







一、抽象
1)在Tutorial中,介绍了基于HetCompute编程模型下,实现CPU、GPU、DSP分别对数组进行运算,以及协同工作对数组信息进行处理。
二、实现过程
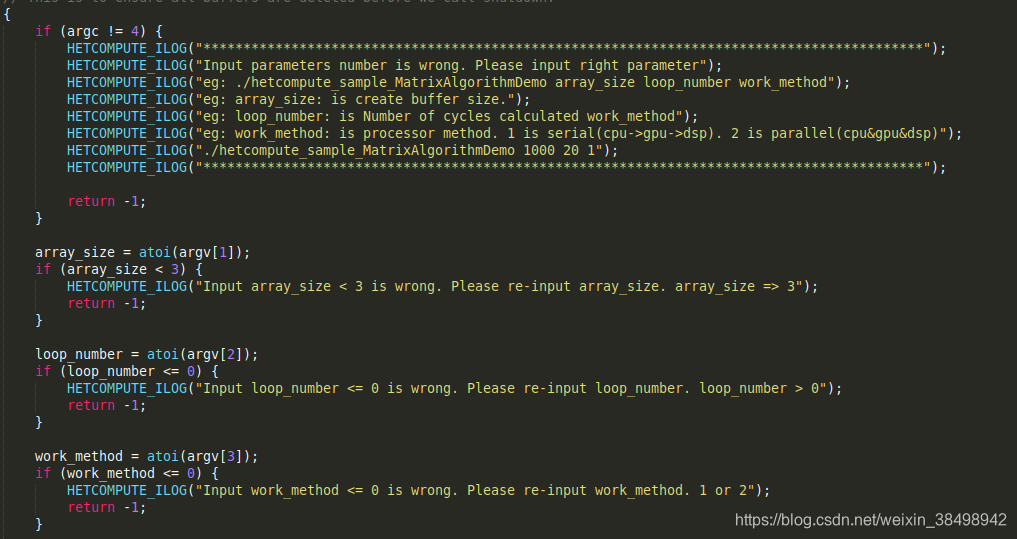 此处为main函数的命令行参数实现部分。通过这几个参数实现了对数组规模、循环次数和实现方法的自定义。实现方法有CPU、GPU、DSP协同工作模式和独立工作模式。
此处为main函数的命令行参数实现部分。通过这几个参数实现了对数组规模、循环次数和实现方法的自定义。实现方法有CPU、GPU、DSP协同工作模式和独立工作模式。
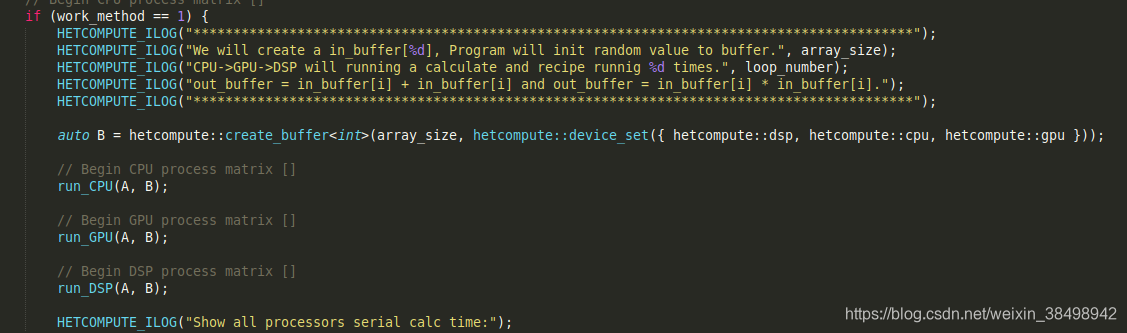 此处定义的为独立工作模式,通过 Hetcompute SDK提供的API申请的bufferr,然后通过自定义函数调用其相对应的数组处理。
此处定义的为独立工作模式,通过 Hetcompute SDK提供的API申请的bufferr,然后通过自定义函数调用其相对应的数组处理。
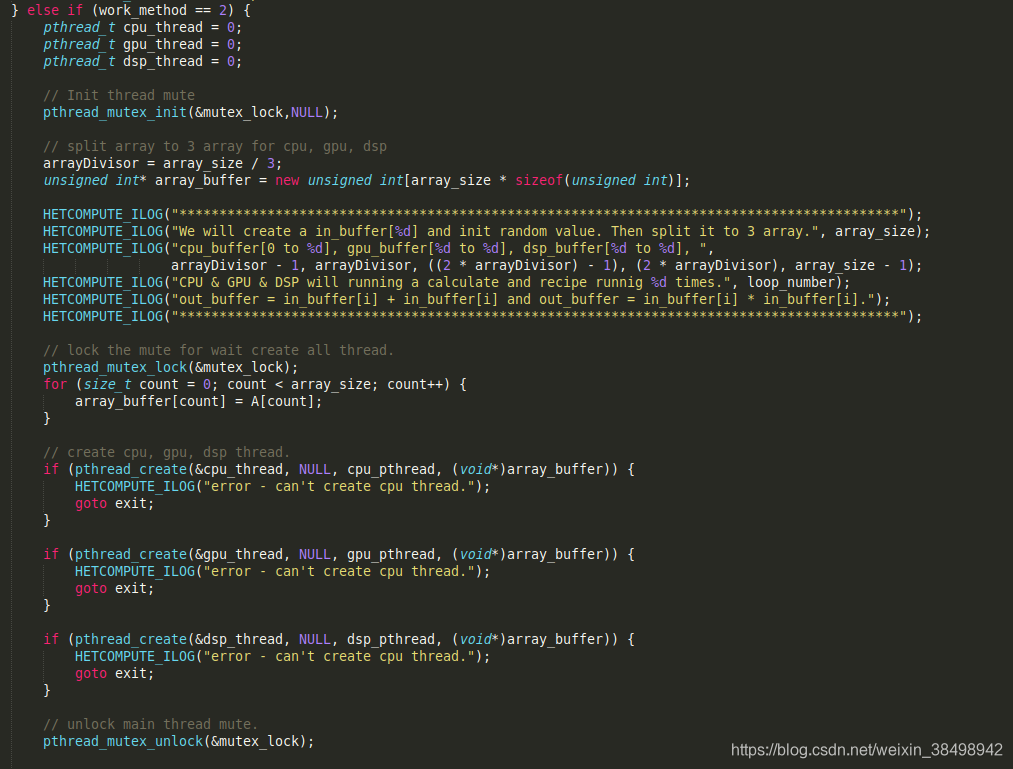 此处为协同工作模式的定义,将原是数组分割成三份,并对其进行处理。通过多线程CPU、GPU、DSP同时运行,并最终返回它们各自所消耗的时间,与上面的输出进行对比。传参部分传入线程的参数为未分割前数组的大小。
此处为协同工作模式的定义,将原是数组分割成三份,并对其进行处理。通过多线程CPU、GPU、DSP同时运行,并最终返回它们各自所消耗的时间,与上面的输出进行对比。传参部分传入线程的参数为未分割前数组的大小。
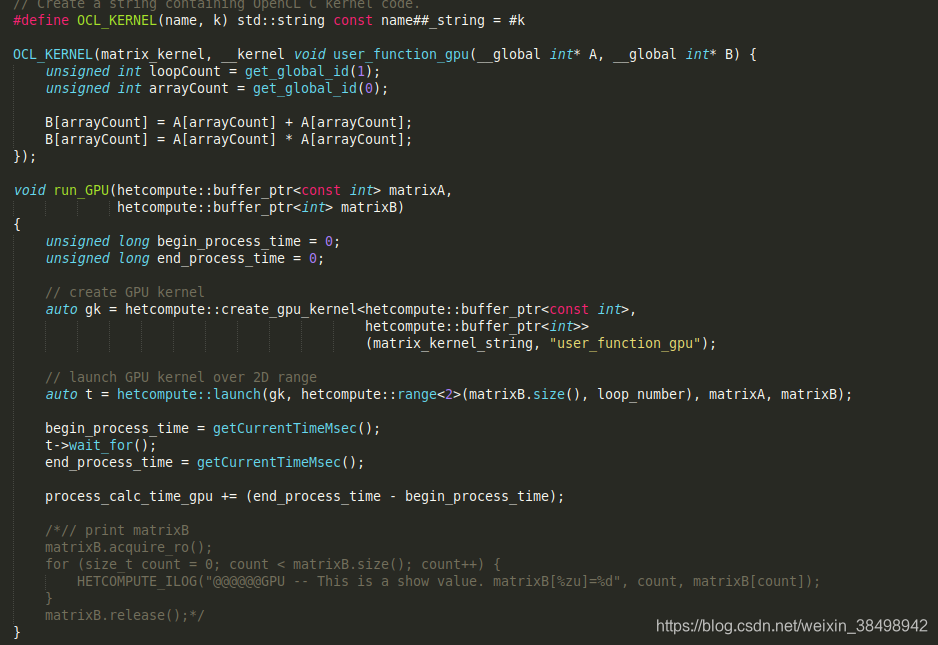 以上为GPU的处理部分,对数组元素进行了自加和自乘运算,t->wait_for()可以理解为自旋锁,只有当launch完成时,才继续进行下一步,利用这个机制实现了对工作总时间的计算。通过create_gpu_kernel将计算部分加入函数中,最终通过lauch传参实现。此机制广泛的应用于任务调度之中,可以有效地保证任务执行过程的安全。
以上为GPU的处理部分,对数组元素进行了自加和自乘运算,t->wait_for()可以理解为自旋锁,只有当launch完成时,才继续进行下一步,利用这个机制实现了对工作总时间的计算。通过create_gpu_kernel将计算部分加入函数中,最终通过lauch传参实现。此机制广泛的应用于任务调度之中,可以有效地保证任务执行过程的安全。
DSP部分实现相对比较复杂,需要将实现函数封装在dsp.h中,然后再通过python脚本将其生成.so文件,放入手机/ventor/下,在此处再通过HetCompute SDK提供的任务机制将其加载,最终实现对数组进行处理。它的实现过程中调用的是头文件所dsp.h包含的一个函数,也就是上面提到的已经被加载进入手机端.so库中内容。
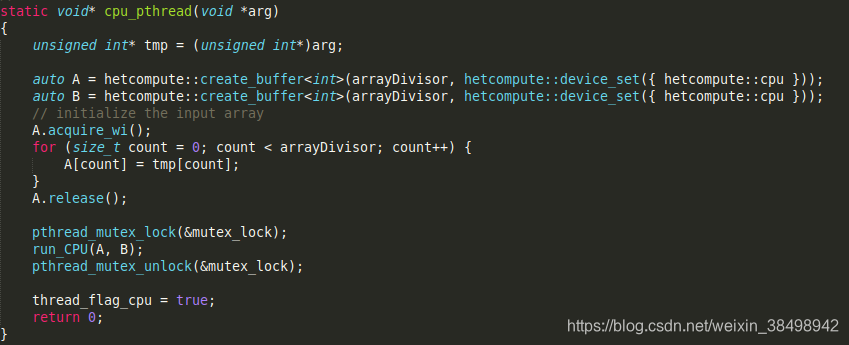 此处执行的为并行任务,对临界资源的保护使用到了acquire_wi()和 release(),类似于锁的机制,专门应对HetCompute下所申请的缓冲区,对分割后的数组进行初始化。接下来通过锁的机制来调用上面实现的函数来对数组进行操作。上面线程操作中都是用到了这些函数。
此处执行的为并行任务,对临界资源的保护使用到了acquire_wi()和 release(),类似于锁的机制,专门应对HetCompute下所申请的缓冲区,对分割后的数组进行初始化。接下来通过锁的机制来调用上面实现的函数来对数组进行操作。上面线程操作中都是用到了这些函数。
CPU、DSP部分与此处实现类似,对临界资源的保护此处提供的机制相当完善。最后通过返回值的&&运算保证了所有线程执行完成,并最终打印出各个部分所消耗的时间。
三、实验结果分析
 此处为独立完成时各部分所消耗的时间,可以看到CPU和GPU所需时间并不是很多,而DSP消耗了相对大量的时间,对资源来说比较浪费。
此处为独立完成时各部分所消耗的时间,可以看到CPU和GPU所需时间并不是很多,而DSP消耗了相对大量的时间,对资源来说比较浪费。
 此处为协同工作下各部分所消耗的时间,CPU和GPU的差别不是很大,DSP部分则整整节约了近一半的时间,这在大型工程中可以说是节约了相当大量的资源。
此处为协同工作下各部分所消耗的时间,CPU和GPU的差别不是很大,DSP部分则整整节约了近一半的时间,这在大型工程中可以说是节约了相当大量的资源。














 2452
2452











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









