







公众号后台回复“图书“,了解更多号主新书内容
作者:livan
来源:数据python与算法
spark on yarn架构有两种模式,分为Yarn-client模式和Yarn-cluster模式,本文与大家一起了解一下这两种模式:
Yarn-client模式


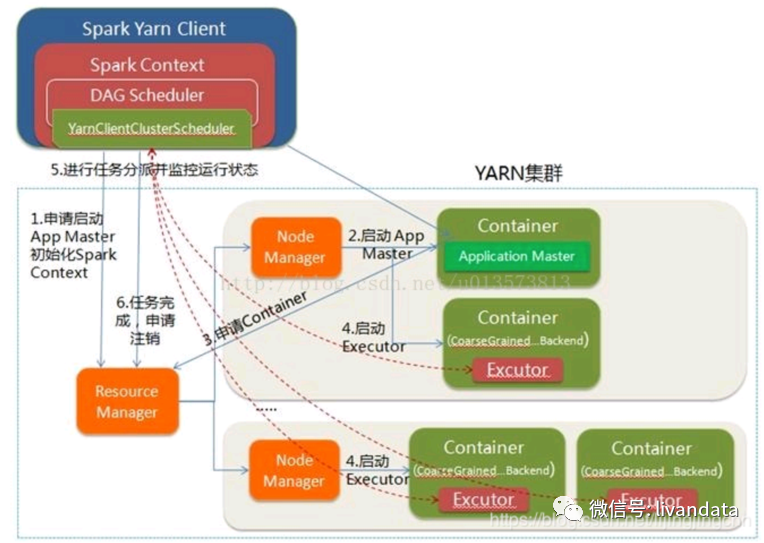
运行流程为:
1)Spark Yarn Client向YARN的ResourceManager申请启动Application Master。同时在SparkContent初始化中将创建DAGScheduler和TASKScheduler等,由于我们选择的是Yarn-Client模式,程序会选择YarnClientClusterScheduler和YarnClientSchedulerBackend;
2)ResourceManager收到请求后,在集群中选择一个NodeManager,为该应用程序分配第一个Container,要求它在这个Container中启动应用程序的ApplicationMaster,与YARN-Cluster区别的是在该ApplicationMaster不运行SparkContext,只与SparkContext进行联系进行资源的分派;
3)Client中的SparkContext初始化完毕后,与ApplicationMaster建立通讯,向ResourceManager注册,根据任务信息向ResourceManager申请资源(Container);
4)一旦ApplicationMaster申请到资源(也就是Container)后,便与对应的NodeManager通信,要求它在获得的Container中启动CoarseGrainedExecutorBackend,CoarseGrainedExecutorBackend启动后会向Client中的SparkContext注册并申请Task;
5)Client中的SparkContext分配Task给CoarseGrainedExecutorBackend执行,CoarseGrainedExecutorBackend运行Task并向Driver汇报运行的状态和进度,以让Client随时掌握各个任务的运行状态,从而可以在任务失败时重新启动任务;
6)应用程序运行完成后,Client的SparkContext向ResourceManager申请注销并关闭自己;
Yarn-cluster模式


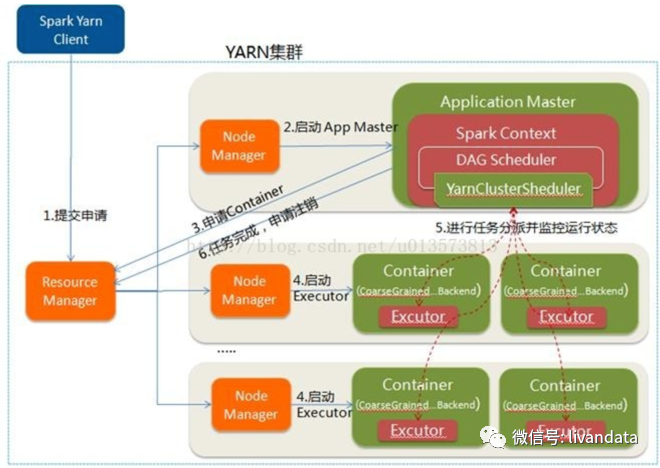
运行流程为:
1)Spark Yarn Client向YARN中提交应用程序,包括ApplicationMaster程序、启动ApplicationMaster的命令、需要在Executor中运行的程序等;
2)ResourceManager收到请求后,在集群中选择一个NodeManager,为该应用程序分配第一个Container,要求它在这个Container中启动应用程序的ApplicationMaster,其中ApplicationMaster进行SparkContext等的初始化;
3)ApplicationMaster向ResourceManager注册,这样用户可以直接通过ResourceManager查看应用程序的运行状态,然后它将采用轮询的方式通过RPC协议为各个任务申请资源,并监控它们的运行状态直到运行结束;
4)一旦ApplicationMaster申请到资源(也就是Container)后,便与对应的NodeManager通信,要求它在获得的Container中启动
CoarseGrainedExecutorBackend,CoarseGrainedExecutorBackend启动后会向ApplicationMaster中的SparkContext注册并申请Task。这一点和Standalone模式一样,只不过SparkContext在Spark Application中初始化时,使用CoarseGrainedSchedulerBackend配合YarnClusterScheduler进行任务的调度,其中YarnClusterScheduler只是对TaskSchedulerImpl的一个简单包装,增加了对Executor的等待逻辑等;
5)ApplicationMaster中的SparkContext分配Task给CoarseGrainedExecutorBackend执行,CoarseGrainedExecutorBackend运行Task并向ApplicationMaster汇报运行的状态和进度,以让ApplicationMaster随时掌握各个任务的运行状态,从而可以在任务失败时重新启动任务;
6)应用程序运行完成后,ApplicationMaster向ResourceManager申请注销并关闭自己;
在Spark作业运行过程中,一般情况下会有大量数据在Driver和集群中进行交互,所以如果是基于yarn-client的模式,则会在程序运行过程中产生大量的网络数据传输,造成网卡流量激增;而基于yarn-cluster这种模式,因为driver本身就在集群内部,所以数据的传输也是在集群内部来完成,那么网络传输压力相对要小;所以在企业生产环境下多使用yarn-cluster这种模式,测试多用yarn-client这种模式。
◆ ◆ ◆ ◆ ◆麟哥新书已经在当当上架了,我写了本书:《拿下Offer-数据分析师求职面试指南》,目前当当正在举行活动,大家可以用相当于原价5折的预购价格购买,还是非常划算的:
数据森麟公众号的交流群已经建立,许多小伙伴已经加入其中,感谢大家的支持。大家可以在群里交流关于数据分析&数据挖掘的相关内容,还没有加入的小伙伴可以扫描下方管理员二维码,进群前一定要关注公众号奥,关注后让管理员帮忙拉进群,期待大家的加入。
管理员二维码:
猜你喜欢
● 卧槽!原来爬取B站弹幕这么简单● 厉害了!麟哥新书登顶京东销量排行榜!● 笑死人不偿命的知乎沙雕问题排行榜
● 用Python扒出B站那些“惊为天人”的阿婆主!● 你相信逛B站也能学编程吗















 5092
5092











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









