









文章目录
1. 前言
在读Abstract的时候我觉得这篇文章挺有趣、挺创新的,本文的方法加入了STN变形矫正,先矫正后检测,而且端到端可训练。RARE这名字也中二得很…
RARE(具有自动校正功能的鲁棒性文本识别器)是由**空间变形网络(STN)和序列识别网络(SRN)**组成。在测试中,首先通过predicted Thin-Plate-Spline(TPS)对图像进行校正,为后续的SRN(通过序列识别方法识别文本)生成更“可读”的图像。
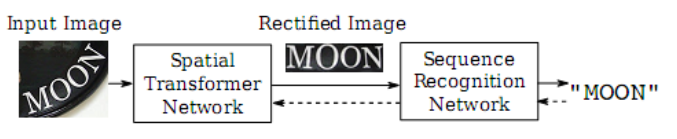
RARE示意图,先把曲线文本经过STN变换成水平的,再识别。
2. 实现
2.1 STN
STN结构:定位网络定位一组基准点C,网格生成器生成一个采样网格p,采样器产生一个校正后的图像
I
′
{I}'
I′,已知I和P。
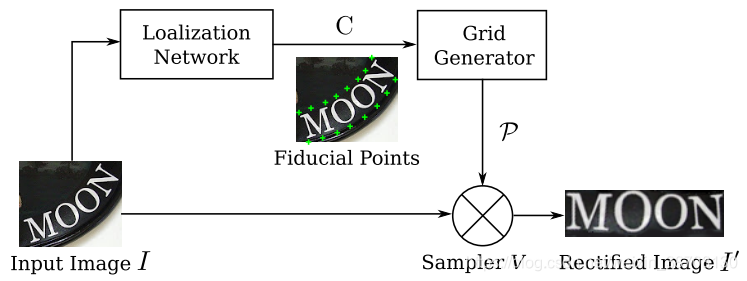 STN的独特之处在于其采样器是可微分的。 因此,一旦我们有一个可微的定位网络和一个可微的网格发生器,STN在训练时就可以通过误差进行反向传播。
STN的独特之处在于其采样器是可微分的。 因此,一旦我们有一个可微的定位网络和一个可微的网格发生器,STN在训练时就可以通过误差进行反向传播。
2.1.1 定位网络
定位网络可以直接回归出K个基准点的x,y坐标。这里,常数K是基准点的个数,一般是偶数。K个基准点的坐标用C表示,C =[ c 1 c_{1} c1,… , c K c_{K} cK]∈ R 2 x K R^{2xK} R2xK,其中第k列 c k c_{k} ck表示第k个基准点的坐标, c k c_{k} ck = [ x k x_{k} xk , y k y_{k} yk],即,每个基准点由x和y坐标两维数据组成。这里使用归一化的坐标系,坐标系的原点是原始图像的中心。这样一来,x,y都在[-1,1]的范围内。
使用卷积神经网络(CNN)进行回归(而非分类)。 因此,最后的一个全连接层的输出节点的数量需要设置为2K,将激活函数设置为 t a n h ( ⋅ ) tanh(\cdot ) tanh(⋅),使得输出向量值的范围为(-1,1)。 最后,将输出向量reshape为C。
定位网络会基于全局图像的上下文来定位基准点。 网络会捕获输入图像的整体文本形状,然后相应地定位出基准点。这里,应该强调的是,我们不用为任何样本标注基准坐标点。因为定位网络的训练是由STN的其他部分完全监督的,其他部分会遵循反向传播算法将梯度传播到定位网络中。
2.1.2 网格生成器
网格生成器会根据基准点计算TPS变换的参数并生成采样网格。先定义另一组基准点,称为基本基准点,表示为C’ =[
c
1
′
c_{1}'
c1′,… ,
c
K
′
c_{K}'
cK′]∈
R
2
x
K
R^{2xK}
R2xK。基本基准点均匀分布在校正后的图像I’的顶部和底部边缘。 因为K是一个常数,坐标系也被归一化了,因此C’也总是一个常数。
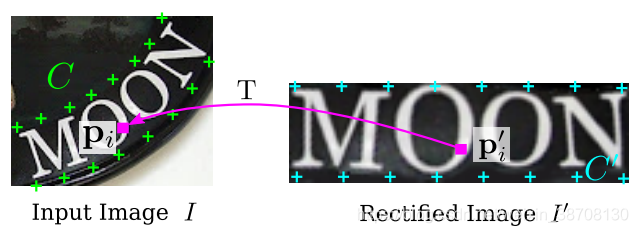
C(绿色×)就是基本基准点,C’(蓝色×)是校正后的基准点。
TPS变换的参数用矩阵T表示,T∈
R
2
x
(
K
+
3
)
R^{2x(K + 3)}
R2x(K+3),T的计算方式如下:
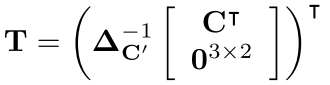
这里
c
′
∈
R
(
K
+
3
)
x
(
K
+
3
)
c' \in R^{(K + 3)x(K + 3)}
c′∈R(K+3)x(K+3),它是一个常量,唯一只取决于C’矩阵。C’矩阵也是常量。
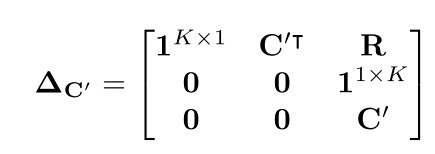
这里R是K行,K列的。第i 行,第j列的元素用
r
i
,
j
r_{i,j}
ri,j表示。
r
i
,
j
=
d
i
,
j
2
ln
d
i
,
j
2
r_{i,j} = \ d_{i,j}^{2}\ln d_{i,j}^{2}
ri,j= di,j2lndi,j2,这里
d
i
,
j
d_{i,j}
di,j是
c
i
′
c_{i}^{'}
ci′和
c
j
′
c_{j}^{'}
cj′的欧氏距离。
C的维度是2xK,R的维度是KxK, 因此, c ′ _{c'} c′的维度为(K+3)x(K+3),T维度为2x(K+3)。
用P’表示校正后图像I’的像素的网格,P’={
p
i
′
p_{i}^{'}
pi′},其中i=1,2,3,。。。N。这里
p
i
′
=
[
x
i
′
,
y
i
′
]
T
p_{i}^{'} = {\lbrack x_{i}^{'},y_{i}^{'}\rbrack}^{T}
pi′=[xi′,yi′]T ,x,y为第i个像素的坐标,N为校正后图像的像素的总个数。如图3所示。对于图像I’上的每个像素
p
i
′
p_{i}^{'}
pi′,我们都能通过下面的变换,在原图像I中找到对应的像素
p
i
p_{i}
pi,其中
p
i
p_{i}
pi=
[
x
i
,
y
i
]
T
{\lbrack x_{i},y_{i}\rbrack}^{T}
[xi,yi]T。
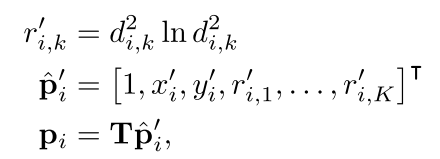
d
i
,
k
d_{i,k}
di,k是
p
i
′
p_{i}^{'}
pi′和第k个基本基准点
c
k
′
c_{k}^{'}
ck′的欧氏距离。通过对P’所有的像素点进行迭代,我们就能在输入图像I上生成一个网格P={
p
i
p_{i}
pi},其中i=1,2,3,…,N。
因为上面的公式1和公式4都是可微分的,是两个矩阵相乘,因此这个网格生成器可以反向传播梯度。
2.1.3 采样器
采样器会将输入图像在
p
i
p_{i}
pi附近的像素进行双线性插值,插值后的结果就是校正后图像
p
i
′
p_{i}^{'}
pi′的像素值。采样器对所有的像素进行上述操作,就可以得到校正后图像I’。
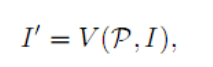
这里V表示双线性采样器,它同样是一个可以微分的模块。

如上图所示是STN的效果。(a)松散有限的文字; (b)多方向文本;(c)透视文本; (d)曲线文字。
2.2 SRN
由于目标词是固有的字符序列,因此可以把识别问题当做序列识别问题进行建模。SRN网络的输入就是前面校正过的图像I’。理想状态下,I’是一幅只包含一个单词的的图像,并且单词是从左向右水平书写的。从图像I’中提取相应的序列特征,然后再基于这些序列特征去识别文字。
识别模型是一个基于注意力的模型,可以直接从输入图像中识别出一个序列的文字。SRN包含了编码模块和解码模块。编码模块从校正过的图像I’ 中提取一个序列特征。解码模块会根据前面的序列特征,循序地生成输出序列。
下图所示是SRN的结构图:
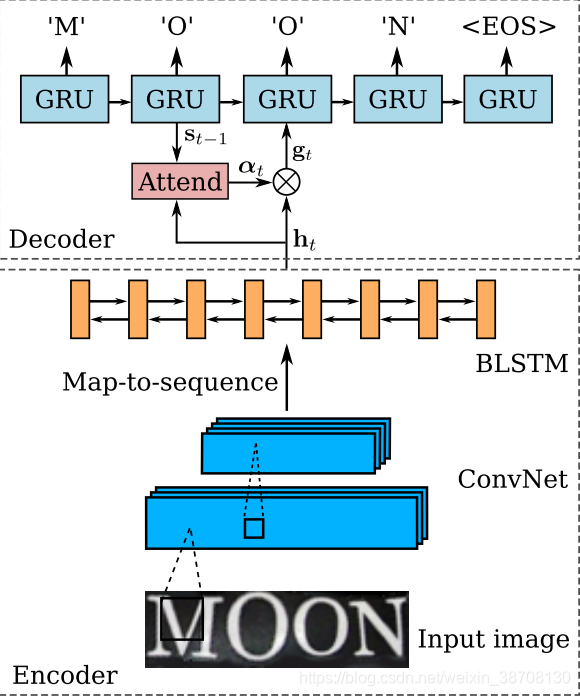
2.2.1 编码:卷积循环网络
RARE的编码器由一个7层的CNN和一个两层的双向LSTM组成。
CNN:可以得到输入图像中比较鲁棒的,比较高级的特征图。这里会将这些特征图转化成一个序列,序列的长度就是特征图的宽度。这样一来,我们就得到了按照从左到右的顺序排列的特征向量。
B-LSTM:在两个方向上分析一个序列的独立性,并输出另一个同样长度的序列,h={h1,h2,…hl}。
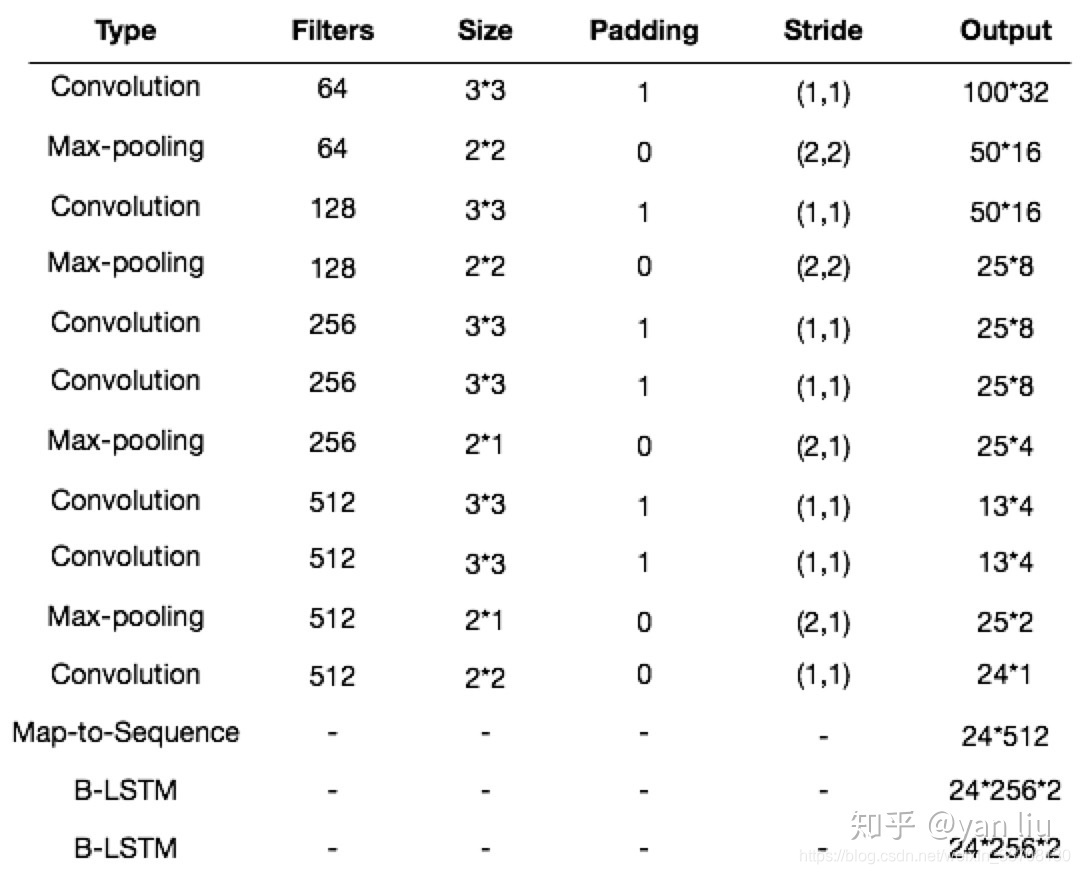
2.2.2 解码:循环字符生成器
Decoder是基于单向GRU的序列模型,其在第 t 个时间片的特征 s t \mathbf{s}_t st 表示为:
s t = GRU ( l t − 1 , g t , s t − 1 ) \mathbf{s}_t = \text{GRU}(l_{t-1}, \mathbf{g}_t, s_{t-1}) st=GRU(lt−1,gt,st−1)
其中 t=[1,2,…,T] , T 是输出标签的长度。
在训练时, l t − 1 l_{t-1} lt−1是第 t 个时间片的标签,在测试时则是第 t 个时间片的预测结果。 g t \mathbf{g}_t gt
是Attention的一个叫做glimpse的参数,从数学上理解是特征 h \mathbf{h} h 的各个时间片的特征的加权和:g t = ∑ i = 1 L α t i h i g_t = \sum_{i=1}^L \alpha_{ti}\mathbf{h}_i gt=i=1∑Lαtihi
α t i = e x p ( t a n h ( s i − 1 , h t ) ) ∑ k = 1 T e x p ( t a n h ( s i − 1 , h k ) ) \alpha_{ti} = \frac{exp(tanh(s_{i-1}, \mathbf{h}t))}{\sum_{k=1}^T exp(tanh(s_{i-1}, \mathbf{h}_k))} αti=∑k=1Texp(tanh(si−1,hk))exp(tanh(si−1,ht))
RARE的输出向量有37个节点,包括26个字母+10个数字+1个终止符,输出层使用 softmax 做激活函数,每个时间片预测一个值:
y ^ t = s o f t m a x ( W T s t ) \hat{\mathbf{y}}_t = softmax(\mathbf{W}^Ts_t) y^t=softmax(WTst)
2.3 训练
文章中的训练数据为800万的合成样本数据,输入图像均resize到100×32,STN的输出size也是100×32。
损失函数:
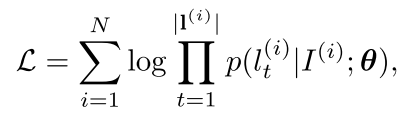
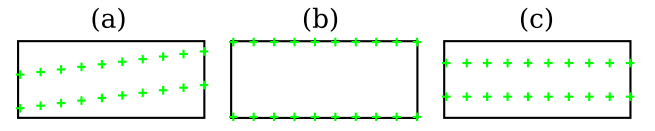
初始基准点设置成(a)得到的效果最好。
3. 测试
3.1 STN网络:
STN的定位网络有4个卷积层,每个卷积层后面是一个22的max pooling层。所有的卷积层中,卷积核的大小为33,填充的pad为1,stride为1。4个卷积层中卷积核的个数依次为64,128,256,512。在这4个卷积层和4个max pooling层后是两个全连接层,全连接层的隐藏单元个数1024。这里,我们设置基准点的个数K为20。这就意味着定位网络的输出应该是一个40维的向量。这里除了输出层外,所有层的激活函数为RELU函数。输出层的输出函数为tanh(.)。这样以来,保证了输出的基准点都在(-1,1)之间。
3.2 STN网络:
SRN网络:编码部分有7个卷积层,这些卷积层的卷积核大小,卷积核个数,stride,pading size依次为{3,64,1,1},{3,128,1,1},{3,256,1,1},{3,256,1,1},{3,512,1,1},{3,512,1,1}和{3,512,1,0}。在第一层,第二层,第四层和第六层的卷积层后面都有一个2*2的max pooling层。在卷积层的之后,是一个两层的双向LSTM网络。每个LSTM单元中有256个隐藏单元。解码部分,我们用了GRU单元,每个单元中有256个记忆块和37个输出单元(26个字母,10个数字,还有1个EOS标识)。
3.3 模型训练:
模型是在800万的合成数据上训练的。训练时的batch size为64。在训练和测试时,图像首先被resize为10032。SNT的输出仍然为10032。在训练时,我们的模型每秒能处理160多个样本。在整个训练数据集上训了了3个回合,大致需要2天。
3.4 实现:
模型是在torh7框架下实现的。绝大部分模块都使用了GPU加速。CPU为Intel Xeon(R),2.40GHz, GPU为NVIDIA GTX-Titan,RAM为64G。
不使用字典时,识别一张图片的文字需要的时间不到2ms。如果使用字典,识别的速度依赖于字典的大小。如果字典的的单词总数小于1000,我们使用精确搜索。如果字典的单词总数更大一些,我们就使用近似的模糊搜索,其中模糊的宽度为7。经测试,如果字典大小为五万个单词,一幅图像的搜索大致需要200ms。
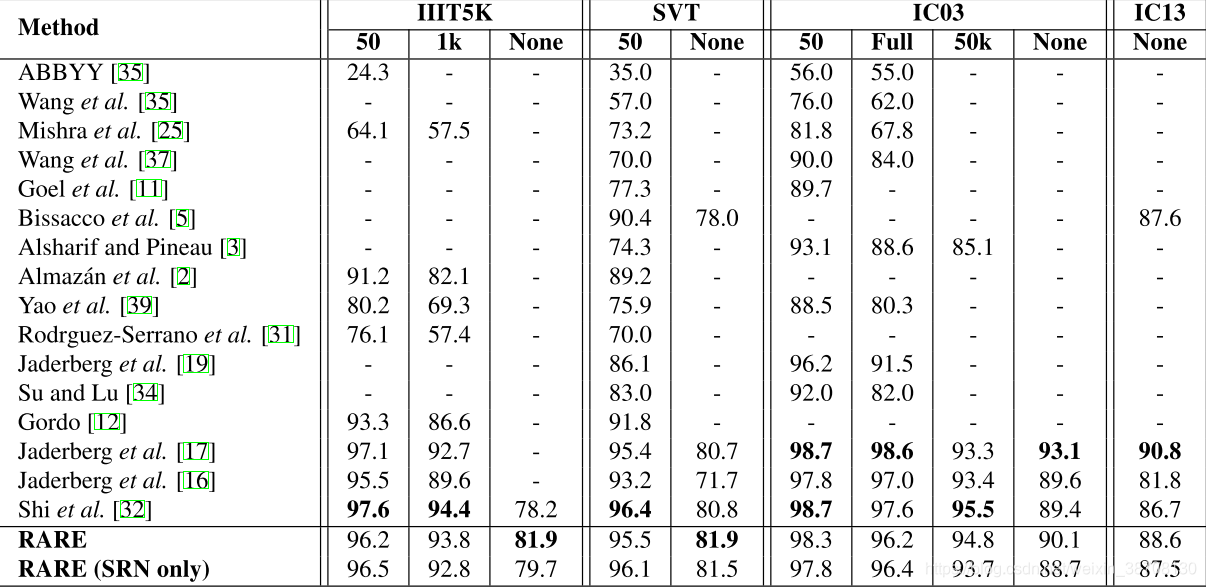
上表是本文方法和其他方法的评估结果。不使用字典时,在III5K上,RARE比CRNN高出了将近4个百分点。因为III5K的数据集中包含了一些不规则的文本,特别是弯曲的文本,所以RARE在处理这些文本时,有明显的优势。
如果使用了字典,RARE也达到了较高的准确率,比CRNN略低一点点。
还训练了一个只有SRN的模型,这个模型在大部分的benchmark上,也达到了较高的准确率,是个相当有竞争力的模型。
4. 总结
使用STN+SRN,可以很好地处理弯曲、透视等文本。
但是挺复杂的,还找不着源码,从入门到放弃…
5. 参考文献
1.《Robust Scene Text Recognition with Automatic Rectification》
2.论文翻译
3.https://blog.csdn.net/rabbithui/article/details/78853649
4.https://zhuanlan.zhihu.com/p/43054073














 6695
6695











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









