






Java领域的io模块是一个非常庞大的知识体系,在大家求职面试的过程中通常也是被问到比较多的一个模块,今天我特意整理了一份关于IO知识体系相关的干货和大家分享,希望各位读者们喜欢。
如何理解io流
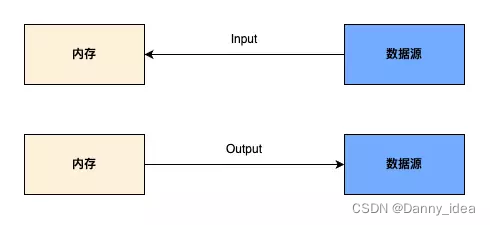
io可以理解为是input 和 output的两个缩写,分别代表了数据的”输入“和”输出“。io流则是描述了将数据从内存和数据源之间拷贝的一个过程。
输入:数据从数据源加载到内存。
输出:数据从内存写回到数据源。
这里我所说的数据源是一个比较泛的名称,它可以是指 txt,图片,SQL,mp4等格式的文件。
Java的io流分类
字符流和字节流
在java语言的IO体系内部主要划分为了两大类别,字节流和字符流 。
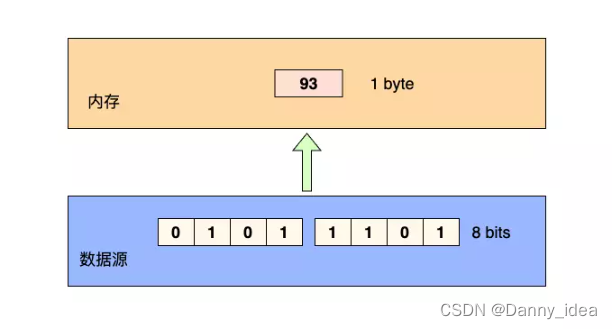
字节流
该类流每次读取数据的时候都会以字节作为基本单位进行数据的读取,通常都会有InputStream和OutputStream相关字眼。例如读取数据的时候每次如同下图所示,每次都按照字节进行加载。
字符流
该类流通常都会以字符的形式去读取数据信息,其读取的效率通常要比字节流更高效。相关的类通常都会带有Reader或者Writer相关字眼。
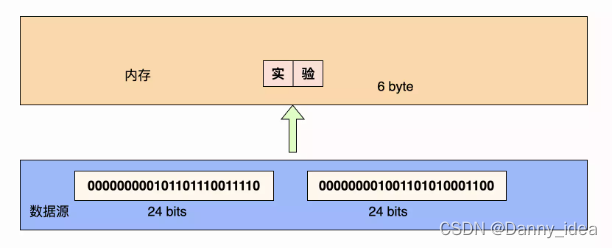
ps:上图中的24bit是相关汉字在UTF8编码下转换为二进制的形式
思考:字符流和字节流在使用场景方面有什么不同点
字符流通常比较适合用于读取一些文本数据,例如txt格式类型的文本,这类资源通常都是以字符类型数据进行存储,所以使用字符流要比字节流更加高效。而对于一些二进制数据,例如图片,mp4这类资源比较适合用字节流的方式进行加载。
再往深入思考下,我们的字符流和字节流既然都要涉及到数据信息的读取和写入,那么就一定会涉及到输入和数据,所以在基于字节流和字符流的基础上又扩展出了以下四种类别:
字节输入流
字节输出流
字符输入流
字符输出流
除了我们所说的输入和输出之外,流还会涉及到各种类型的数据源,和不同类型的数据源打交道就需要使用不同类型的io流,这里我整理了一份表格,大家请看:
| 分类 | 字节输入流 | 字节输出流 | 字符输入流 | 字符输出流 |
|---|---|---|---|---|
| 抽象接口 | InputStream | OutputStream | Reader | Writer |
| 访问文件 | FileInputStream | FileOutputStream | FileReader | FileWriter |
| 访问数组 | ByteArrayInputStream | ByteArrayOutputStream | CharArrayReader | CharArrayWriter |
| 访问管道 | PipedInputStream | PipedOutputStream | PipedReader | PipedWriter |
| 访问字符串 | StringReader | StringWriter |
节点流和处理流
随着使用的增加,开始有程序员希望对已有的这些io流做一些优化改善,于是便出现了节点流和处理流这么些概念。
节点流:直接对特定的数据源执行读写操作。
处理流:对一个已经存在的流做一些二次封装操作,其功能更加比原先更加强大。
下边我对常见的节点流和处理流也给大家做了一份表格进行整理
| 分类 | 字节输入流 | 字节输出流 | 字符输入流 | 字符输出流 | 类型 |
|---|---|---|---|---|---|
| 抽象接口 | InputStream | OutputStream | Reader | Writer | 节 点 流 |
| 访问文件 | FileInputStream | FileOutputStream | FileReader | FileWriter | 节 点 流 |
| 访问数组 | ByteArrayInputStream | ByteArrayOutputStream | CharArrayReader | CharArrayWriter | 节 点 流 |
| 访问管道 | PipedInputStream | PipedOutputStream | PipedReader | PipedWriter | 节 点 流 |
| 访问字符串 | StringReader | StringWriter | 节 点 流 | ||
| 缓冲流 | BufferedInputStream | BufferedOutputStream | BufferedReader | BufferedWriter | 处 理 流 |
| 打印流 | PrintStream | PrintWriter | 处 理 流 | ||
| 对象流 | ObjectInputStream | ObjectOutputStream | 处 理 流 | ||
| 转换流 | InputStreamReader | OutputStreamWriter | 处 理 流 |
下边我们对每种流都进行详细的介绍。
常用节点流介绍
FileInputStream 和 FileOutputStream
通常FileInputStream流会用于以字节的方式去读取文件信息,常用代码Demo如下:
public static void readFile() {
FileInputStream fileInputStream = null;
try {
fileInputStream = new FileInputStream(new File("/Users/linhao/IdeaProjects/architect-framework/architect-framework-io/file/text.txt"));
byte[] readData = new byte[10];
int bufferSize = 0;
//如果读取正常,会返回实际读取的字节数
while ((bufferSize = fileInputStream.read(readData)) != -1){
System.out.print(new String(readData,0,bufferSize));
}
System.out.println();
}catch (Exception e){
e.printStackTrace();
} finally {
//关闭文件流,释放资源
try {
//这个异常只要保证的确执行了close操作即可
fileInputStream.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}使用注意点:
流需要进行关闭操作
使用read函数的时候,当文件读取正常时候会返回实际的字节数
FileOutputStream是文件的字节输出流,常见使用案例demo如下:
public static void writeFileVersion1() {
String filePath = "/Users/linhao/IdeaProjects/architect-framework/architect-framework-io/file/text_2.txt";
FileOutputStream fileOutputStream = null;
try {
//如果通过new FileOutputStream(filePath)的方式执行写入,实际上数据是会覆盖原先的内容,所以根据构造函数的第二参数来实现追加的效果
fileOutputStream = new FileOutputStream(filePath,true);
fileOutputStream.write("input sth".getBytes());
fileOutputStream.write("input sth2".getBytes());
}catch (Exception e){
e.printStackTrace();
} finally {
try {
fileOutputStream.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}注意在
FileOutputStream的构造函数中,可以通过定义第二个append参数去设置写入的模式(覆盖模式还是追加模式)。使用字符输入流的时候,即使没有走到close函数,数据也会被持久化写入到磁盘。
思考:使用上方这段代码去读取文本信息的时候是否会出现乱码情况?
其实是会存在问题的。为了和大家解释具体原因,我做了这么一个测试。
首先在一份指定的txt文件中用UTF-8编码写入10个中文字符(一共占用30个字节)
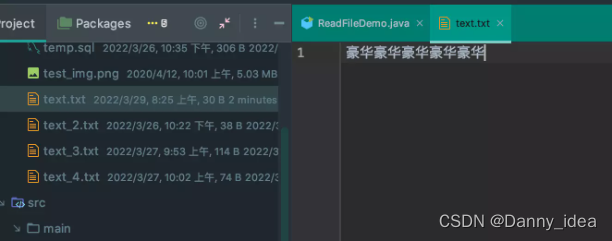
而我们的程序中每次都是以10个字节为基础加载数据,所以有部分的汉字可能读取到了1/3的内容就中断了,从而导致出现乱码。

思考:如何解决这种情况?
增大每次读取的字节数组大小
这种思路,不够灵活,而且如果文件信息量非常庞大的话,每次读取的字节数组也会有上限。(数组的体积最大值为2^31-1)。如果需要做每次读取一部分数据并且进行一些业务过滤操作的话,这种方式并不灵活。
每次读取的字节数是编码占用字节数的倍数
例如我们使用了UTF-8编码,那么每次读字节的时候就使用3的成倍数去读内容,如9,12,21。但是这类读取也是会存在问题,假设是一份携带有英文字符的文本就会出现读取内容缺失的情况。
使用字符流的方式读取
这种方式可以很好地解决上边我们所说的几类问题,例如使用FileReader流。
FileReader 和 FileWriter
FileReader相关案例代码:
public static void readFile(){
FileReader fileReader = null;
try {
fileReader = new FileReader("/Users/linhao/IdeaProjects/architect-framework/architect-framework-io/file/text.txt");
char[] chars = new char[3];
int readLen = 0;
while ((readLen=fileReader.read(chars))!=-1){
System.out.println(new String(chars,0,readLen));
}
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
fileReader.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}FileReader字符流支持每次读取文件的时候按照char为基本单位进行读取,这款io流非常适合用于读取一些小的文本内容。同样的,FileReader的read函数在调用完之后会返回读取到的文本内容长度,如果长度为-1,则表示读取到的内容已经结束。
说完了FileReader,我们再来聊聊FileWriter。FileWriter是一款基于字符为基本单位的输出流,可以用于往文本文件内部写入一定的数据。下边是它的案例代码:
/**
* 记得追加模式和close/flush
*/
public static void writeFileVersion1(){
FileWriter fileWriter = null;
try {
//默认是覆盖模式
// fileWriter = new FileWriter("/Users/linhao/IdeaProjects/architect-framework/architect-framework-io/file/text_3.txt");
fileWriter = new FileWriter("/Users/linhao/IdeaProjects/architect-framework/architect-framework-io/file/text_3.txt",true);
fileWriter.write("this is test\n");
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
//底层使用了sun.nio.cs.StreamEncoder.writeBytes,
//底层其实是使用了Nio 的 bytebuffer做数据实际刷盘操作
//所以其实底层还是使用了byte作为基本单位来进行操作
fileWriter.close();
//flush也会写入数据,但是没有执行close操作
// fileWriter.flush();
} catch (IOException e) {
e.printStackTrace();
}
}
}需要注意点:
使用完毕后如果不执行close操作或者flush操作则并不会将实际的内容持久化输出到磁盘当中。这一点和
FileOutputStream很不一样。在使用
FileWriter的构造函数中,有一个append的布尔类型变量,用于声明当前的数据写入之后是否会覆盖原先的内容。
具体源代码如下:
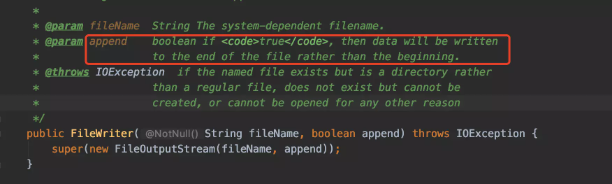
使用流结束之后记得要手动调用close函数,执行关闭行为操作。
PipedInputStream 和 PipedOutputStream
管道流通常会被我们用在不同的线程之间进行消息通讯中使用。
例如下边这段代码,定义了一个子线程,该线程会往PipedOutputStream中写入数据,然后main线程会去PipedInputStream中读取子线程写入的数据。
/**
* out底层是用了一个字节缓冲数组buffer接收数据传输,当这个字节缓冲数组满了之后通过使用notifyAll唤醒in内部读数据的线程
* 所以这里面的底层原理还是离不开sync和notifyall
* @param args
*/
public static void main(String[] args) {
try (PipedOutputStream out = new PipedOutputStream()) {
PipedInputStream in = new PipedInputStream(out);
new Thread(() -> {
try {
Thread.sleep(2000);
String item = new String();
for (int i=0;i<1000;i++){
item = item + "1";
}
out.write(item.getBytes(StandardCharsets.UTF_8));
out.close();
} catch (IOException | InterruptedException e) {
e.printStackTrace();
}
}).start();
int receive = 0;
System.out.println("try");
byte[] temp = new byte[1024];
//等待子线程往pipedOutputStream内部写入数据
while ((receive = in.read(temp)) != -1) {
String outStr = new String(temp,0,receive);
System.out.println(outStr);
}
} catch (Exception e) {
e.printStackTrace();
}
}常用处理流介绍
BufferedInputStream 和 BufferedOutputStream
这类流在传统的字节流基础上做了一层包装,单纯的字节节点流每次处理数据读取或者写入的时候都是直接对磁盘进行字节为单位的io操作,所以性能方面会有一定的缺陷。缓冲字节流的出现就是通过引入一个缓冲Buffer的来优化这种多次读写操作导致的io性能不足的设计。
缓冲字节处理流的内部存在一个叫做buffer的缓冲区,每次写入数据的时候都会往缓冲区中写入数据,当缓冲区积攒了足够多的数据后再一次性写回到数据源中。这种设计思路相比原先的一次写一次io要高效更多。
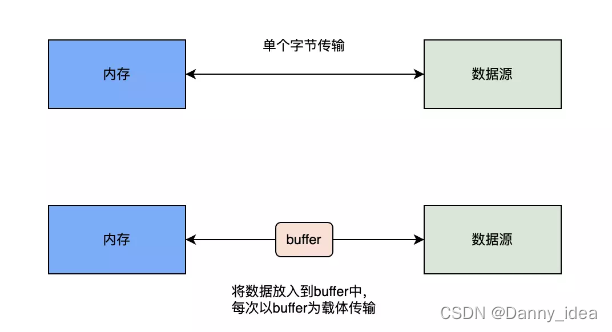
思考:BufferedInputStream和BufferedOutputStream如何使用呢?
可以参见下边这段实际代码:
//基于字节为单位实现文件拷贝效果
public static void fileCopyByByte(String sourceFile,String destPath) throws IOException {
BufferedInputStream bufferedInputStream = new BufferedInputStream(new FileInputStream(sourceFile));
BufferedOutputStream bufferedOutputStream = new BufferedOutputStream(new FileOutputStream(destPath));
byte[] tempByte = new byte[1024];
int tempByteLen = 0;
while ((tempByteLen = bufferedInputStream.read(tempByte)) != -1) {
bufferedOutputStream.write(tempByte,0,tempByteLen);
}
bufferedOutputStream.close();
bufferedInputStream.close();
}注意点:
BufferedInputStream和BufferedOutputStream内部采用了修饰器模式,通过构造函数注入一个java.io.InputStream/java.io.OutputStream对象,从而达到可以注入多种字节输入输出流。当关闭流的时候只需要关闭外界包装的字节缓冲流即可,它的close操作会触发对应的字节流内部的close函数。
使用缓冲处理流的时候要记得调用close或者flush操作才能将实际数据真正写入到磁盘当中。
PrintStream 和 PrintWriter
这两个流分别是基于字节和字符的输出打印流,下边是这款io流的使用demo:
PrintStream
public static void main(String[] args) throws IOException {
//重新设置流输出的位置,底层是一个native方法
System.setOut(new PrintStream("/Users/linhao/IdeaProjects/architect-framework/architect-framework-io/file/out.log"));
PrintStream out = System.out;
out.println("john hello");
//底层也可以使用字节数组
out.write("test".getBytes());
out.close();
}PrintWriter
public static void main(String[] args) throws FileNotFoundException {
//重新设置流输出的位置,底层是一个native方法控制
PrintWriter out = new PrintWriter("/Users/linhao/IdeaProjects/architect-framework/architect-framework-io/file/out.log");
out.println("john hello");
//底层也可以使用字节数组
out.write("test");
out.close();
}其实在我们日常开发中经常会接触到PrintStream这款标准输出字节流,例如我们刚入门阶段所接触的helloworld案例,底层就是基于PrintStream去做的:
System.out.printf("hello world");另外关于系统输出和系统输入部分,我在这里列出了一段代码,大家可以尝试运行看看它们分别是哪些流负责管控的。
public static void main(String[] args) {
//inputStream对象
//inputstream是标准输入,会从键盘那边寻找输入内容
//实现类是:java.io.BufferedInputStream
System.out.println(System. in.getClass());
//outputStream对象
//outputStream是标准输出,会从显示器中获取输出数据
//实现类是:java.io.PrintStream
System.out.println(System.out.getClass());
}InputStreamReader 和 OutputStreamWriter
这两类IO是属于转换流方面的代表,最常使用于不同编码格式直接的流读取场景中。例如当我们的一份文件采用了GBK编码,然后读取的程序采用的默认编码为UTF-8,那么就会导致读取出来的数据是乱码的格式。为了解决这种问题,人们设计了转换流来应对,这方面的案例代码如下所示:
按照指定编码格式写入和读取数据
public static void main(String[] args) throws IOException {
//这份文件默认是采用了gbk编码
String filePath = "/Users/linhao/IdeaProjects/architect-framework/architect-framework-io/file/file_1.txt";
//系统默认编码格式是utf-8,这里需要手动设置为gbk编码
OutputStreamWriter osw = new OutputStreamWriter(new FileOutputStream(filePath),"gbk");
osw.write("测试语句");
osw.close();
System.out.println("=================");
InputStreamReader isr = new InputStreamReader(new FileInputStream(filePath),"gbk");
char[] chars = new char[1024];
int len = isr.read(chars);
System.out.println(new String(chars,0,len));
isr.close();
}ObjectInputStream 和 ObjectOutputStream
对象输入和对象输出流是我们在工作中经常会使用到的一款IO流,先来介绍下它的设计背景。
思考:如果我们从IO输入流中读取到100这个数据的时候,如何判断这项数据的类型是属于数字还是字符串类型呢?
为了能让开发者在读取数据源的时候同时了解更多数据的属性,人们设计出了对象输入/输出流。使用对象输入流/输出流的时候,可以按照不同的格式对数据源进行读取或者写入。下边来看一份实操的案例代码:
//将一个对象持久化写入到一份文件中
public static void writeObjDemo() throws IOException {
String destPath = "/Users/linhao/IdeaProjects/architect-framework/architect-framework-io/file/obj_1.dat";
//对象输出流
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream(destPath));
oos.writeInt(100); // int -> Integer类型(实现序列化)
oos.writeBoolean(true); // bool -> Boolean类型(实现序列化)
oos.writeDouble(1.1); // double -> Double类型(实现序列化)
oos.writeChar('a'); // char -> Charater类型(实现序列化)
oos.writeUTF("测试语句"); // String类型(实现序列化)
oos.writeObject(new Dog(101,"name1")); //自定义对象 (实现序列化)
oos.close();
}//将文件中的数据读取出来,转换为一个对象
public static void readObj() throws IOException, ClassNotFoundException {
String destPath = "/Users/linhao/IdeaProjects/architect-framework/architect-framework-io/file/obj_1.dat";
ObjectInputStream ois = new ObjectInputStream(new FileInputStream(destPath));
System.out.println(ois.readInt());
System.out.println(ois.readBoolean());
System.out.println(ois.readDouble());
System.out.println(ois.readChar());
System.out.println(ois.readUTF());
Dog dog = (Dog) ois.readObject();
System.out.println(dog);
ois.close();
}从代码中可以看出ObjectInputStream和ObjectOutputStream所提供的Api接口还是比较好理解的,但是在实际使用这两类IO流的时候需要注意以下几点:
读写顺序要一致
如果是按照int,string,int的顺序进行序列化,那么反序列化的步骤也需要按照int,string,int的顺序来执行
被序列化的对象必须要求实现serializable接口
这块是一种规范的约定,开发者们准守即可。
被序列化的对象建议添加serialVersionUid关键字
这样可以在序列化的时候不会将转换对象识别为一个新的类,而是当成是原有对象的一个升级版本。
对象内部参与序列化的字段要求皆可序列化
我们平时在定义属性中常用了基本类型例如int,long,double,其实在底层都被进行了装箱的操作,变成了可序列化的Integer,Long,Double类。如果被序列化对象中包含了一个自定义的对象,那么这个自定义的对象也一定要支持可序列化。
序列化具备可继承特性
如果某个父类已经实现了序列化接口,那么它的子类也默认实现了序列化
思考:如果没有设置serialVersionUid关键字,在进行序列化的过程中可能会遇到什么问题
假设我们原先的对象A中有id,name两个字段,该对象在被序列化之后存储到temp文件中。
此时对A对象进行了升级变成了A_1对象,字段变为了id,name,age,此时将temp文件夹中存储的内容重新反序列化到A_1对象上,就会出现报错异常,例如下边所示:
Exception in thread "main" java.io.InvalidClassException: org.idea.architect.framework.io.节点流.Dog; local class incompatible: stream classdesc serialVersionUID = 198678371, local class serialVersionUID = 4180152316968275835
at java.io.ObjectStreamClass.initNonProxy(ObjectStreamClass.java:699)
at java.io.ObjectInputStream.readNonProxyDesc(ObjectInputStream.java:1885)
at java.io.ObjectInputStream.readClassDesc(ObjectInputStream.java:1751)
at java.io.ObjectInputStream.readOrdinaryObject(ObjectInputStream.java:2042)
at java.io.ObjectInputStream.readObject0(ObjectInputStream.java:1573)
at java.io.ObjectInputStream.readObject(ObjectInputStream.java:431)
at org.idea.architect.framework.io.节点流.ObjectInputStreamDemo.readObj(ObjectInputStreamDemo.java:19)
at org.idea.architect.framework.io.节点流.ObjectInputStreamDemo.main(ObjectInputStreamDemo.java:25)如果一个对象在进行序列化操作的时候没有声明serialVersionUid关键字,在jdk底层会自动根据字段属性给它生成一个serialVersionUid关键字,这也就意味着当原先对象的字段发生变动的时候,这个serialVersionUid字段值也会变动。
这里报错的内容就是因为序列化和反序列化过程中会通过判断serialVersionUid来识别是否是对同一种类型的对象操作,如果原先对象的字段属性发生了变动则会导致serialVersionUid值发生变化从而抛出异常。
推荐:

PS:因为公众号平台更改了推送规则,如果不想错过内容,记得读完点一下“在看”,加个“星标”,这样每次新文章推送才会第一时间出现在你的订阅列表里。点“在看”支持我们吧!














 288
288











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









