









Hexagon_DSP_User_Guide (2)
(2))
4.2Guidelinesforassemblyandintrinsicoptimization
为了编写高效的汇编代码,有几个基本的概念需要牢记。这些概念对于使用内含物编写的开发人员来说也是相当重要的,因为这样的开发人员应该知道编译器大约应该如何分组和安排内含物,以达到最大的性能。
本节简要介绍了这些基本概念中的一些。
提示:当用内含物或汇编指令编写代码时,最好先用正确的指令编写功能代码,然后才按照下面几节讨论的优化准则进一步优化代码。试图一次做太多的事情往往更耗费时间,因为低级别的优化通常会掩盖了代码的清晰性。
4.2.1 Maximizeinstructionsperpacket
每个硬件线程能够在一个给定的线程周期内执行一个最多四个指令的包。在一个数据包中出现的指令是并行执行的,这使得在一个数据包中可以同时消耗一个寄存器并更新其内容。例如,下面的数据包消耗了前面的数据包中产生的R0的内容,然后用R4更新其内容。
{ R2 = vaddh(R0,R1)
} R0 = R4
The exception to this rule is when the specifier .new is used within an instruction. For example, the following packet first computes R2 and then store its content to memory.
{ R2 = memh(R4+#8)
} memw(R5) = R2.new
为了使每个数据包的指令数量最大化,必须了解每个数据包中的指令可以或不可以被组合。这些限制对于标量指令和HVX指令是不同的。
4.2.1.1 Scalarinstructionpackingrules
关于如何形成数据包的规则在《Hexagon V66程序员参考手册》(80-N2040-42)的指令包部分有解释。
重点掌握将指令打包在一起的最重要限制:资源限制。
理解资源限制对用V66进行分组的影响的最简单方法是简单地从槽的角度考虑。由于它们使用的资源,每一类指令只能在四个可用的插槽中的一个特定插槽上执行。例如,逻辑和乘法操作消耗2号或3号槽,而加载指令消耗0号或1号槽。这意味着在一个数据包中最多可以执行两个逻辑运算,或一个逻辑运算和一个乘法运算,或两个乘法运算。
Hexagon V66程序员参考手册(80-N2040-42)的图3-1以及每条指令的详细描述中都提供了每个插槽可接受的指令类型的描述。为方便起见,该图转载于图4-1。

在同一本手册的指令包部分概述的其他限制,偶尔会导致遵循资源限制的数据包在编译时仍然产生错误信息。然而,这些其他规则往往很少发挥作用,你可以选择随着时间的推移简单地了解它们。
4.2.1.2 HVXpackingrules
关于如何在HVX中形成数据包的规则在《Hexagon V66 HVX程序员参考手册》(80-N2040-44)的VLIW打包规则部分有解释。
HVX指令与V6x共享相同的插槽,并且对每个HVX指令使用的插槽有限制。然而,与V6x不同的是,资源和槽位不是一对一的。作为一个软件开发者,最好是专注于了解每条HVX指令共享哪些资源,并了解这对在数据包中分组指令的能力有何影响,因为在编写HVX代码时很少考虑插槽限制。
资源限制在 Hexagon V66 HVX 程序员参考手册(80-N2040-44)中进行了总结,为了方便起见,在表 4-1 中进行了转载。每条HVX指令的详细描述也说明了它消耗了哪些HVX资源。
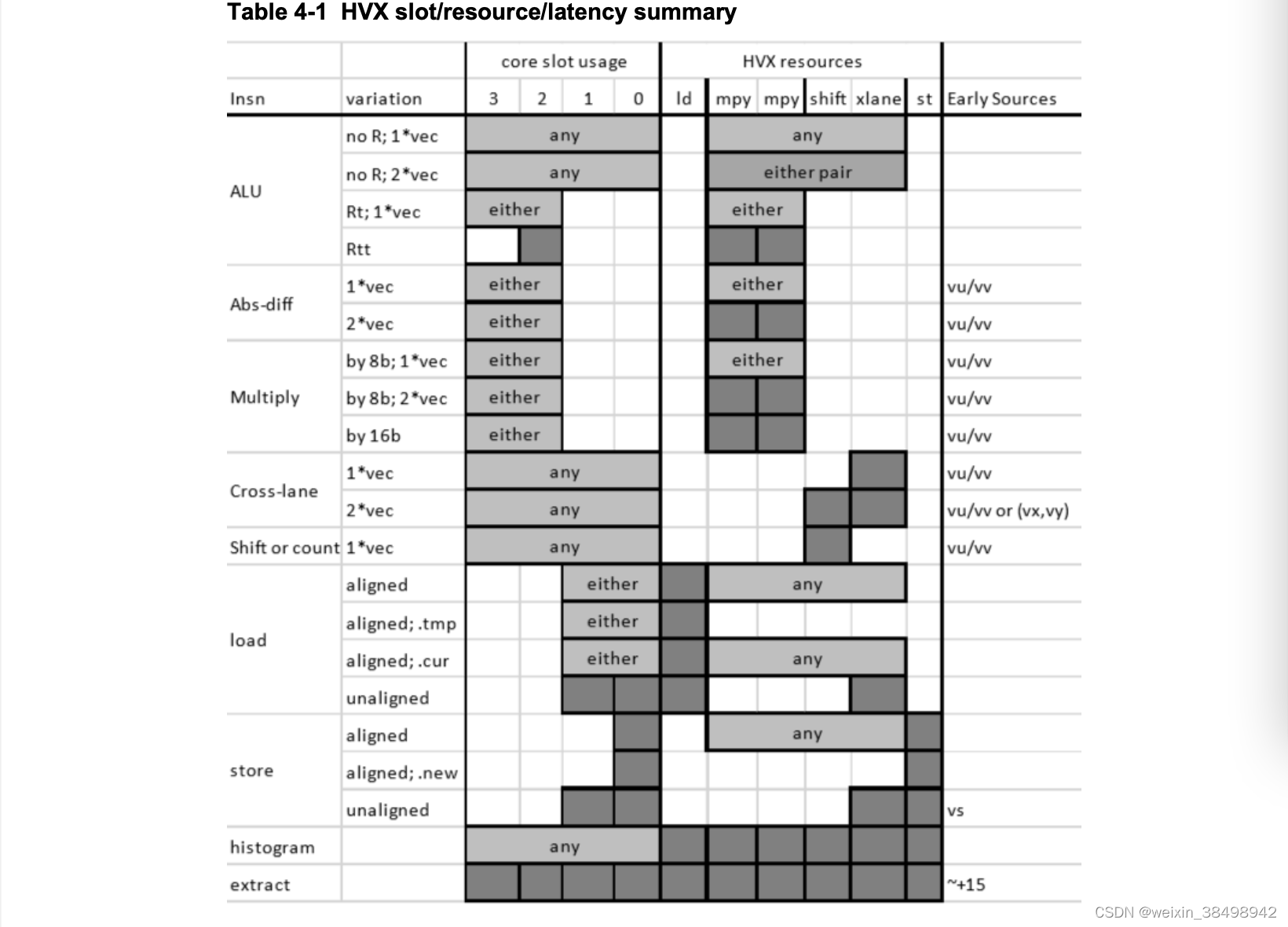
请注意一些指令,如vrmpy,有不同的口味,有些会消耗两个HVX资源,有些只消耗一个。
例如,半字乘法使用两个mpy资源,这意味着在同一个数据包中没有其他HVX乘法指令。当试图优化一个函数乘法的内循环时,要尽早计划如何在尽可能多的数据包中最大化mpy的资源利用率。
与标量存储不同,你不能将两个HVX存储组合在一个数据包中。
4.2.2 Understandandreducestalls
除了在任何给定的数据包中执行尽可能多的指令以最大化并行化外,重要的是要注意可能导致处理器停滞的延迟。本节讨论了导致性能恶化的停顿的最常见原因。
4.2.2.1 Instructionlatencies
4.2.2.1.1 Threadvs.processorcycles
Hexagon内核动态地安排来自线程的数据包进入内核流水线。执行数据包的周期数根据其他线程的行为而变化。孤立运行的单线程的最佳时间表可能不同于与其他线程一起运行的线程的最佳时间表。
例如,在最近几代中,当多个线程并行执行时,每隔一个处理器周期就有一个线程执行。这意味着,如果处理器的时钟为800MHz,四个线程并行执行,每个线程有效地运行在400MHz。
然而,当一个线程空闲时,另一个线程可能会 "偷 "走它的一些周期,使它的运行速度比所有HW线程都忙的时候快。实际上,在Hexagon版本直至SM8250设备上,如果一个单线程工作负载是唯一的运行线程,它的运行速度可能会比与其他运行的SW线程同时消耗所有HW线程时快20%至30%。
在本节的其余部分,我们提供了一些关于延迟调度的一般规则,假设至少有两个线程在运行。这提供了一个简化的编程模型。
利用这个模型,我们引入了数据包延迟的概念。这个延迟是指在两个相依的数据包之间需要调度的数据包的数量,以防止线程停滞。
4.2.2.1.2 Scalarlatencies
从V65开始,指令没有数据包延迟,但有以下例外。
**1.**与.new谓词配对的指令,允许两条连续的指令在同一个数据包内执行。
**2.**预测错误的跳转,通常会产生大约5个包的停顿并浪费能量。有关投机性分支的更多信息,请参见《Hexagon V66程序员参考手册》(80-N2040-42)中的比较跳跃部分。
**注意:**只要有可能,尽量使用硬件循环:这些不会产生停顿,甚至在退出循环时也是如此。
**3.**长延时指令,消耗另一条长延时指令的结果。这些指令会有一个包的延迟,但简单共享同一个累加器的背靠背乘法指令除外,它们不会有任何延迟。
长延时指令是所有的加载、乘法和浮点运算指令。例如,以下指令序列会出现延迟:
{ R2=mpy(R0.L,R0.L) }
// one-cycle stall
{ R3=mpy(R2.L,R2.L) }
...{ R2 = memw(R1) }
// one-cycle stall
{ R3=mpy(R2.L,R2.L) }
但这个指令序列并没有停滞:
{ R2=mpy(R0.L,R0.L) }
{ R2+=mpy(R1.L,R1.L) } // no stall
4.2.2.1.3 HVXlatencies
Hexagon V66 HVX 程序员参考手册(80-N2040-44)的指令延迟部分讨论了延迟问题。在这一节中,我们将讨论最常见的导致停顿的HVX算术指令序列,您应该了解这些指令。
需要记住的最常见的停滞原因是当下面的指令消耗在前一个数据包中产生的结果时出现的单包延迟。
**1.**乘法(但是,只共享同一个累加器的背对背乘法不会停滞)
**2.**移位和置换操作
指令延迟部分提供了这些规则的一些例子。
{ V8 = VADD(V0,V0) }
{ V0 = VADD(V8,V9) }
{ V1 = VMPY(V0,R0) }
{ V2 = VSUB(V2,V1) }
{ V5:4 = VUNPACK(V2) }
{ V2 = VADD(V0,V4) }
// NO STALL
// STALL due to V0
// NO STALL on V1
// STALL due to V2
// NO STALL on V4














 7143
7143











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









