







# 总核数 = 物理CPU个数 X 每颗物理CPU的核数
# 总逻辑CPU数 = 物理CPU个数 X 每颗物理CPU的核数 X 超线程数
梳理一下Spark中关于并发度涉及的几个概念File,Block,Split,Task,Partition,RDD以及节点数、Executor数、core数目的关系。
输入可能以多个文件的形式存储在HDFS上,每个File都包含了很多块,称为Block。
当Spark读取这些文件作为输入时,会根据具体数据格式对应的InputFormat进行解析,一般是将若干个Block合并成一个输入分片,称为InputSplit,注意InputSplit不能跨越文件。
随后将为这些输入分片生成具体的Task。InputSplit与Task是一一对应的关系。
随后这些具体的Task每个都会被分配到集群上的某个节点的某个Executor去执行。
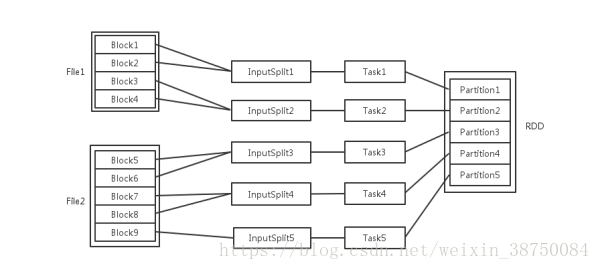
- 每个节点可以起一个或多个Executor。
- 每个Executor由若干core组成,每个Executor的每个core一次只能执行一个Task。
- 每个Task执行的结果就是生成了目标RDD的一个partiton。
注意: 这里的core是虚拟的core而不是机器的物理CPU核,可以理解为就是Executor的一个工作线程。
而 Task被执行的并发度 = Executor数目 * 每个Executor核数。
至于partition的数目:
- 对于数据读入阶段,例如sc.textFile,输入文件被划分为多少InputSplit就会需要多少初始Task。
- 在Map阶段partition数目保持不变。
- 在Reduce阶段,RDD的聚合会触发shuffle操作,聚合后的RDD的partition数目跟具体操作有关,例如repartition操作会聚合成指定分区数,还有一些算子是可配置的。
Spark集群的节点个数为集群的机器的数量。一个机器上有几个worker,一个woker可以申请多少core是可配置的。一个常用的配置是:
一台机器一个worker,一个woker可拥有的最大core数是机器逻辑cpu的数量。
在这种情况下,一个core就可以理解为一台机器的一个逻辑核。
而RDD的分区个数决定了这个RDD被分为多少片(partition)来执行,一个片给一个Core。
假设有一个10台机器的集群,每台机器有8个逻辑核,并按照如上的配置,那么这个spark集群的可用资源是 80个core(这里只考虑cpu,实际上还有内存)。如果一个任务申请到了集群的所有资源(所有80个core)。现在有一个被分为100个partition的RDD被map执行,那么会同时启动80个Task也就是占用了所有80个core计算(实际是启动了80个线程),剩余20个partition等待某些task完成后继续执行。
当然理论上可以给一台机器配置更多的worker和core,即使实际上机器只有80个逻辑核,但是你总共配置100个core,就可以同时跑起来100个partition了( no zuo no die )














 164
164











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









