt.scatter(x[:, 2], x[:, 3], c=color[i%5], marker=marker[i%3], label='class'+ str(i+1) + '-' + str(len(x)))
x1 = X[label_pred == 3]
print(len(x1))
plt.scatter(x1[:, 2], x1[:, 3], c=color[-1], marker=marker[-1])
x = X[label_pred == -1]
print(len(x))
plt.scatter(x[:, 2], x[:, 3], c=color[-1], marker=marker[-1], label='noise' + '-' + str(len(x)+len(x1)))
# 绘制k-means结果
# plt.xlabel('petal length')
# plt.ylabel('petal width')
plt.legend(loc=2)
plt.show()














 5664
5664











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









